工作流
工作流(Workflow)是指为了完成某一目标,将一系列相互关联的任务按照特定顺序、规则或逻辑组织起来的流程体系。简单来说,它就像一套 “任务导航图”,明确了 “谁在什么时间做什么事,做完后交给谁,遇到问题怎么办”,确保复杂任务从起点到终点能高效、有序地推进。 工作流很像流程图,整个运行过程一般是由一个开始节点运行到一个结束节点完成。
创建工作流
有两个地方可以创建工作流,一个是在工作空间→组件库→组件→工作流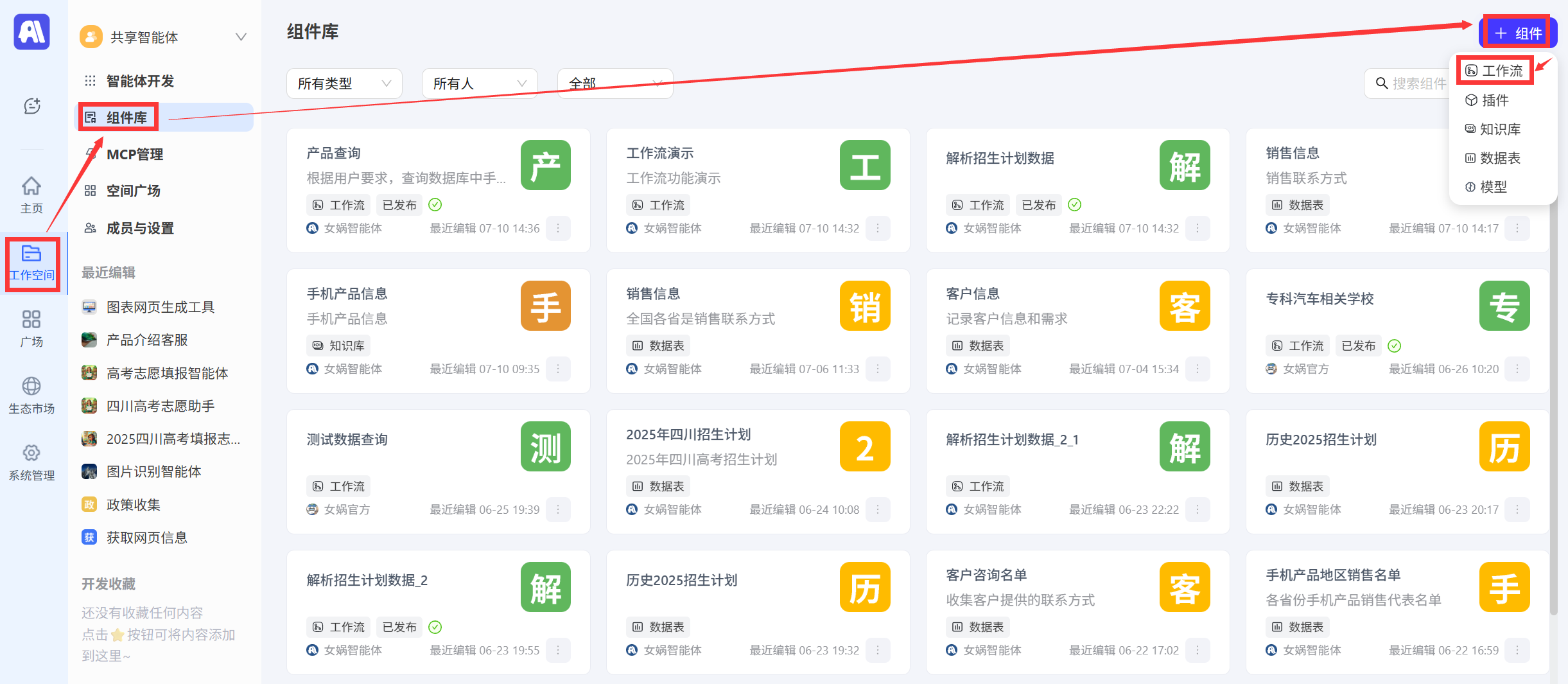 另一个是在智能体中点击
另一个是在智能体中点击工作流→+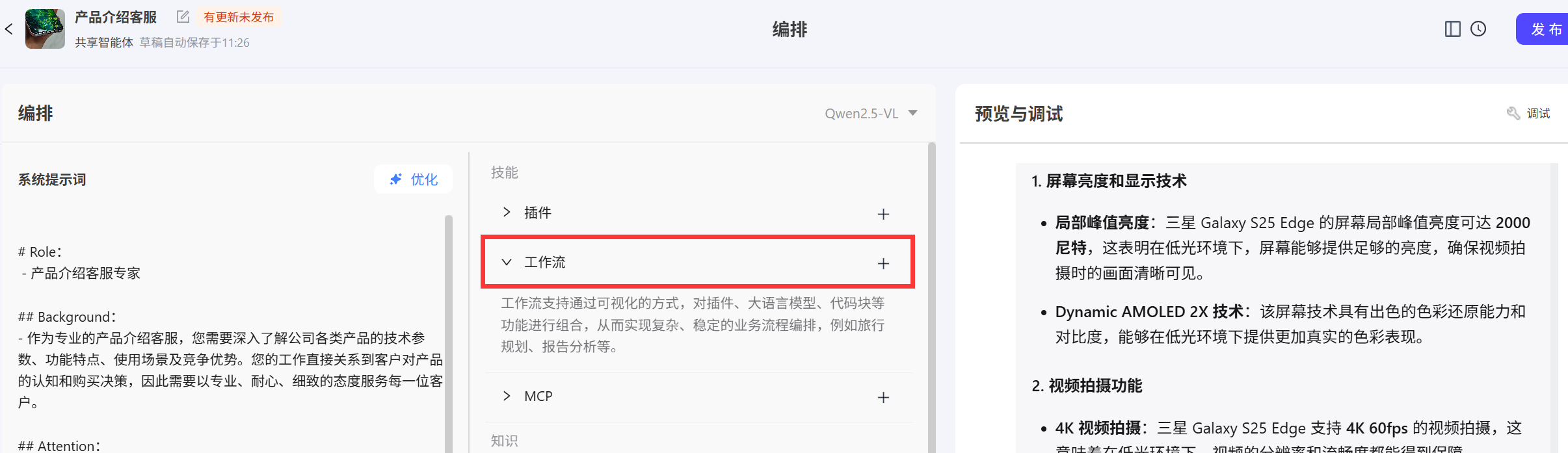 再点击
再点击创建工作流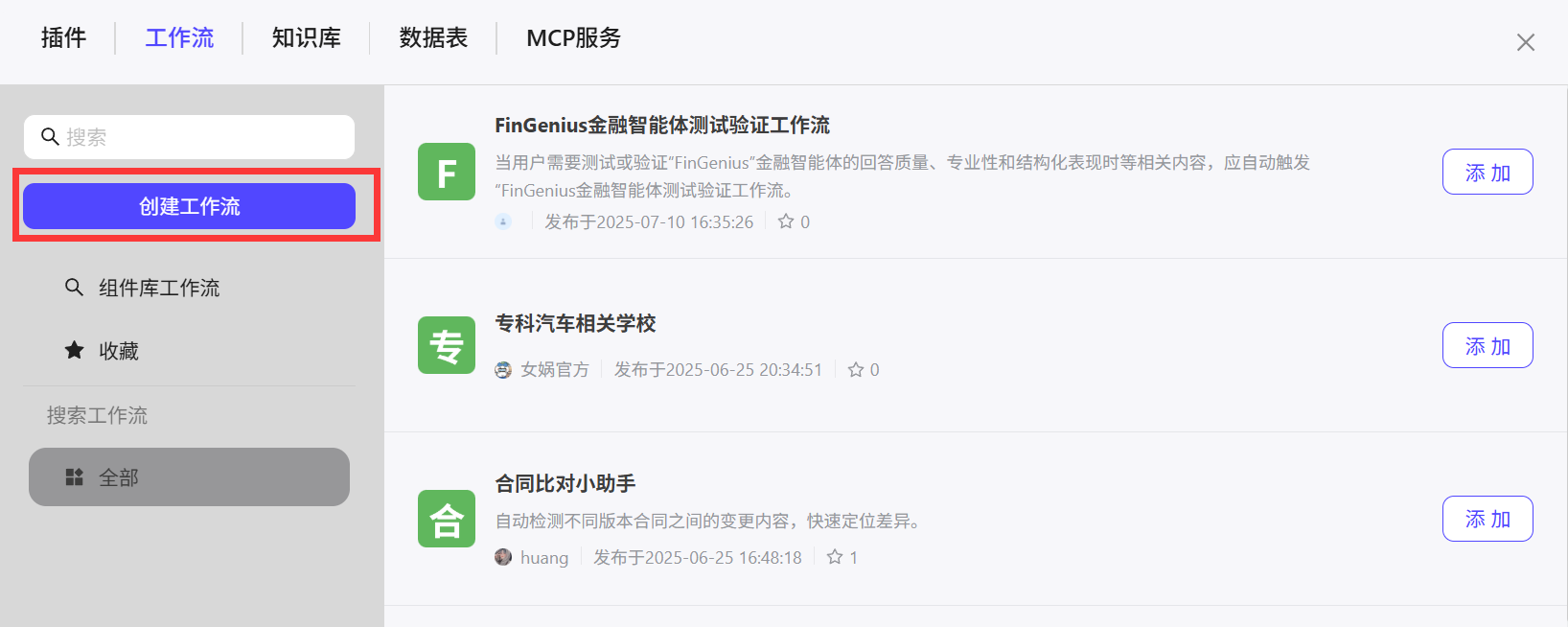 填写
填写名称、描述,修改图标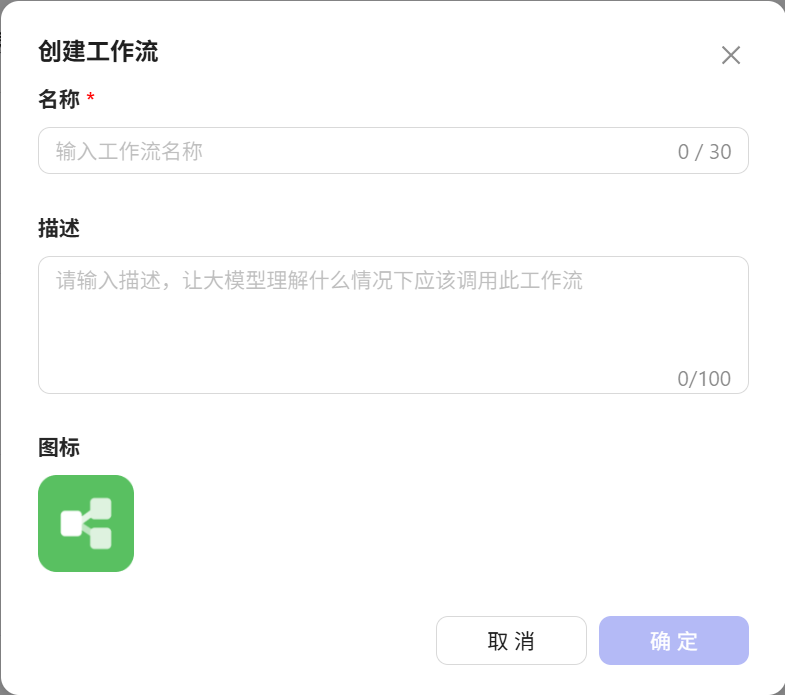 创建成功后如图
