
平台系统模型管理
1. 模型配置
参考模型管理
2. 模型定价
注:模型定价要生效必须开启订阅与积分功能
当在模型配置中添加模型完成后,就可以在模型定价中进行模型定价,定价完成后,用户就可以在模型市场中订阅模型了。
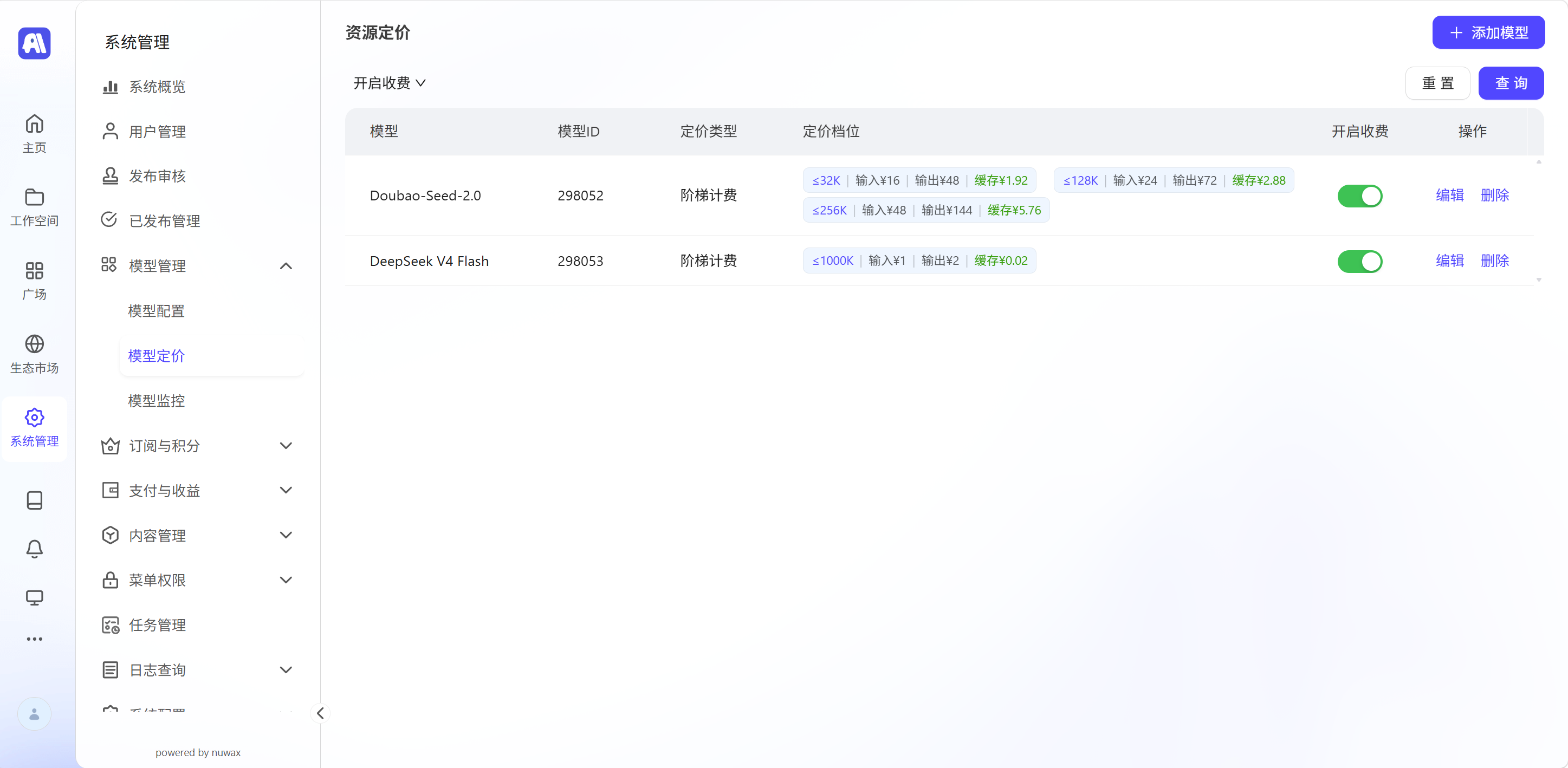
2.1 定价列表页
- 列表字段:模型名称、模型ID、定价类型、定价档位、开启收费状态、操作按钮
- 筛选功能:支持按「开启收费」状态筛选模型
- 操作按钮:
- 编辑:修改模型的定价档位与费用
- 删除:移除模型的定价配置
- 全局开关:「开启收费」总开关,控制单模型计费功能是否生效
2.2 添加模型定价
点击右上角「+ 添加模型」按钮,弹出配置窗口,需填写以下信息:
| 字段 | 必填 | 说明 |
|---|---|---|
| 模型 | ✅ | 选择已在「模型配置」中添加的平台级公共模型 |
| 定价档位 | ✅ | 支持多档位阶梯计费,按上下文长度区间划分(单位:K) |
| 输入费用 | ✅ | 该档位下输入Token单价,单位:元/百万Token |
| 输出费用 | ✅ | 该档位下输出Token单价,单位:元/百万Token |
| 缓存费用 | ✅ | 该档位下缓存Token单价,单位:元/百万Token |
多档位配置:可点击「添加档位」新增阶梯区间(如≤32K、≤128K、≤256K等),每个档位可独立设置输入/输出/缓存费用
保存规则:配置完成后点击「确认」,定价规则即时生效
示例1: 以 Deepseek 为例,其定价档位与费用如下:
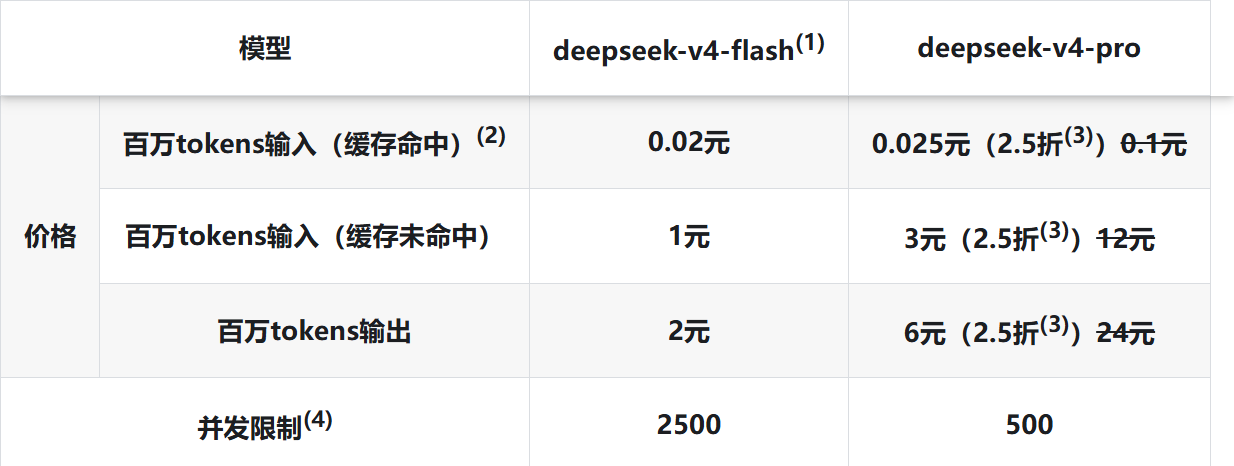 由于V4没有阶梯价我们就可以设置一档即可:
由于V4没有阶梯价我们就可以设置一档即可: 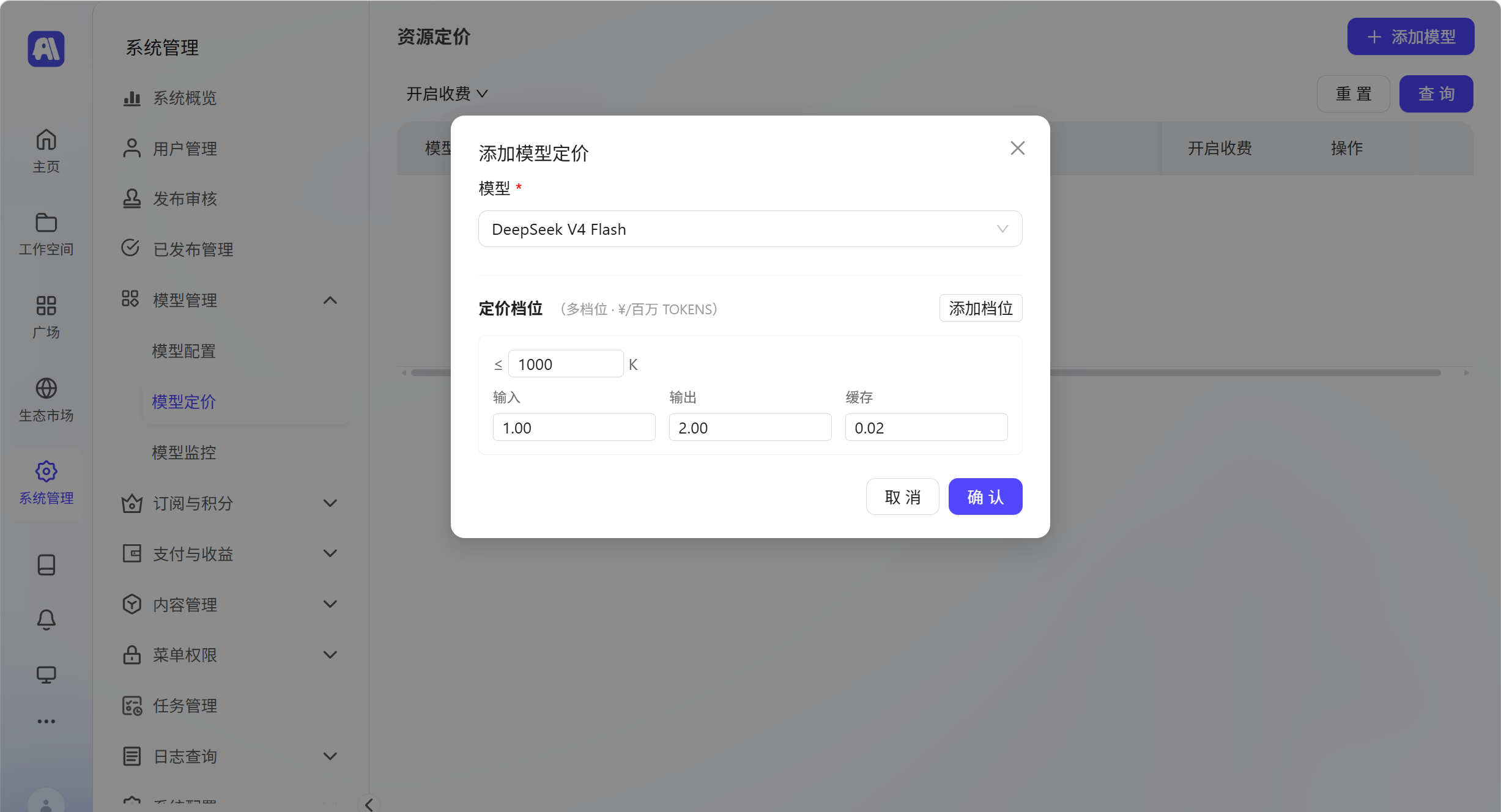 计费计算公式如下:text
计费计算公式如下:text输入费用 = 实际输入 Token 数 ÷ 1,000,000 × 输入单价 输出费用 = 实际输出 Token 数 ÷ 1,000,000 × 输出单价 缓存费用 = 命中缓存的 Token 数 ÷ 1,000,000 × 缓存单价 总费用 = 输入费用 + 输出费用 + 缓存费用 假设本次调用数据如下: 实际输入 Token 数:500,000 实际输出 