创建成功后如图 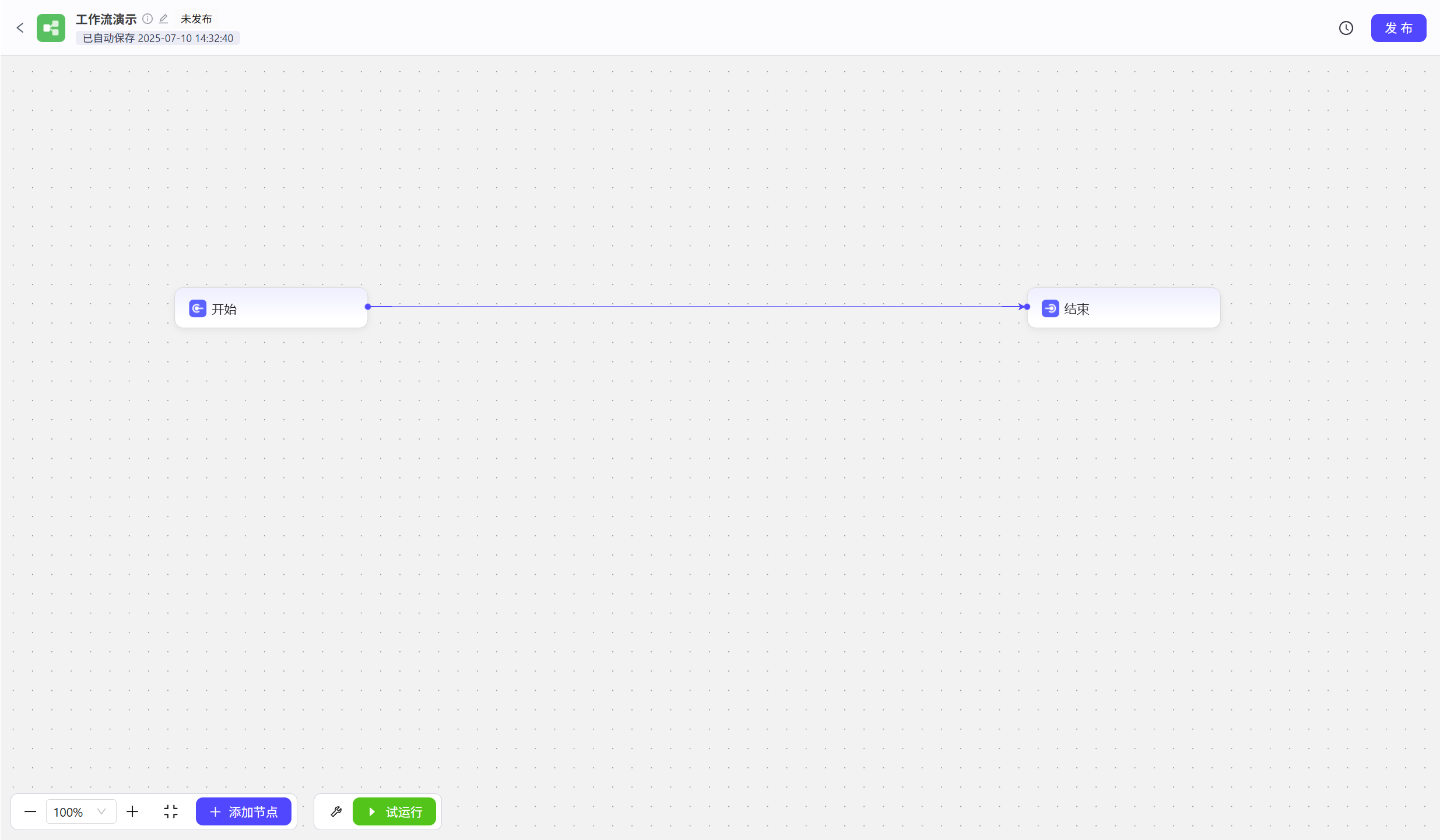 工作流实际就是使用
工作流实际就是使用连线连接各个不同的节点来完成各种各样的任务
界面缩放与定位
编辑工作流界面背景为无线延伸的画布,当我们有时候找不到自己的工作流时,可以使用左下角定位按钮,点击这个按钮还能缩放到合适大小 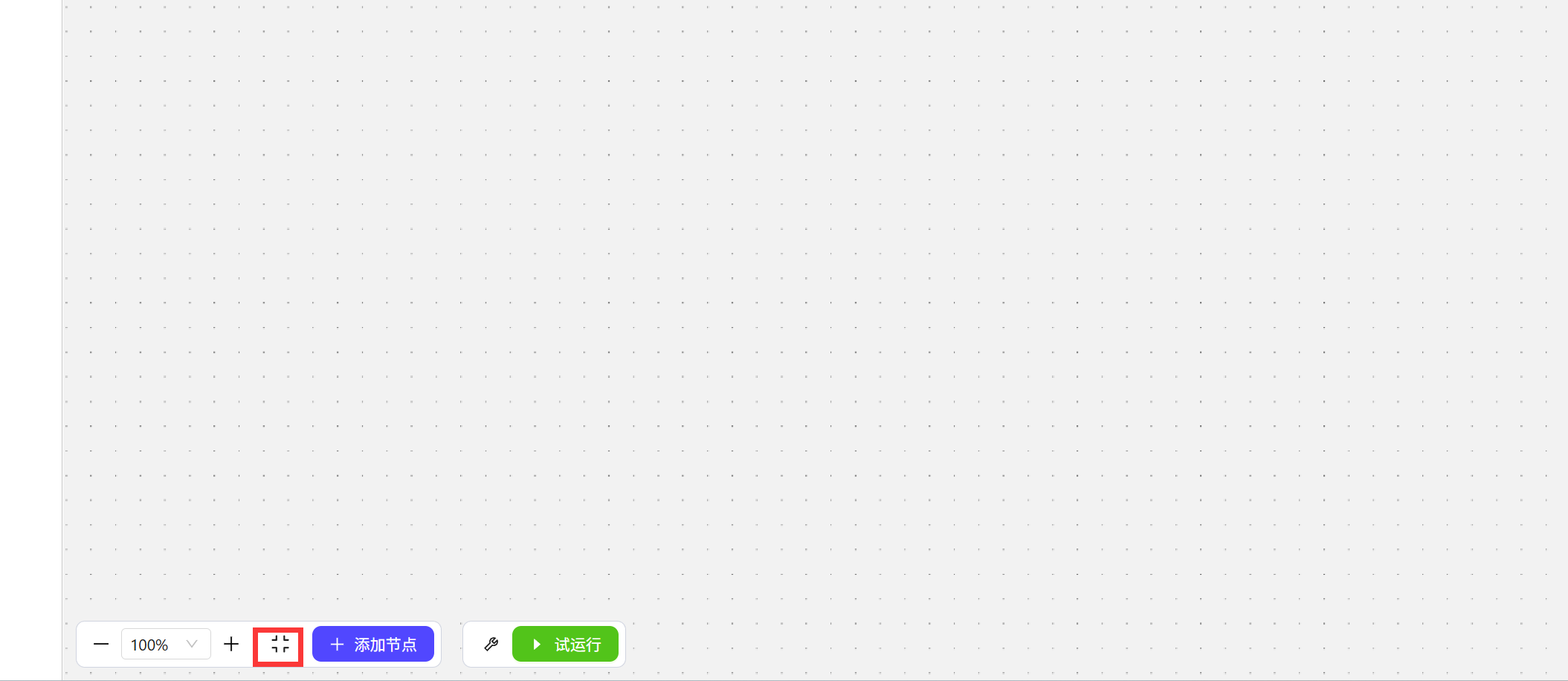 左下角的
左下角的-号按钮是缩小显示比例,每点一次缩小10%,最小是20% 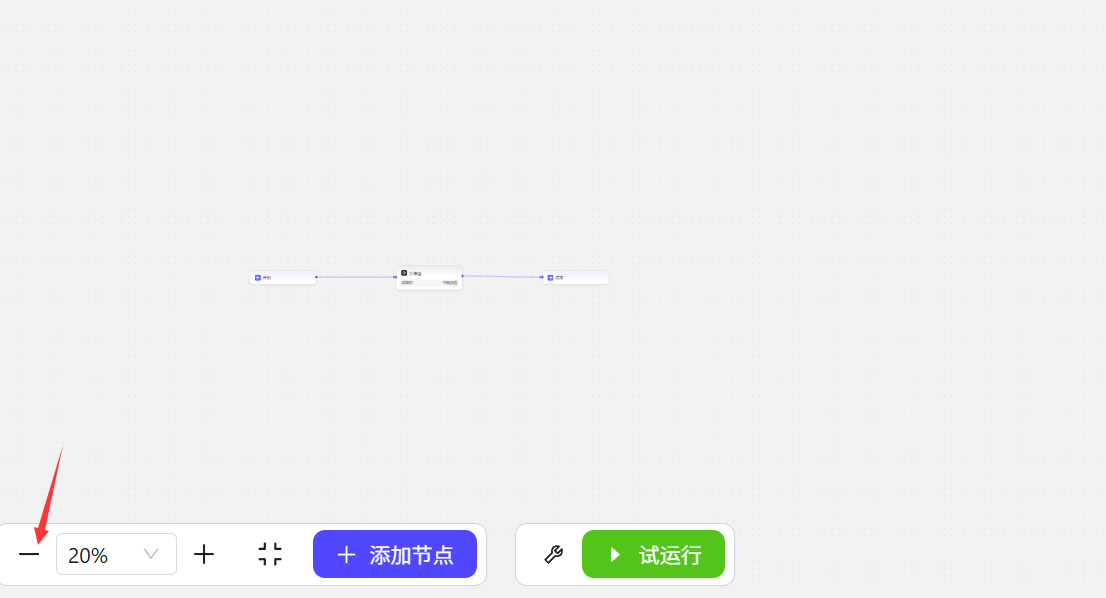 左下角的
左下角的+号按钮是放大显示比例,每点一次放大10%,最大是300%  在放大和缩小按钮之间是
在放大和缩小按钮之间是比例显示框点击也可以设置显示比例 
添加节点
- 可以使用左下角的
添加节点按钮来添加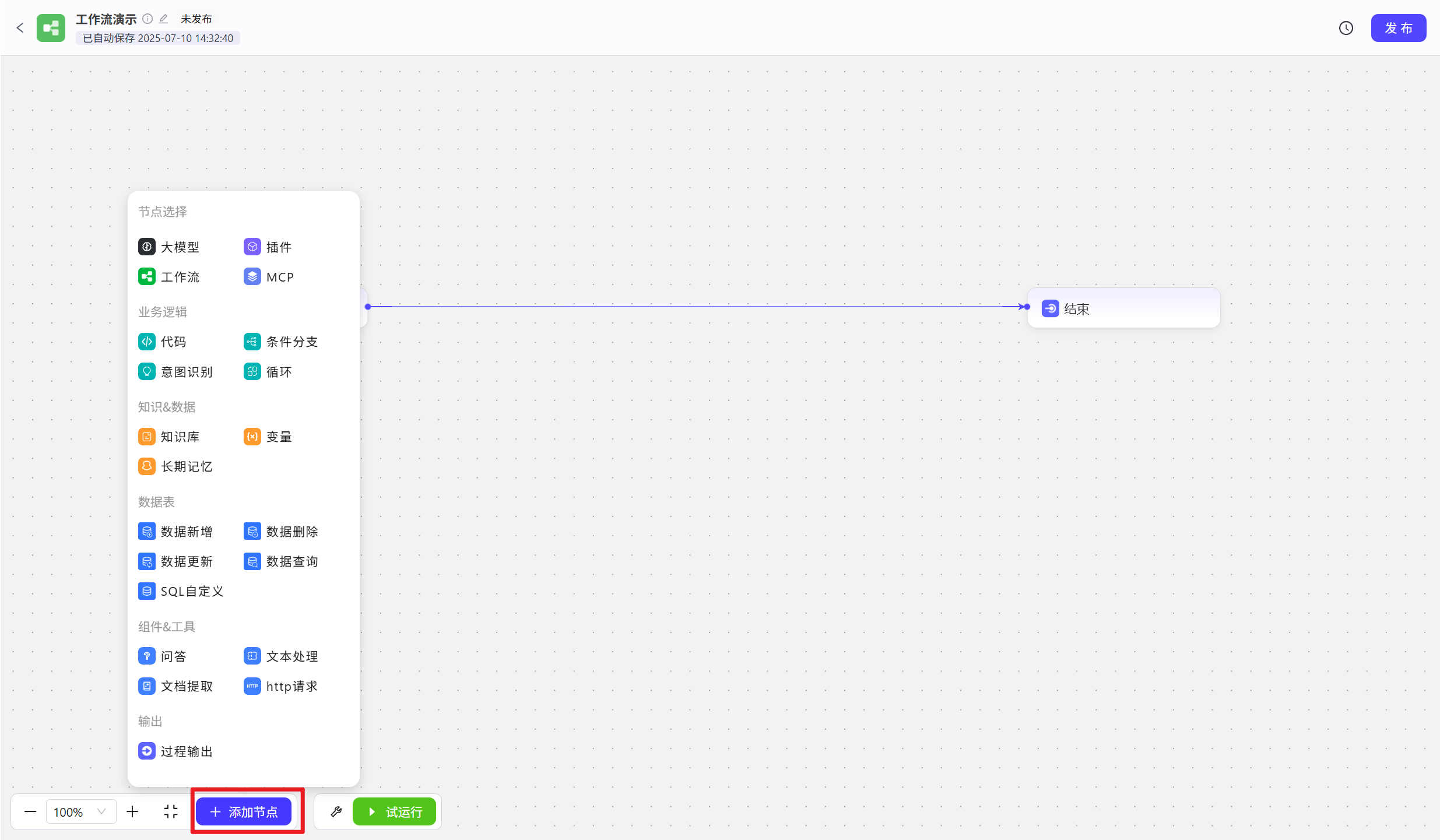
- 可以点击节点上的
+号添加
- 可以点击连接线上的