Token 数:200,000 命中缓存的 Token 数:100,000 分步计算: 输入费用:(500,000 ÷ 1,000,000 × 1.00 = 0.50元) 输出费用:(200,000 ÷ 1,000,000 × 2.00 = 0.40元) 缓存费用:(100,000 ÷ 1,000,000 × 0.02 = 0.002元) 总费用:(0.50 + 0.40 + 0.002 = 0.902元)示例2:以 Doubao-Seed-2.0 为例,其定价档位与费用如下:
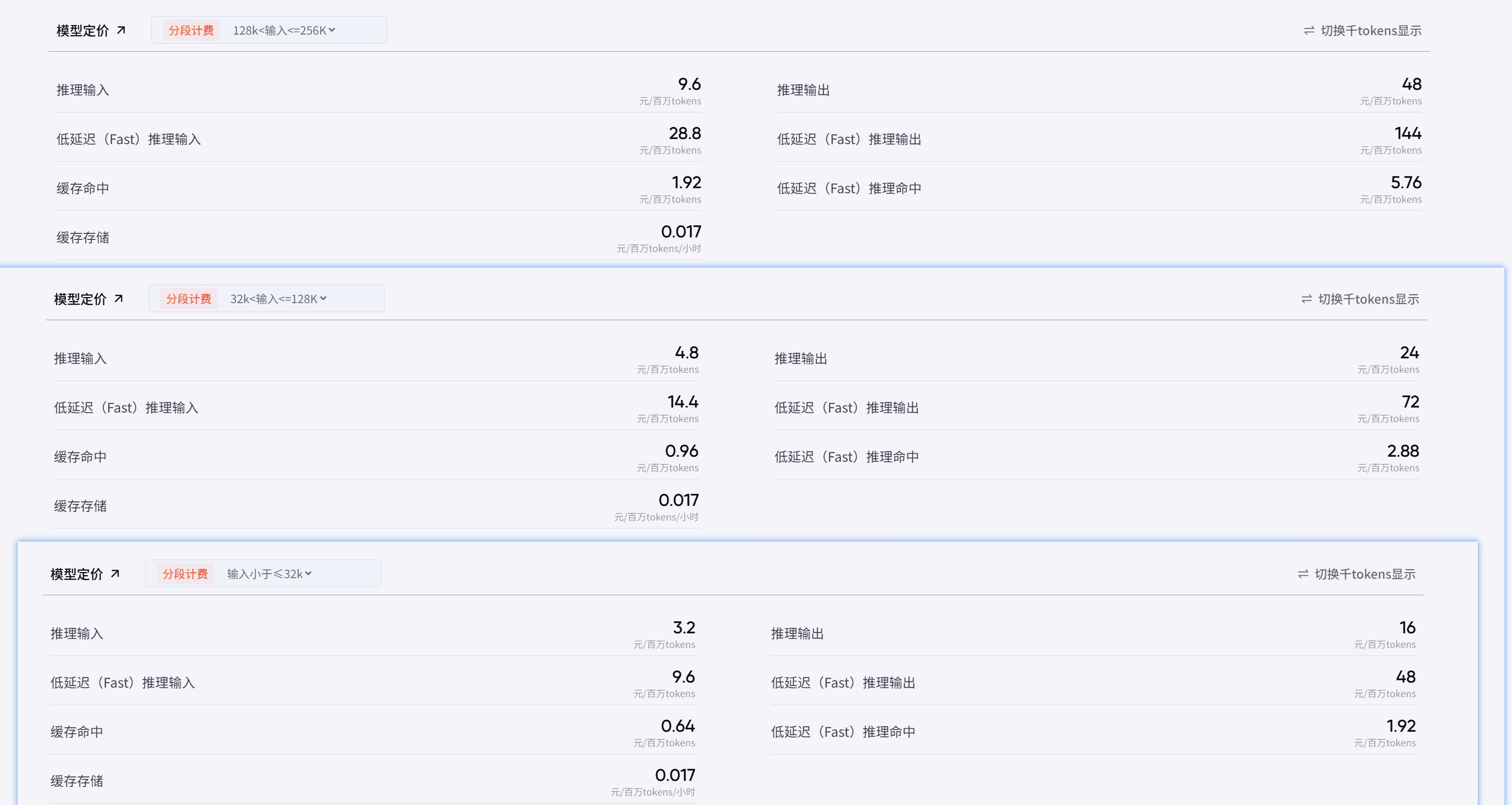 根据阶梯价,我们可以设置如下:
根据阶梯价,我们可以设置如下: 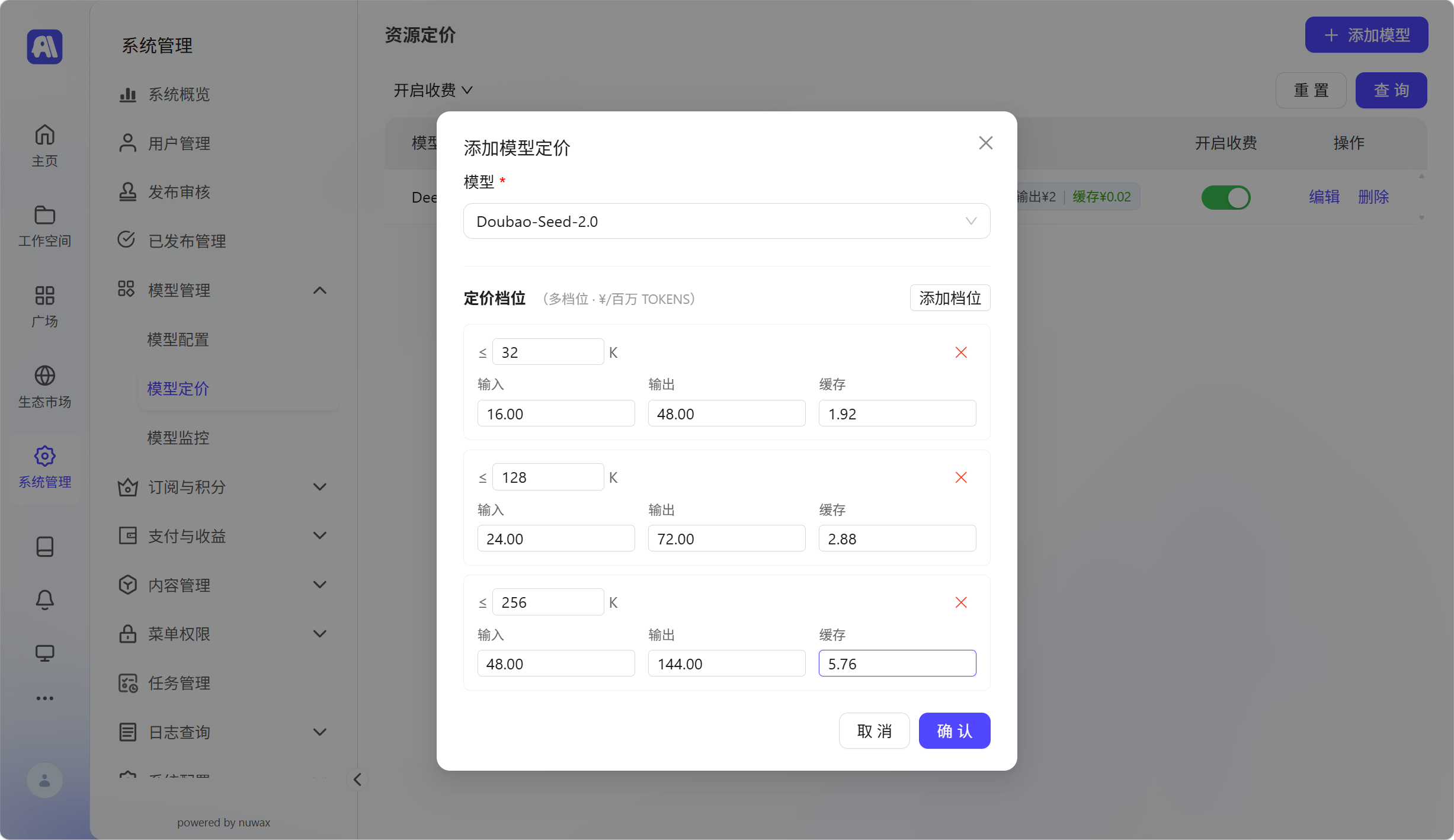
计费计算公式如下:
text# 通用公式(适用于所有档位) 输入费用 = 实际输入 Token 数 ÷ 1,000,000 × 对应档位的输入单价 输出费用 = 实际输出 Token 数 ÷ 1,000,000 × 对应档位的输出单价 缓存费用 = 命中缓存的 Token 数 ÷ 1,000,000 × 对应档位的缓存单价 