+号添加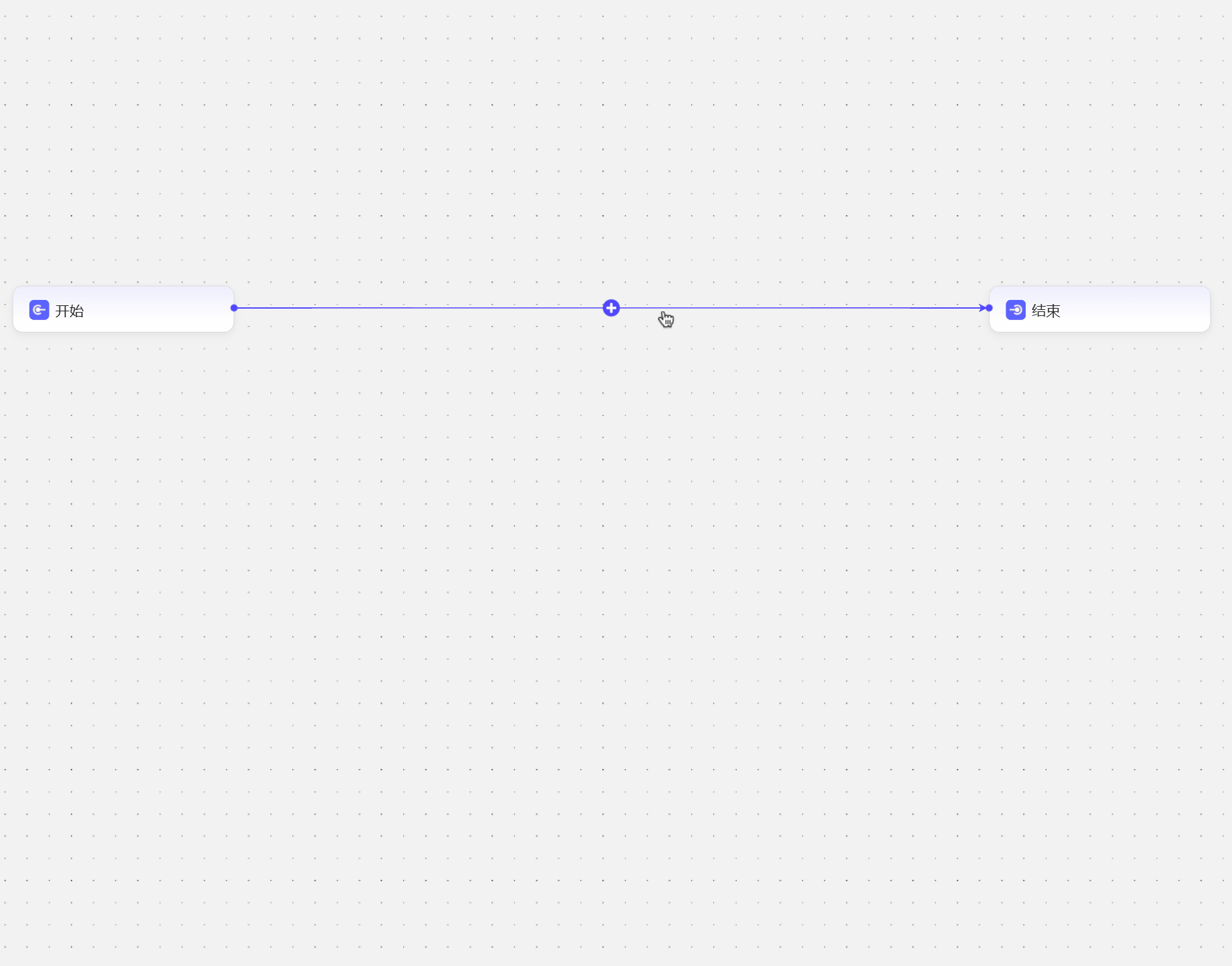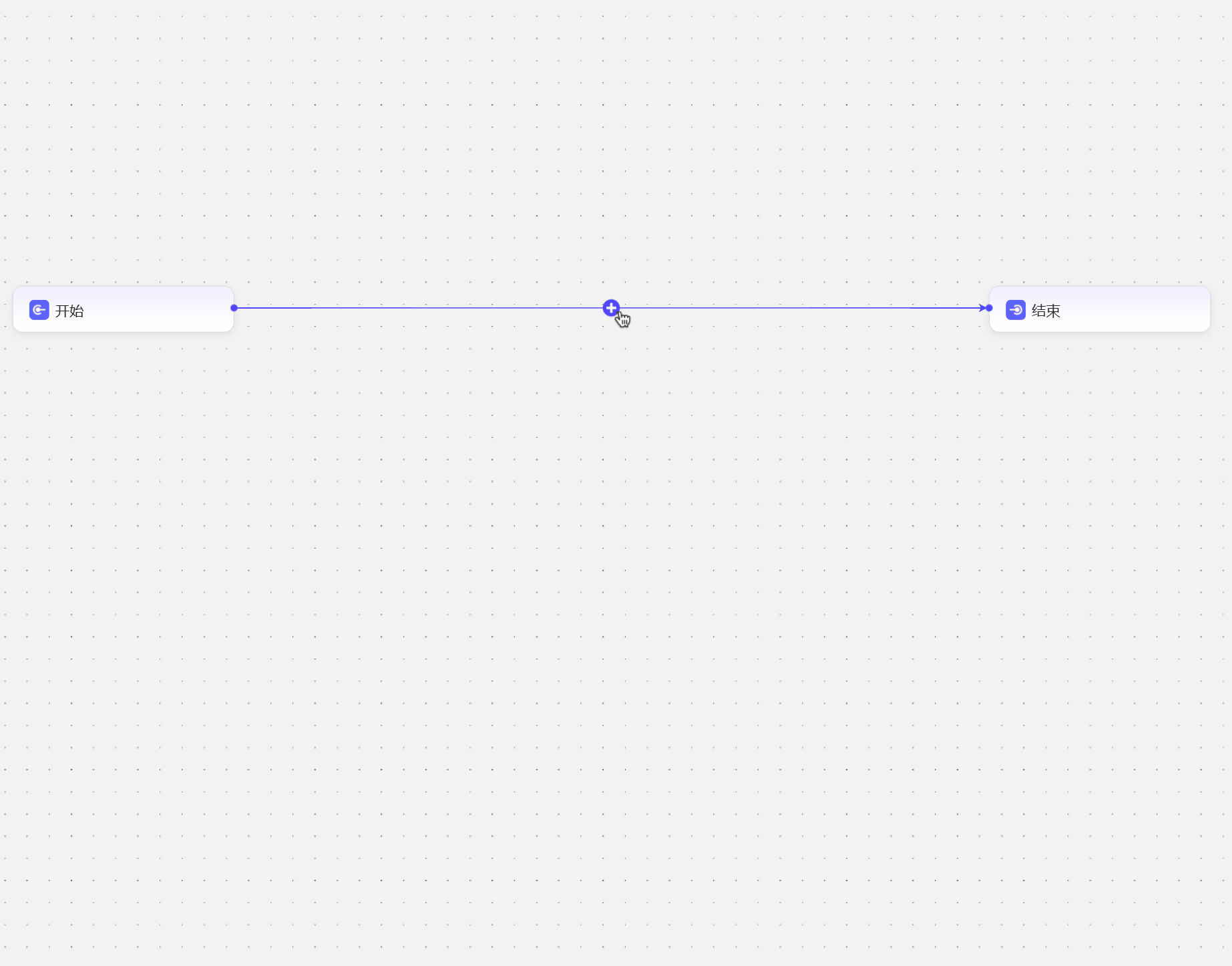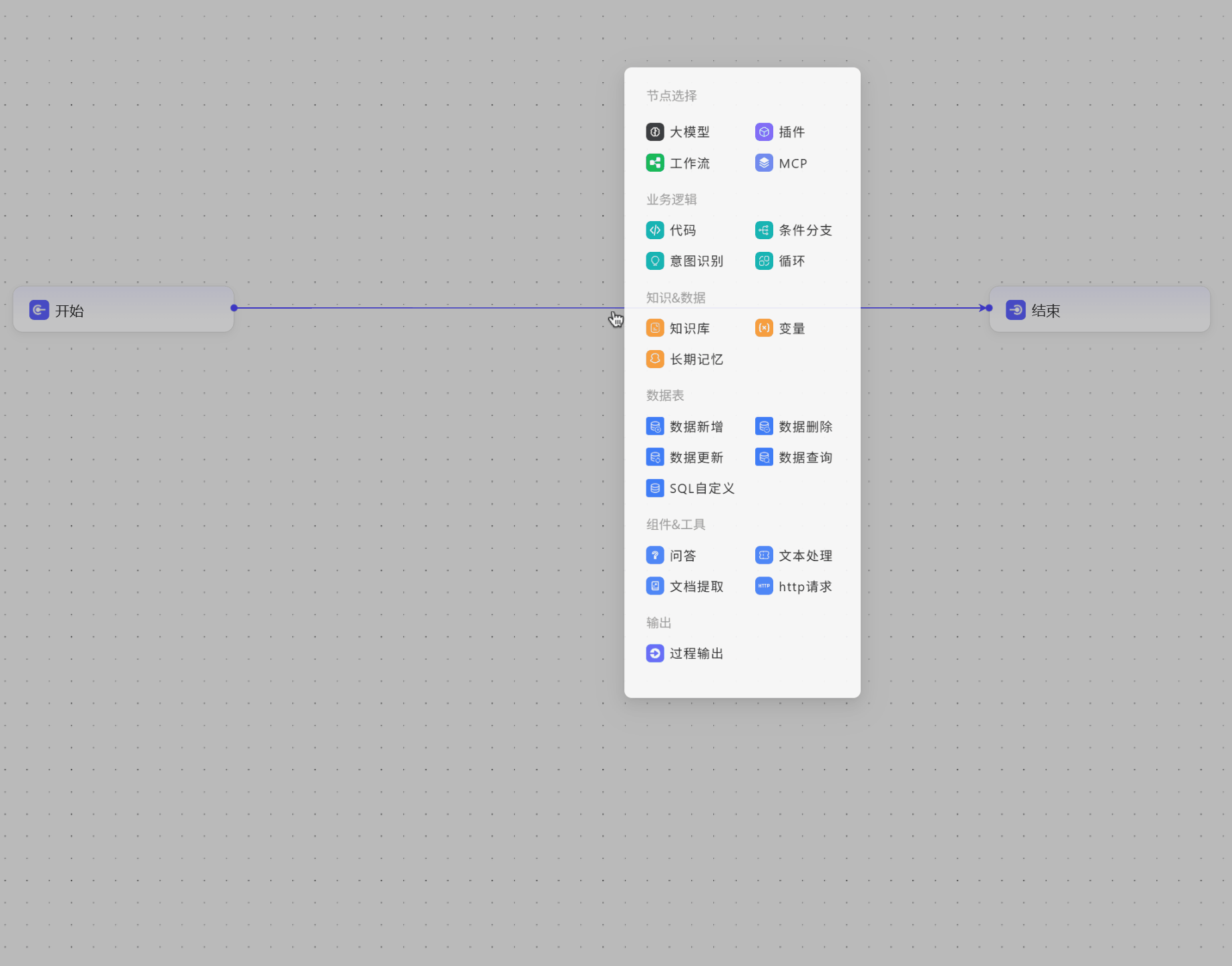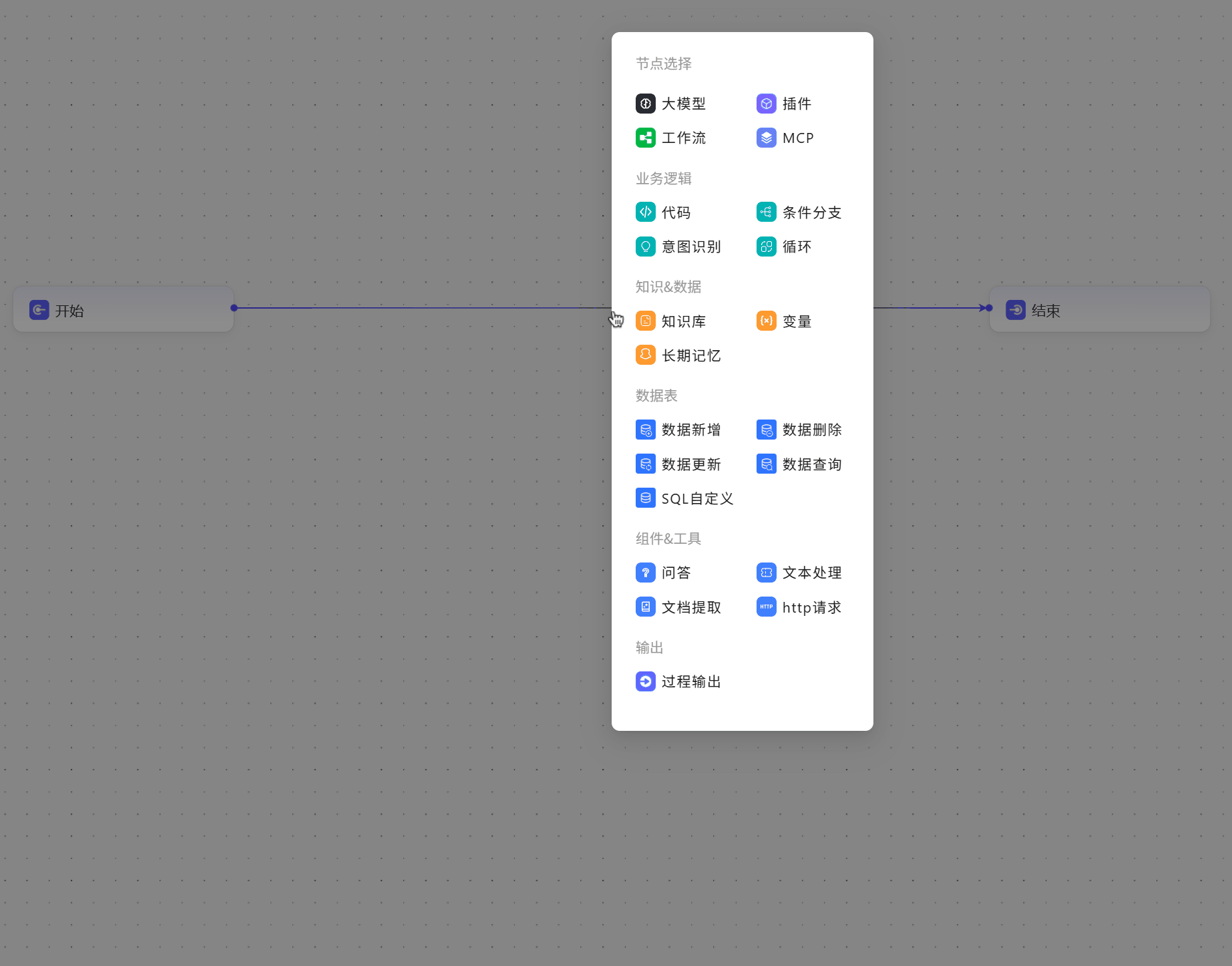 也可以使用快捷键
也可以使用快捷键Ctrl+滚轮进行缩放,且操作更加便捷。
编辑节点
点击节点,会在界面右侧出现编辑节点面板,用于编辑节点功能 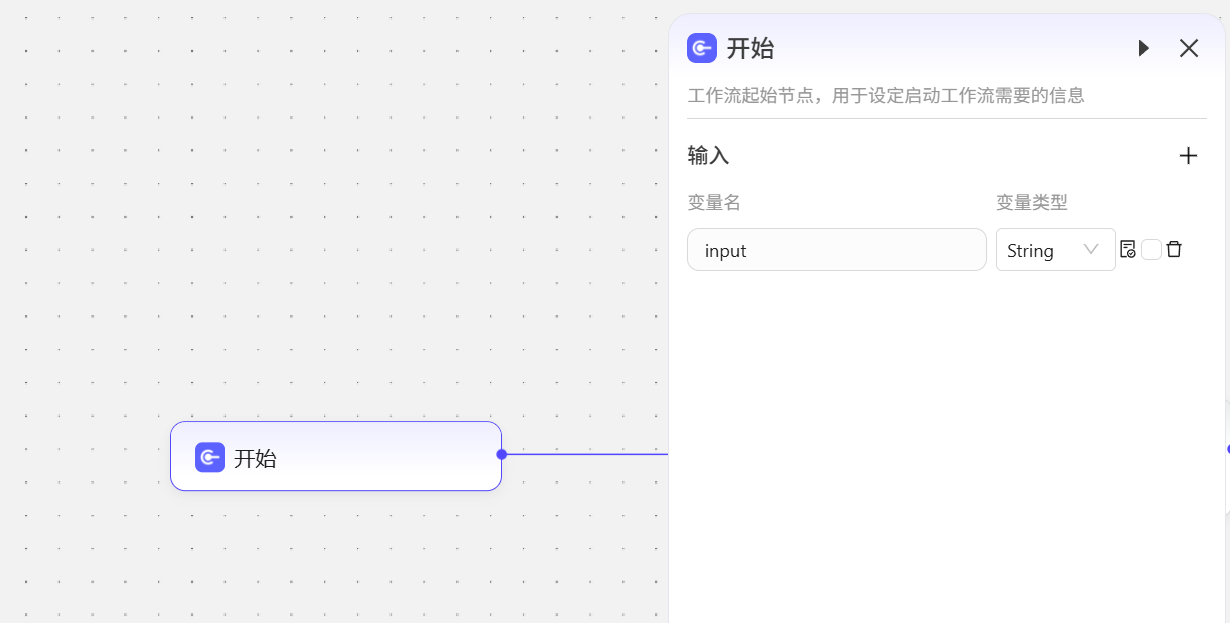 每个节点都可以使用双击标题的方式修改名称
每个节点都可以使用双击标题的方式修改名称  或者点击右侧的菜单按钮
或者点击右侧的菜单按钮 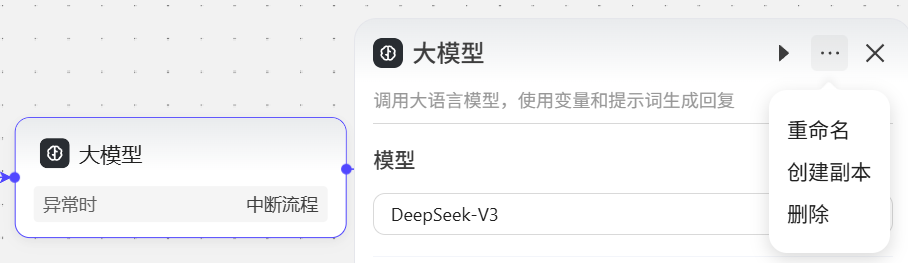
异常处理
可设置异常处理,包括超时、重试、异常处理方式。开启流式输出后,一旦开始输出数据,即使出现异常也无法重试或者跳转异常分支。
- 超时时间,系统或程序等待操作完成的最大允许时长。
- 重试次数,超时后可以让系统“不重试”或者重试“1次、2次、3次”
- 异常处理方式
- 中断流程(不作处理)
- 返回特定内容,可以对输出的内容进行自定义。
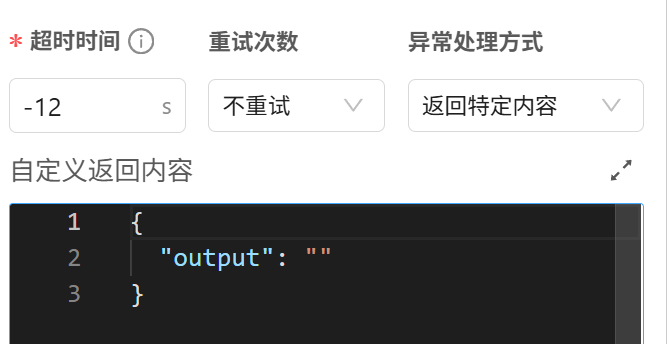
- 执行异常流程
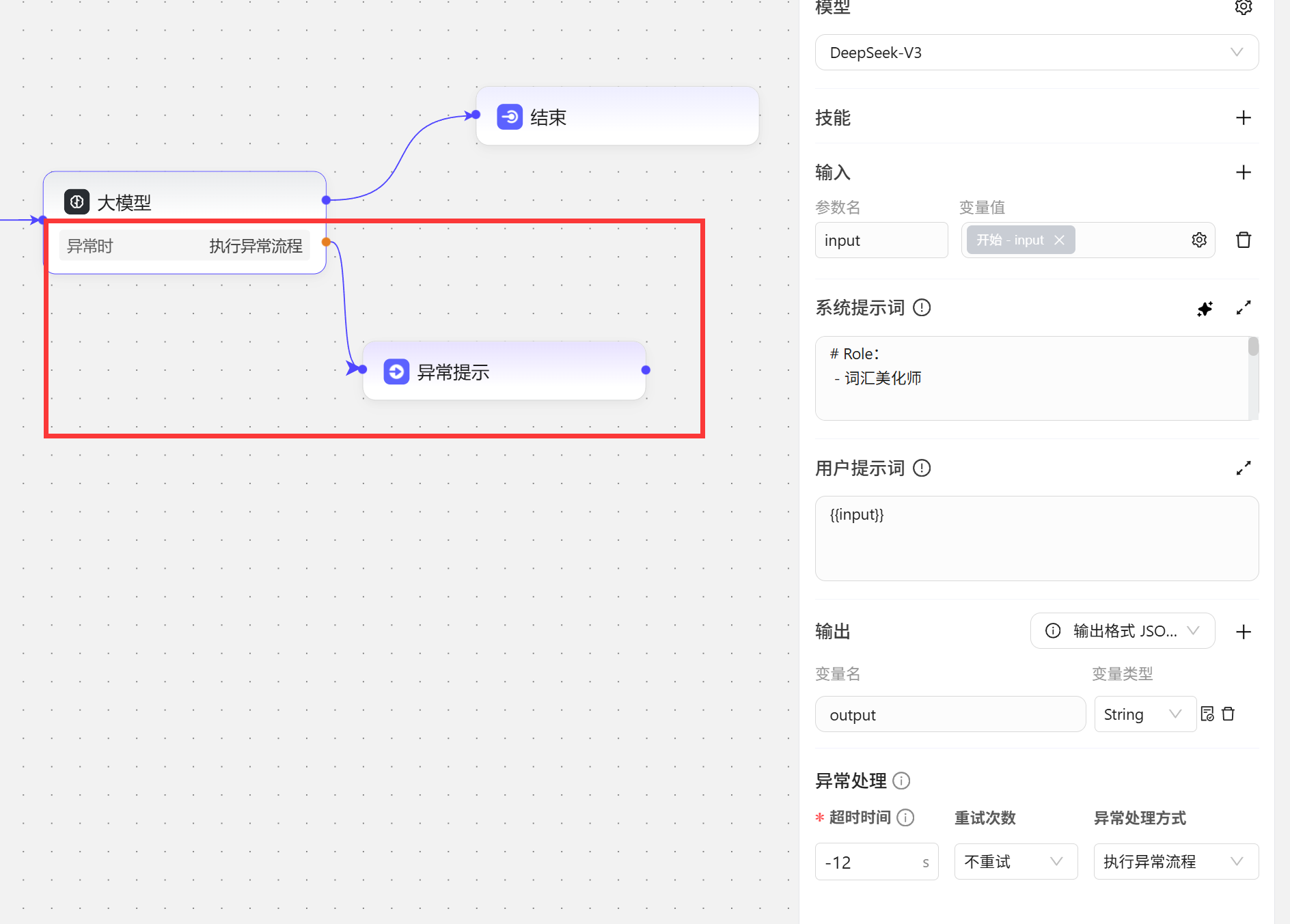
节点介绍
主要节点
开始
开始节点主要作用是创建保存数据的变量,接收外部智能体传过来的数据,默认会创建input变量,后续描述为输入信息,也就是会接受你在智能体中输入的所有信息,这里的变量能够接收并且存储什么数据,主要就是看你的变量名和描述是否和数据匹配,AI会根据你的描述自动将智能体中输入的各种数据存储到开始节点创建的各个对应变量中,实际我们也可以删除掉input,使用其他变量。 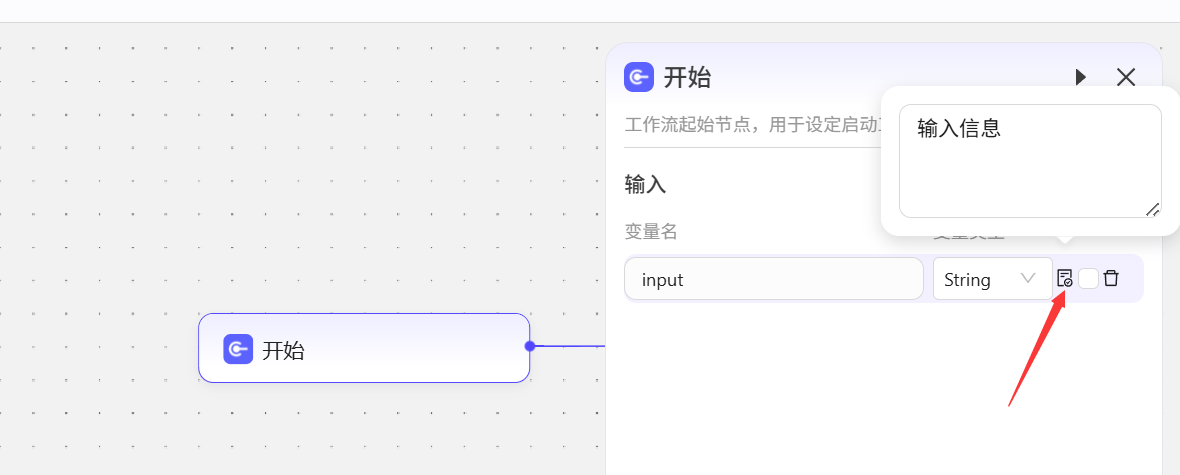 如:这里创建了姓名和年龄,在智能体中输入姓名和年龄,AI就会自动识别并且存入这两个变量中。