总费用 = 输入费用 + 输出费用 + 缓存费用 # 场景1: 输入 20,000 Token(命中「输入 ≤ 32K」档位) 档位单价:输入 3.2 元/百万,输出 16 元/百万,缓存命中 0.64 元/百万 假设本次调用数据如下: 实际输入 Token 数:20,000 实际输出 Token 数:5,000 命中缓存的 Token 数:10,000 分步计算: 输入费用:(20,000 ÷ 1,000,000 × 3.2 = 0.064元) 输出费用:(5,000 ÷ 1,000,000 × 16 = 0.08元) 缓存费用:(10,000 ÷ 1,000,000 × 0.64 = 0.0064元) 总费用:(0.064 + 0.08 + 0.0064 = 0.1504元) # 场景2: 输入 100,000 Token(命中「32K < 输入 ≤ 128K」档位) 档位单价:输入 4.8 元/百万,输出 24 元/百万,缓存命中 0.96 元/百万 假设本次调用数据如下: 实际输入 Token 数:100,000 实际输出 Token 数:20,000 命中缓存的 Token 数:30,000 分步计算: 输入费用:(100,000 ÷ 1,000,000 × 4.8 = 0.48元) 输出费用:(20,000 ÷ 1,000,000 × 24 = 0.48元) 缓存费用:(30,000 ÷ 1,000,000 × 0.96 = 0.0288元) 总费用:(0.48 + 0.48 + 0.0288 = 0.9888元) # 场景3: 输入 200,000 Token(命中「128K < 输入 ≤ 256K」档位) 档位单价:输入 9.6 元/百万,输出 48 元/百万,缓存命中 1.92 元/百万 假设本次调用数据如下: 实际输入 Token 数:200,000 实际输出 Token 数:40,000 命中缓存的 Token 数:50,000 分步计算: 输入费用:(200,000 ÷ 1,000,000 × 9.6 = 1.92元) 输出费用:(40,000 ÷ 1,000,000 × 48 = 1.92元) 缓存费用:(50,000 ÷ 1,000,000 × 1.92 = 0.096元) 总费用:(1.92 + 1.92 + 0.096 = 3.936元)设置好后的效果:
3. 模型监控