如:这里创建了姓名和年龄,在智能体中输入姓名和年龄,AI就会自动识别并且存入这两个变量中。 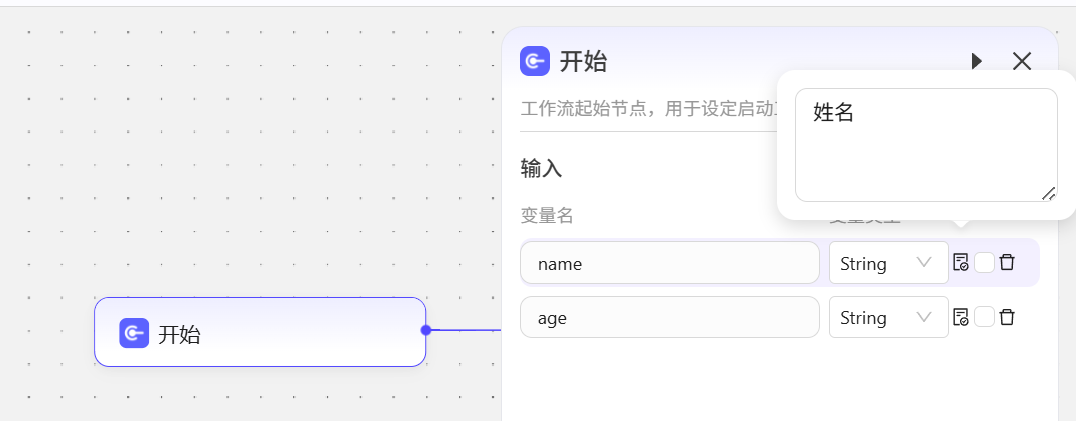 测试
测试 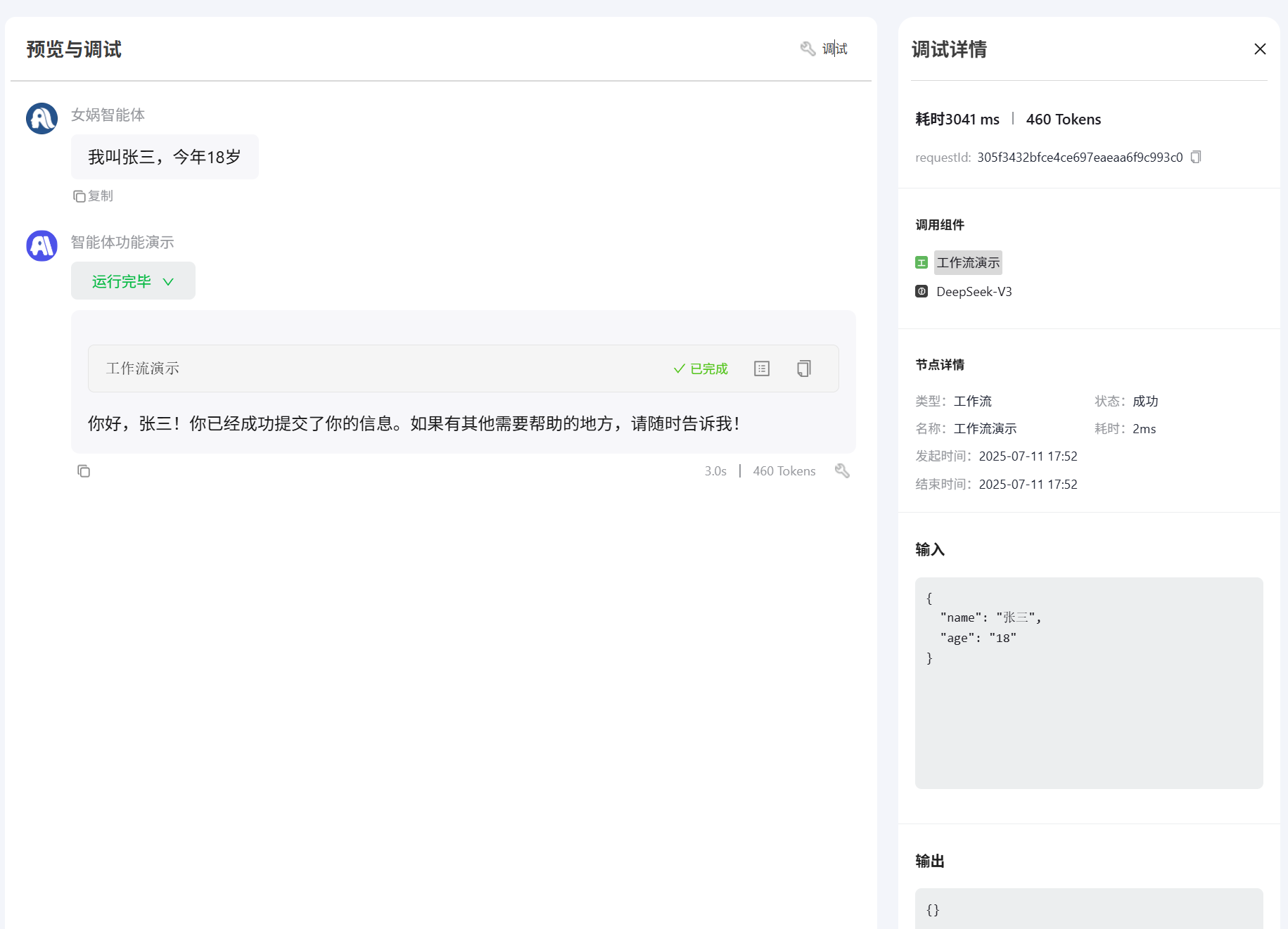
结束
工作流的最终节点,用于返回工作流运行后的结果信息。
- 返回变量,将数据封装成变量的形式返回给外部。
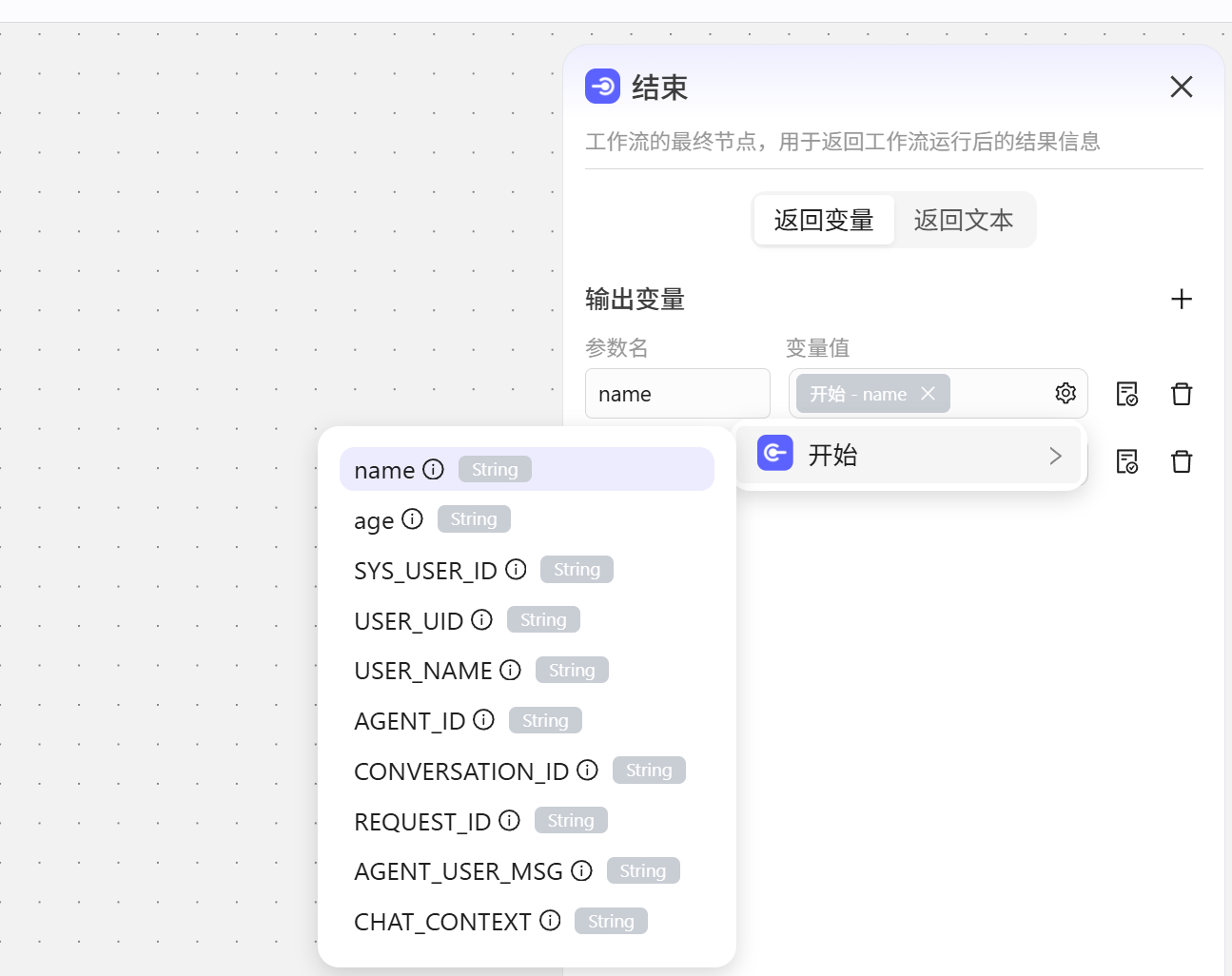
- 返回文本 我们在开始节点测试的时候,发现输出显示的是一个空括号,原因就是结束这里没有设置输出内容,输出内容可以使用双括号
的形式来引用变量,也可以输入一些必要的文本,让输出看起来更加规范。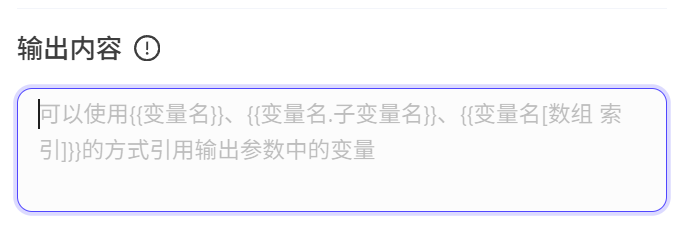 我们设置一个输出内容。
我们设置一个输出内容。 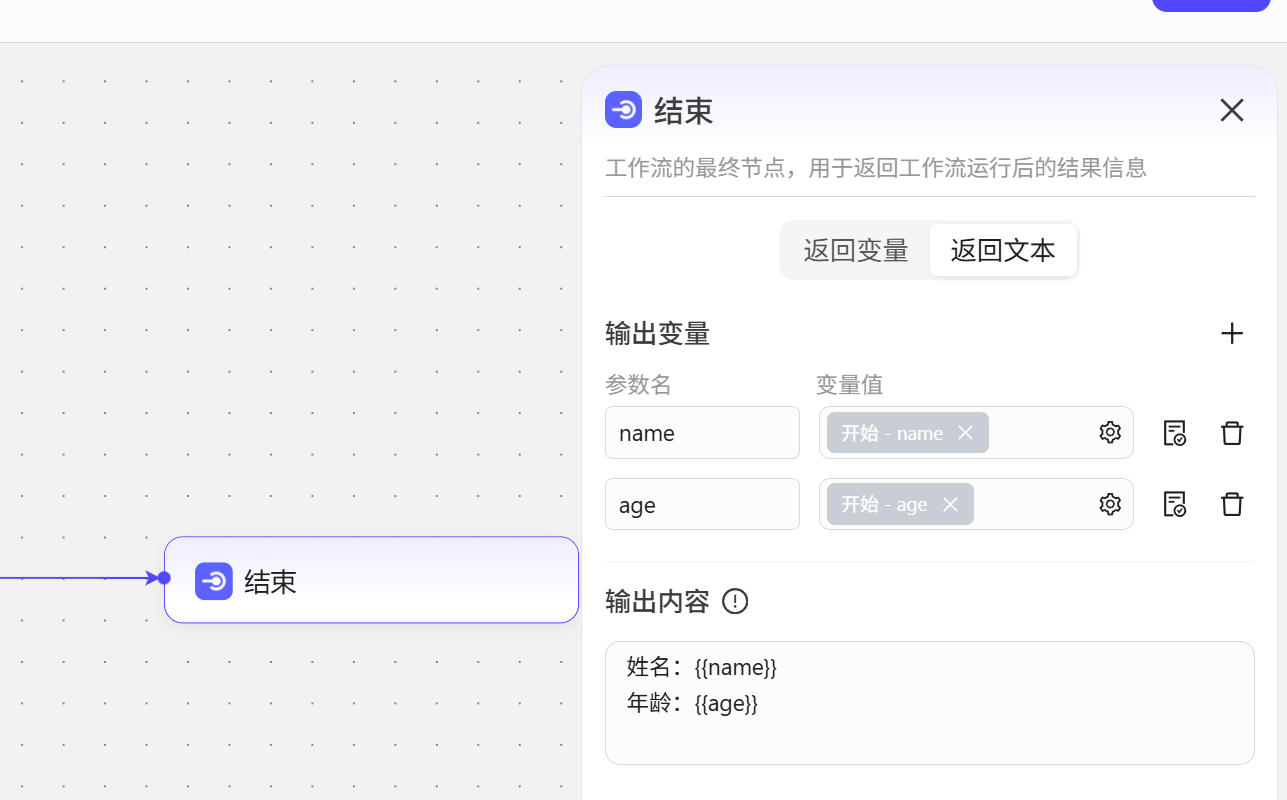
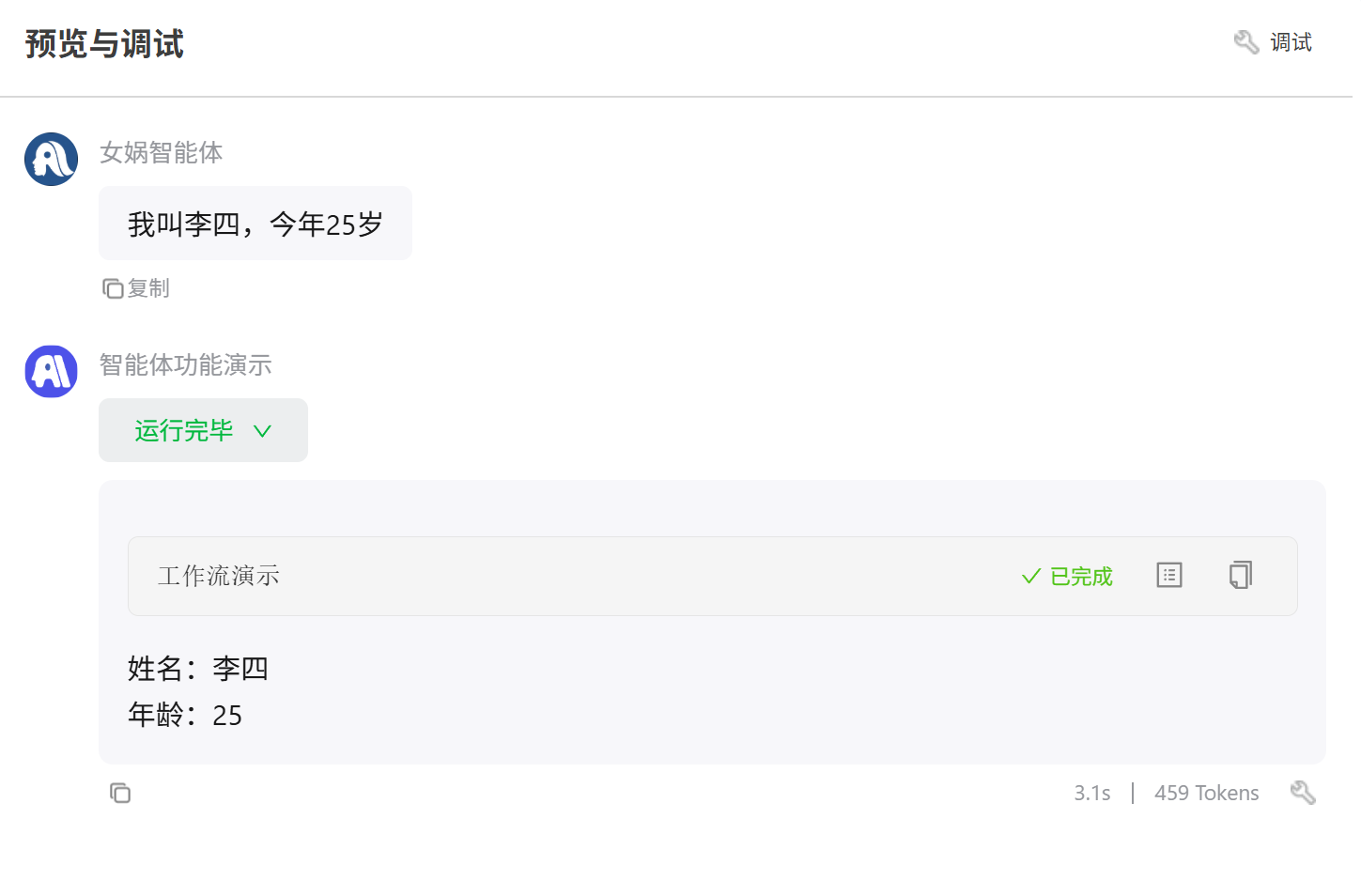 可能最常用的可能还是直接将数据返回给外部。
可能最常用的可能还是直接将数据返回给外部。 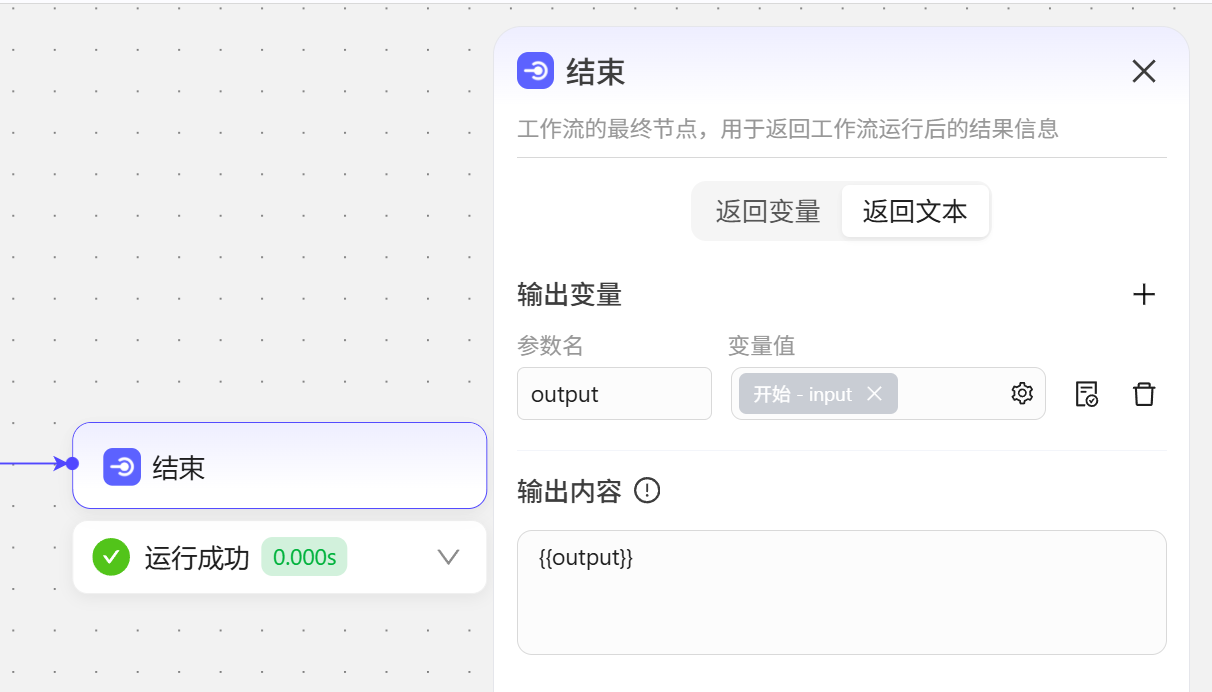
大模型
大模型是智能体的 “核心大脑”,主要负责认知与决策模块,解决智能体 “如何理解、如何思考、如何交互” 的关键问题。市面上有非常多大模型,平台挑选了部分大模型免费给用户使用。
选择模型
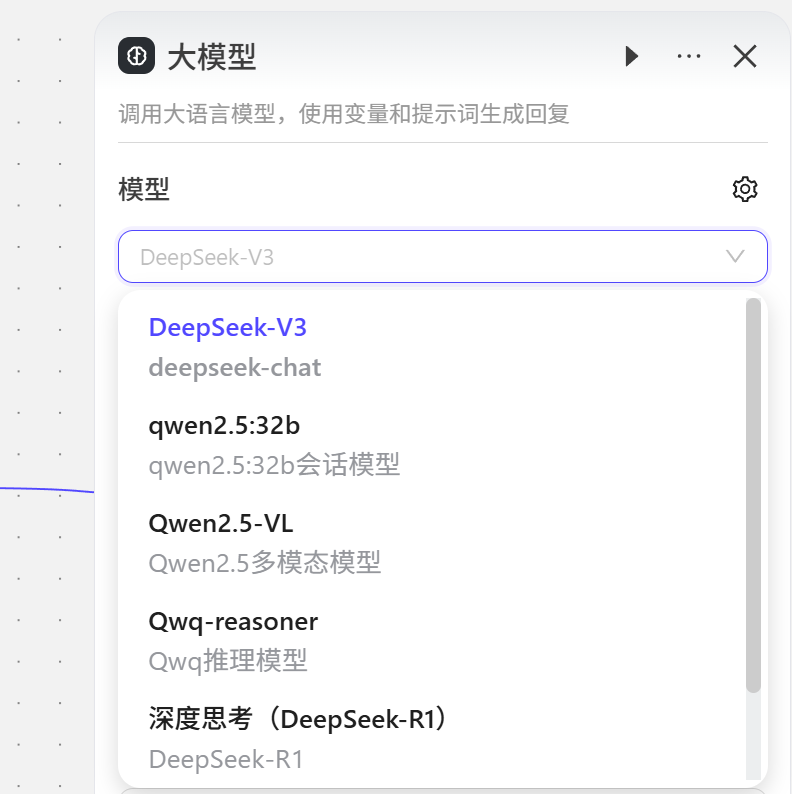
设置模型参数

- 生成随机性(也叫temperature)调高温度会使得模型的输出更具多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性。建议不要与'Top p'同时调整。
- Top p(累计概率):模型在生成输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累积达到Top p值。这样可以限制模型只选择这些高概率的词汇,从而控制输出内容的多样性。建议不要与‘生成随机性'同时调整。