注:当开启订阅与积分功能时,模型监控会自控开启,否则讲关闭
3.1 功能概述
模型监控模块用于实时统计与分析平台级模型的调用情况,为管理员提供调用次数、Token消耗、费用统计、错误情况等关键数据,支撑模型使用分析、成本管控与故障排查。
3.2 入口与权限
- 入口位置:系统管理 → 模型管理 → 模型监控
- 操作权限:仅平台管理员可查看,支持按时间范围筛选与明细日志查询
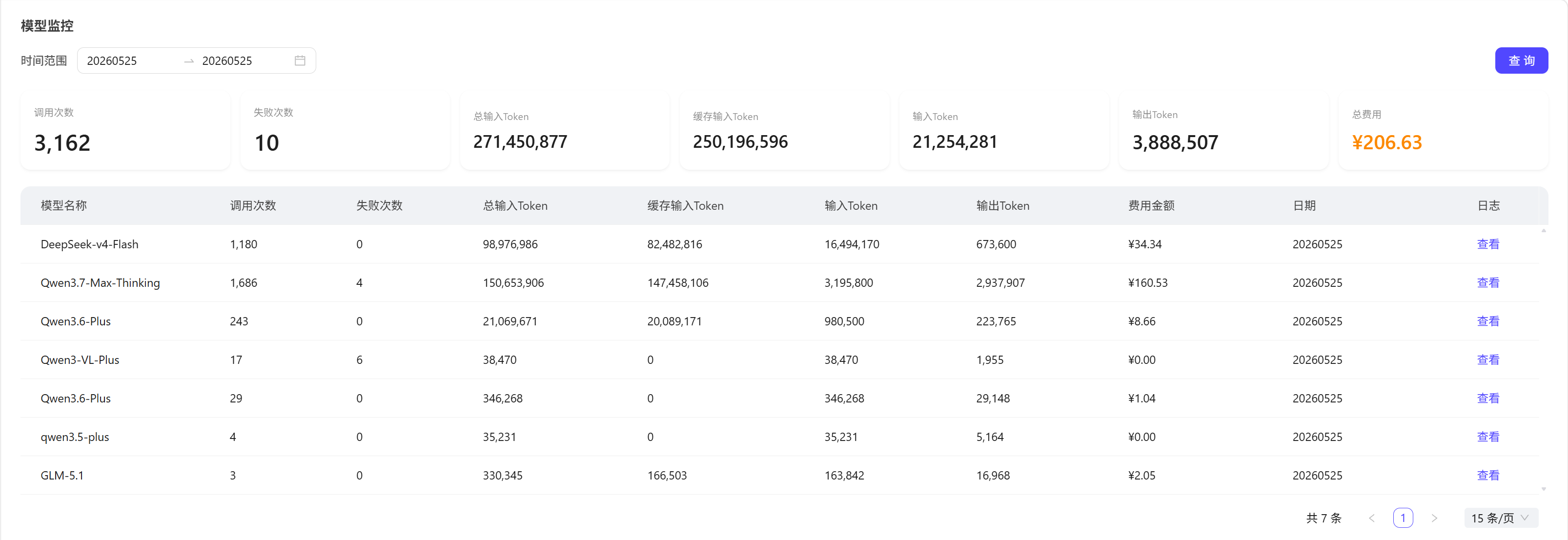
3.3 核心统计指标说明
| 指标 | 含义 |
|---|---|
| 调用次数 | 所选时间范围内,所有模型的总调用次数 |
| 失败次数 | 所选时间范围内,调用失败的总次数 |
| 总输入Token | 所有请求消耗的输入Token总数(含缓存命中Token) |
| 缓存输入Token | 命中上下文缓存的输入Token总数 |
| 输入Token | 实际计费的输入Token总数(非缓存部分) |
| 输出Token | 模型生成的输出Token总数 |
| 总费用 | 所选时间范围内,所有模型调用产生的总费用(按定价规则计算) |
3.4 操作功能说明
- 时间范围筛选:可自定义时间区间,查看指定时段的模型调用统计数据
- 日志查询:点击「查看」按钮,可进入模型调用明细日志,查看单次请求的详细参数、Token消耗、响应结果与错误信息等内容
- 分页查看:支持分页浏览模型明细数据,可自定义单页展示条数
3.5 业务价值与使用场景
- 成本管控:通过各模型的费用金额统计,分析高消耗模型,优化资源配置与定价策略
- 使用分析:通过调用次数与Token消耗,了解平台模型的使用热度与业务占比
- 故障排查:通过失败次数与日志明细,定位模型调用异常、接口报错问题
- 缓存效果评估:通过缓存输入Token占比,评估上下文缓存的实际使用效果,优化模型配置
3.6 不开订阅与积分功能时,如何开启模型监控功能
当平台管理方需要在不开启订阅与积分功能的情况下,查看模型调用情况时,可手动开启模型监控功能。 请在 config/application-external.yml 中添加如下内容,然后重启backend的docker服务容器
model-api-proxy:
enable-model-proxy: true
port: 18086
#记录日志
save-log: true