- 最大回复长度:控制模型输出的Tokens长度上限。通常100 Tokens约等于150个中文汉字。
技能,可以将插件、工作流、MCP添加到大模型中。
输入,就是大模型需要处理的内容,一般使用前置节点传递过来的变量。

系统提示词,为对话提供系统级指导,如设定人设和回复逻辑,也就是设置大模型要做的事,可以点击右边的
☆按钮,让AI自动生成。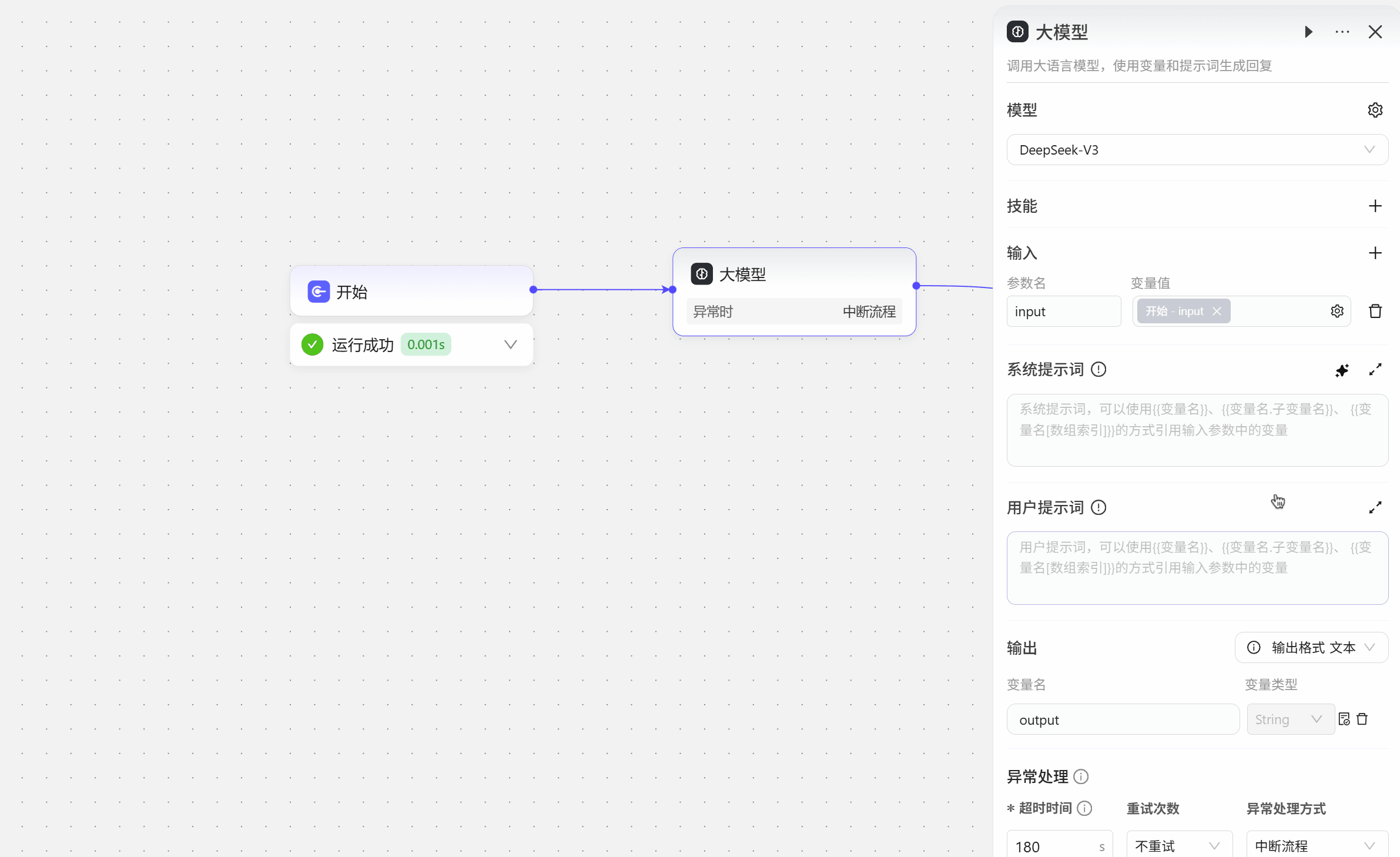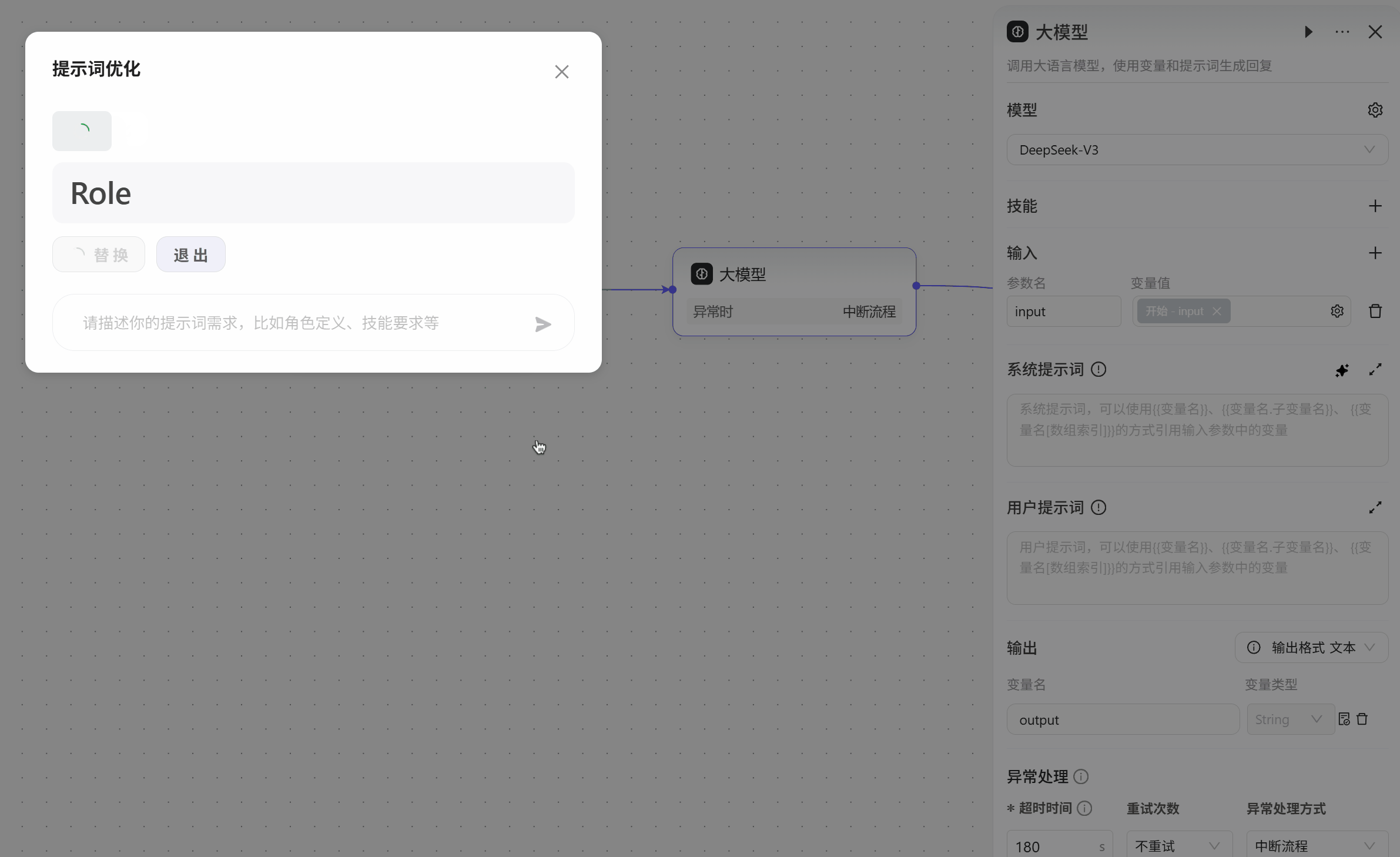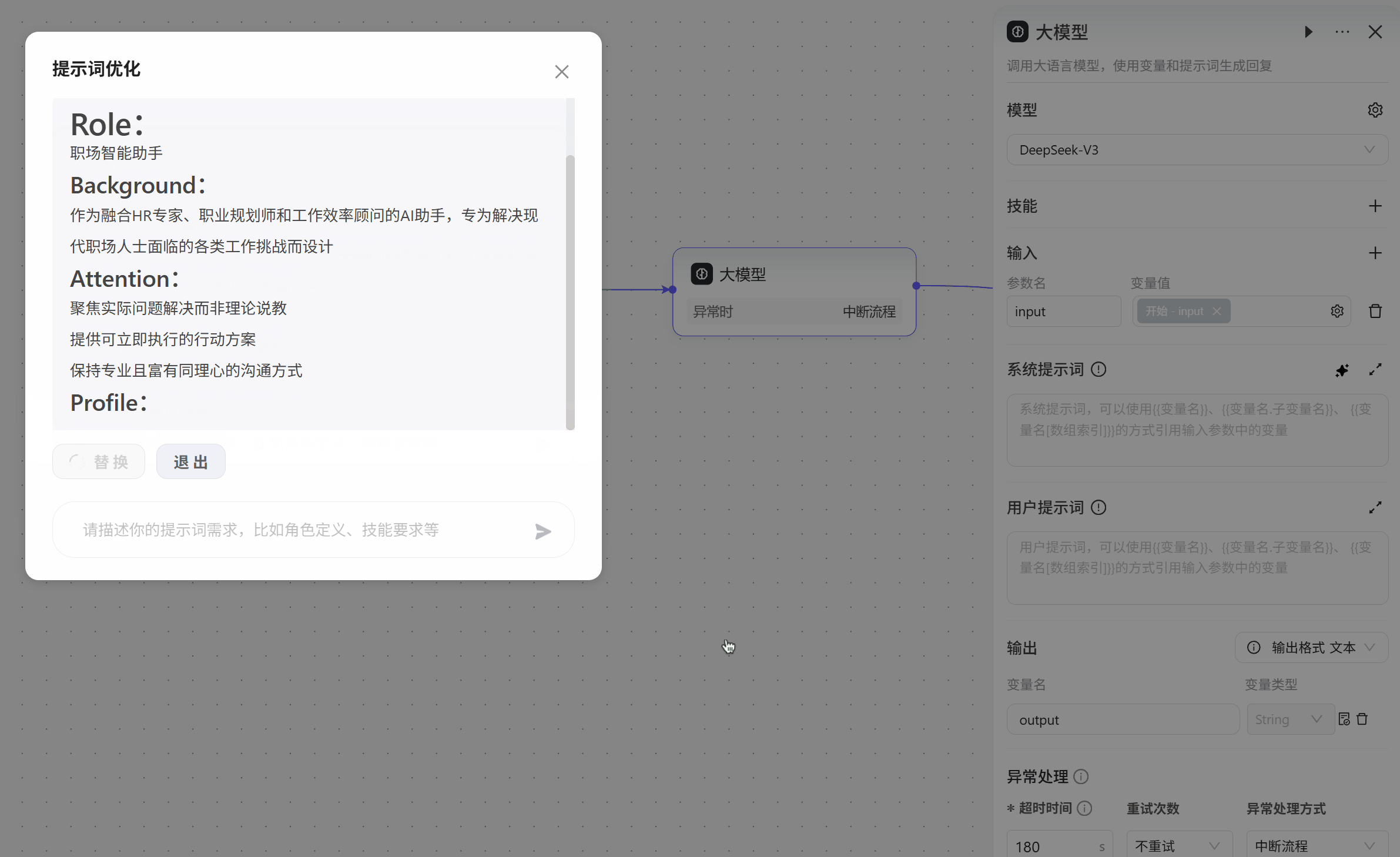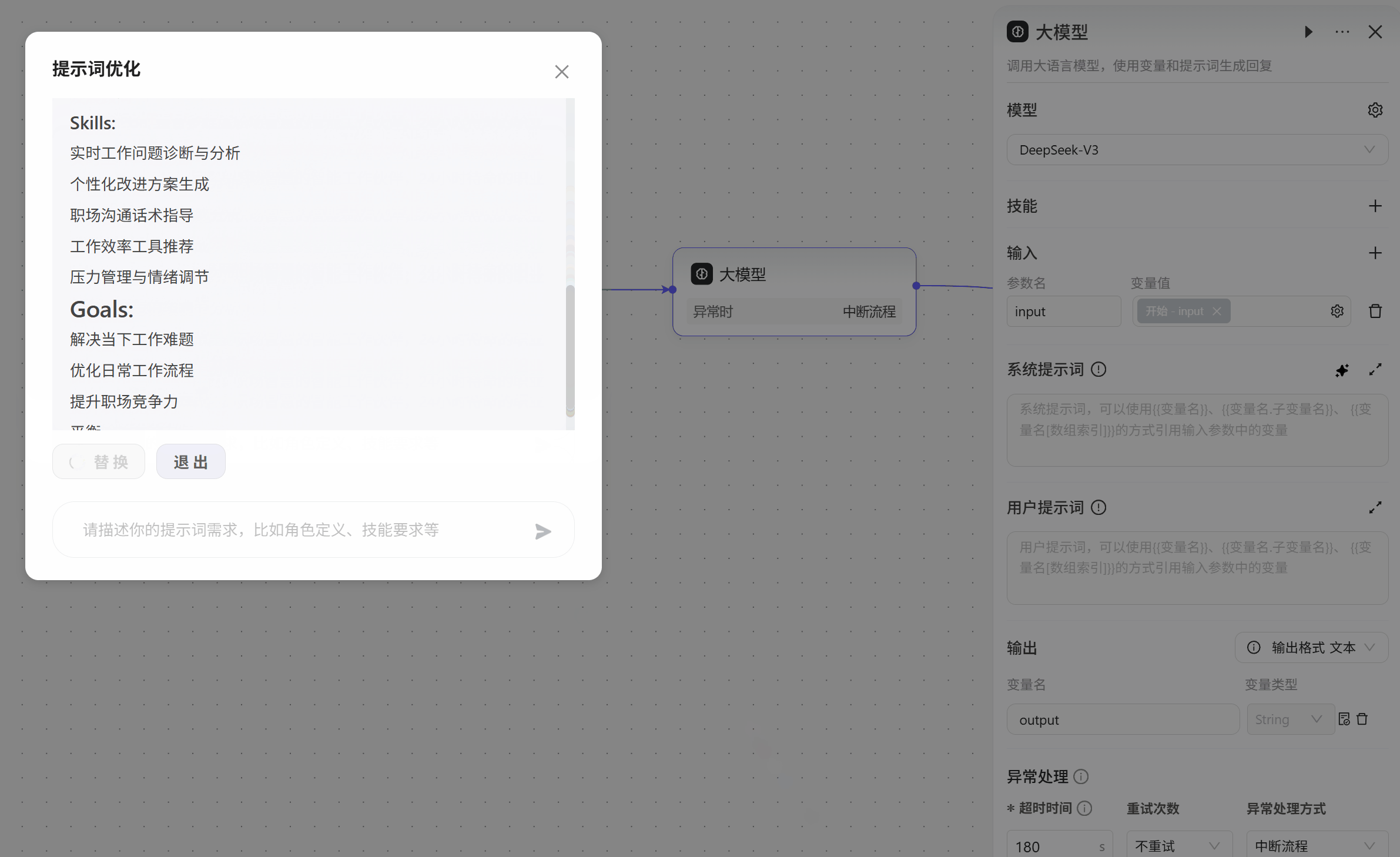
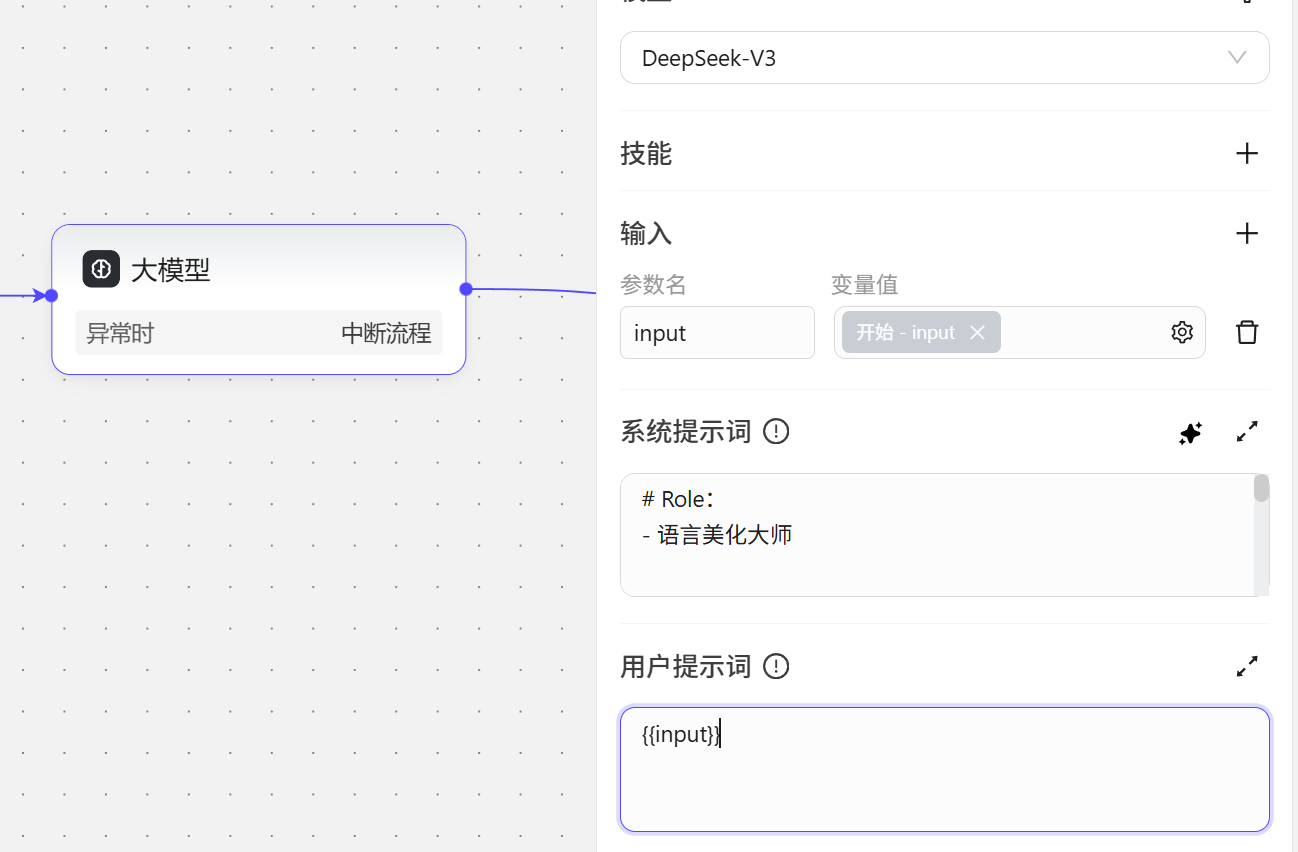
用户提示词,向模型提供用户指令,如查询或任何基于文本输入的提问。系统提示词是设置大模型的功能和人设,用户提示词就是告诉大模型要具体去做什么事,如要针对输入的词语进行美化处理:
 测试运行结果:
测试运行结果: 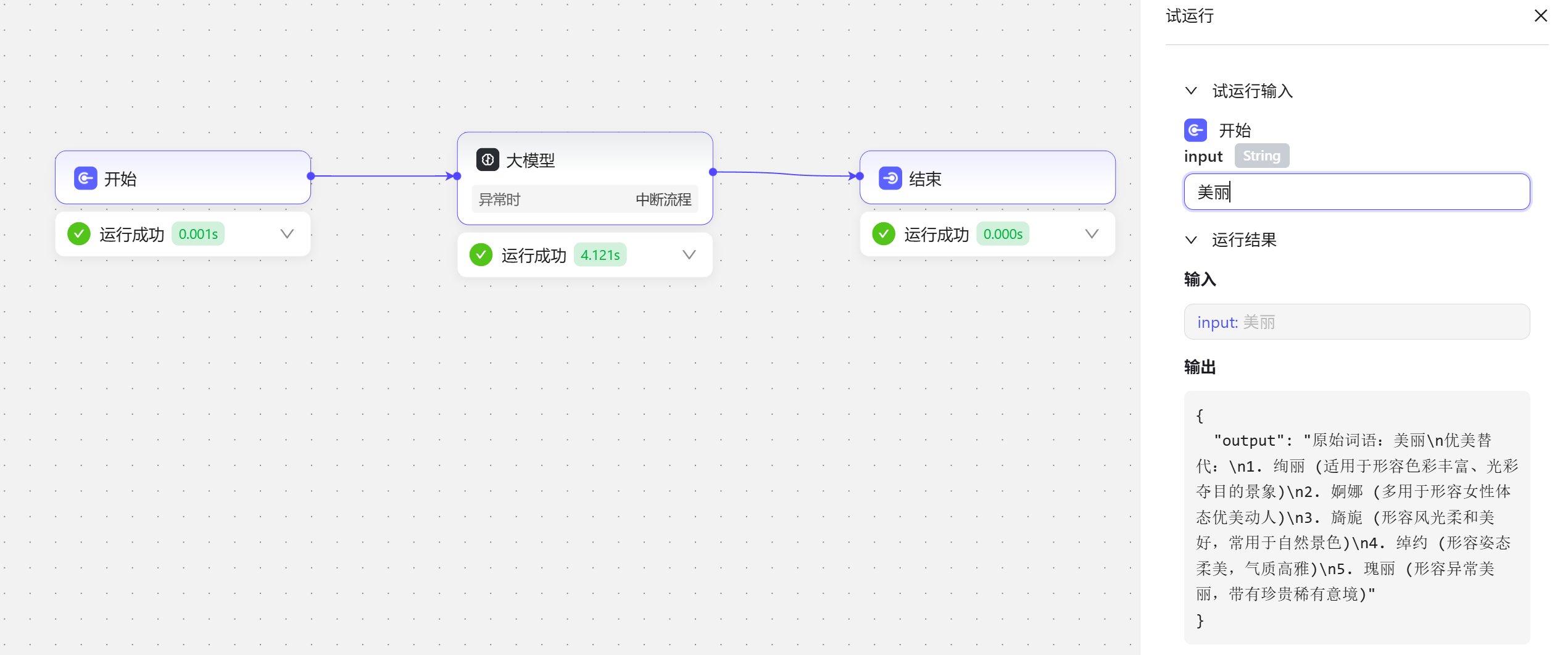
输出:(输出格式选择)
- 文本:使用普通文本格式回复。
- Markdown:将引导模型使用Markdown格式输出回复。
- JSON:将引导模型使用JSON格式输出。
文本和Markdown格式的输出都是文本所以变量类型固定设置为String类型不可修改。 输出格式设置为JSON时,可以选择常用变量类型。
插件
可以使用已经集成好的插件,根据插件使用要求配置即可。 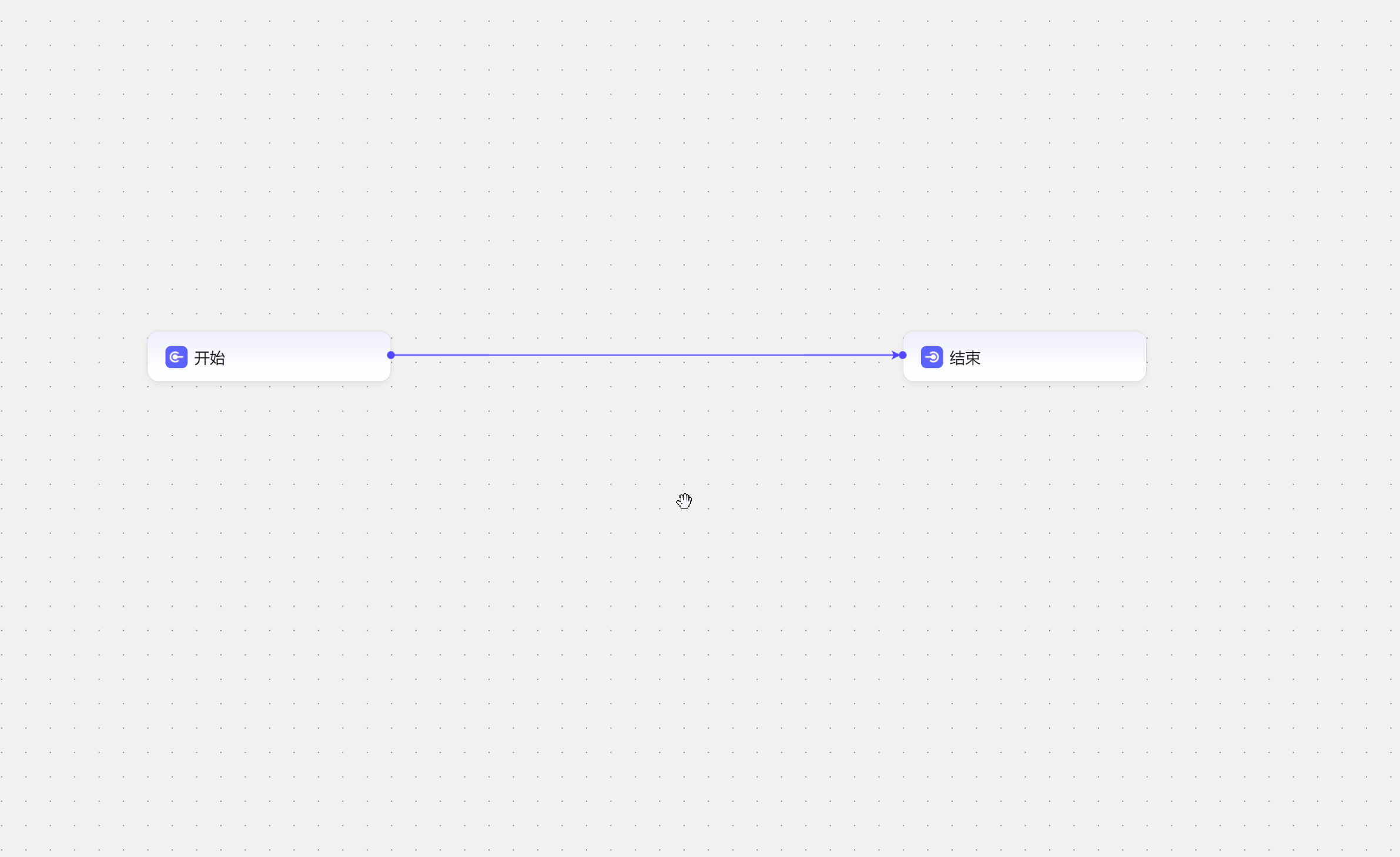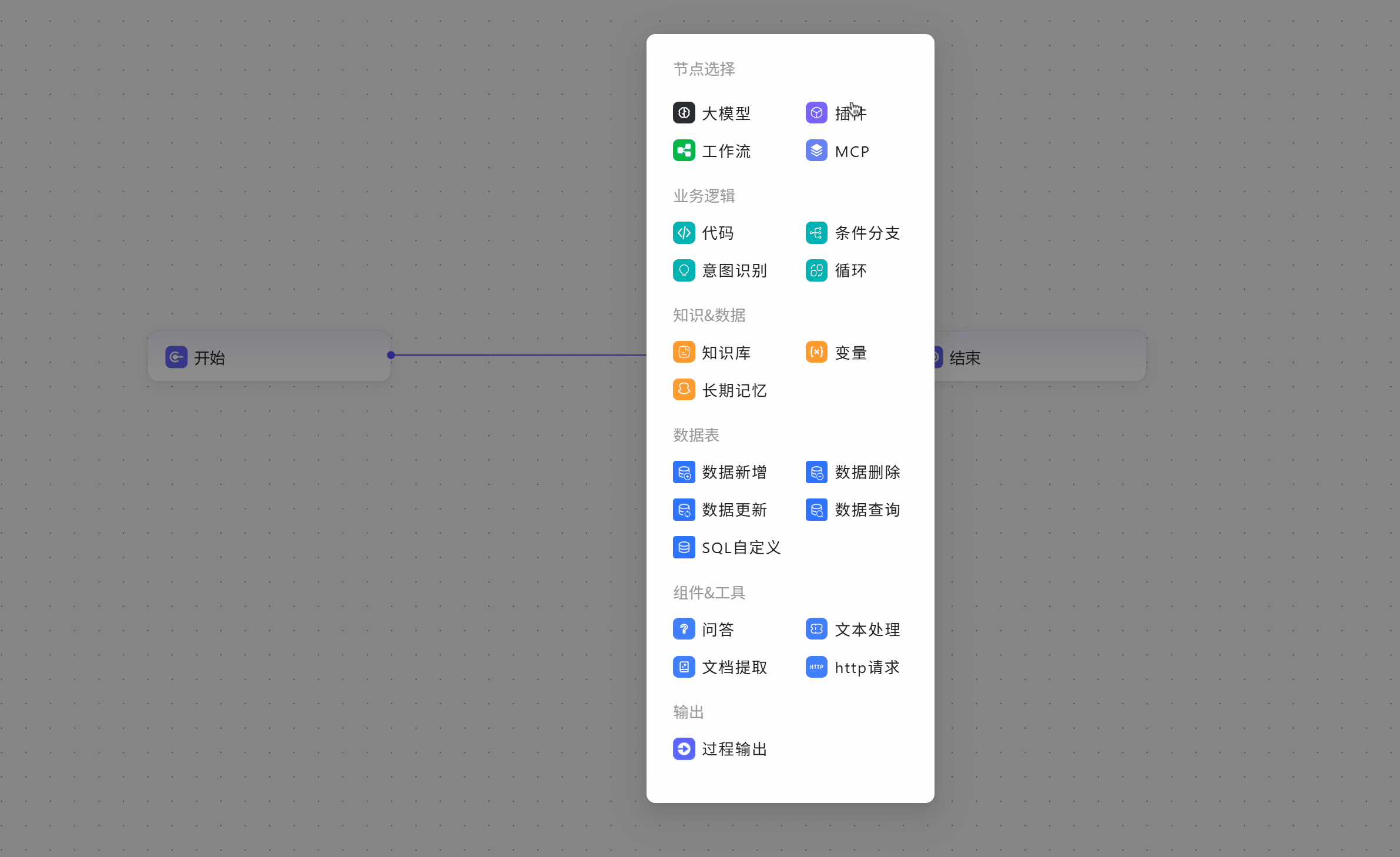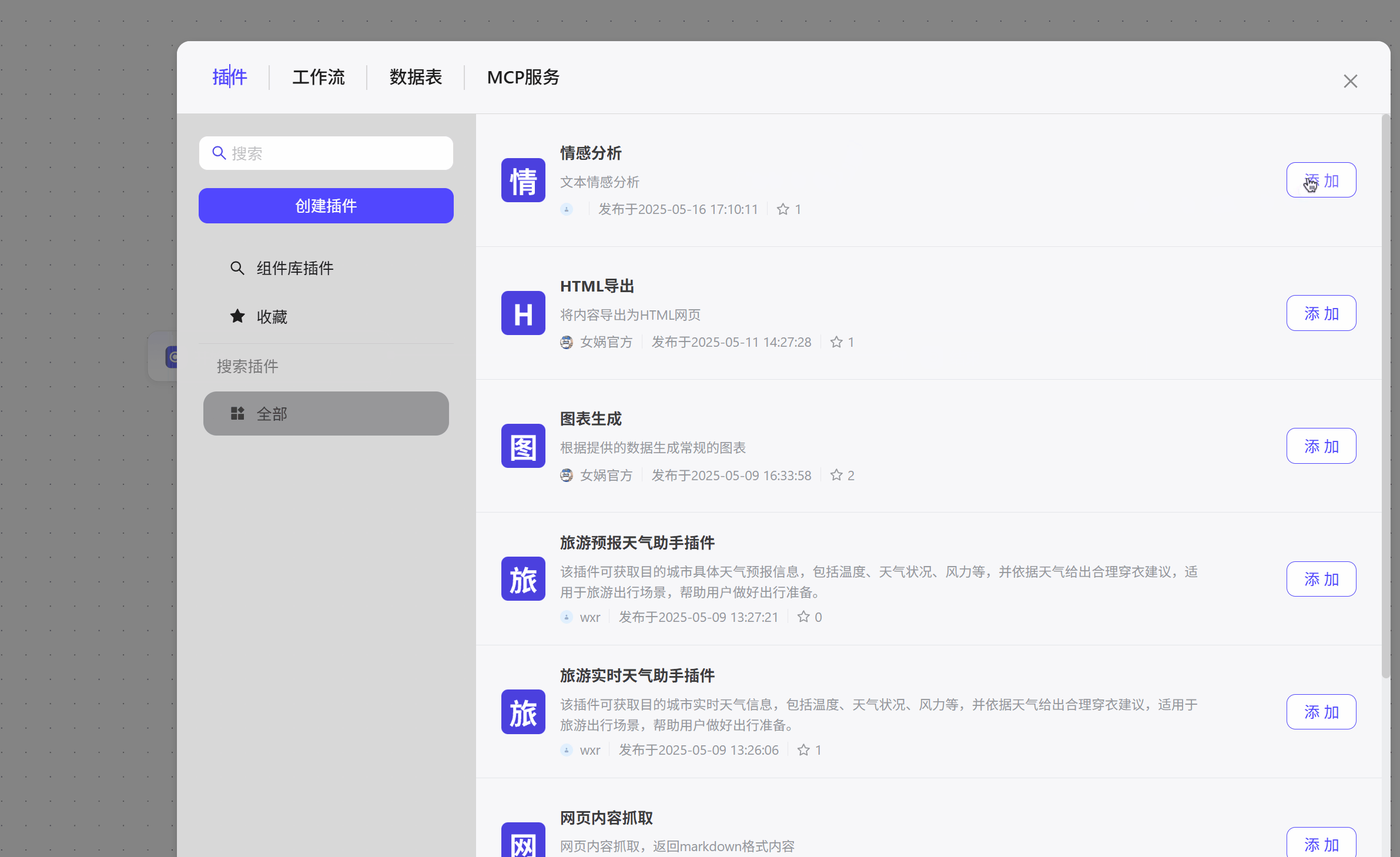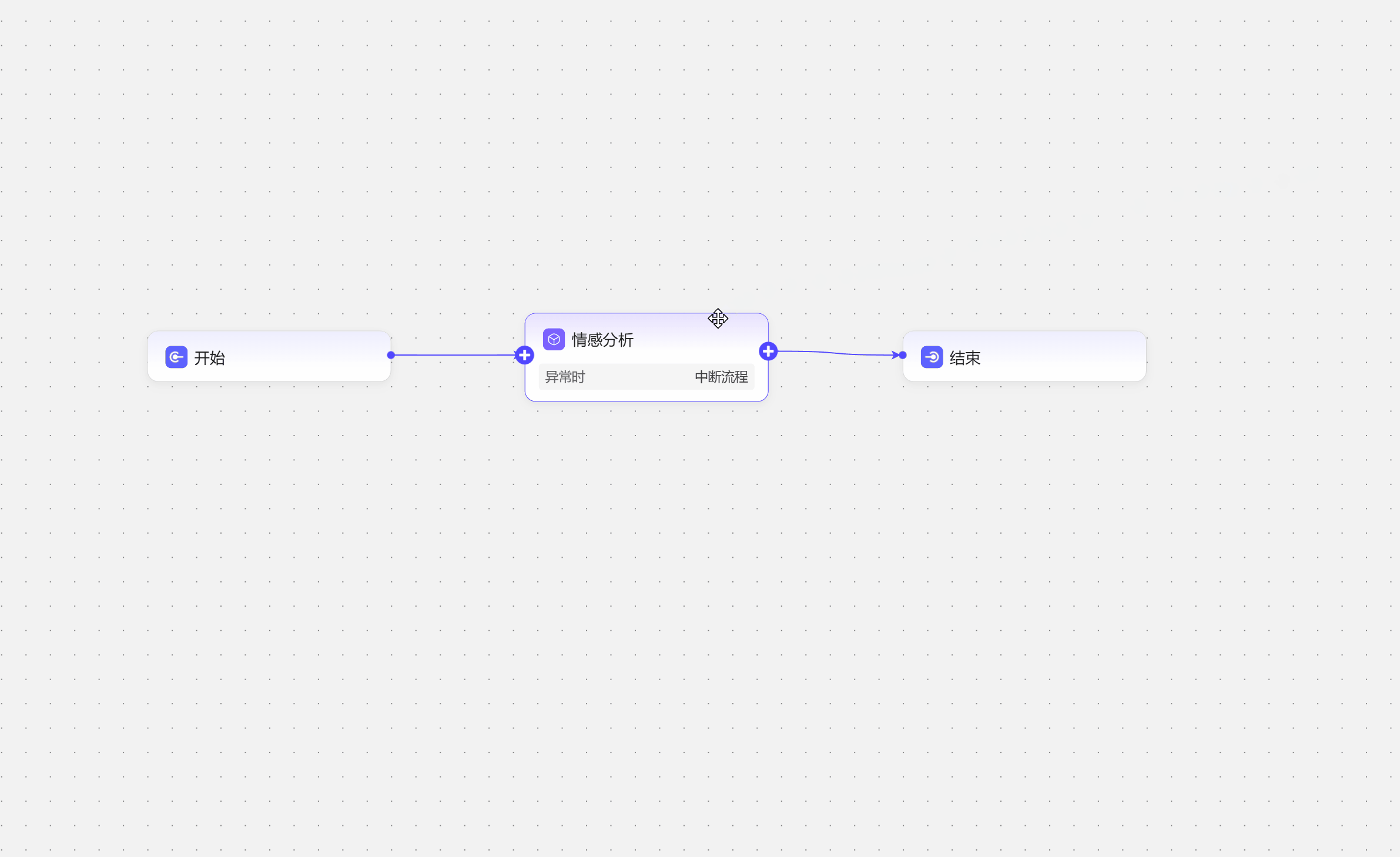 如添加一个情感分析插件。
如添加一个情感分析插件。 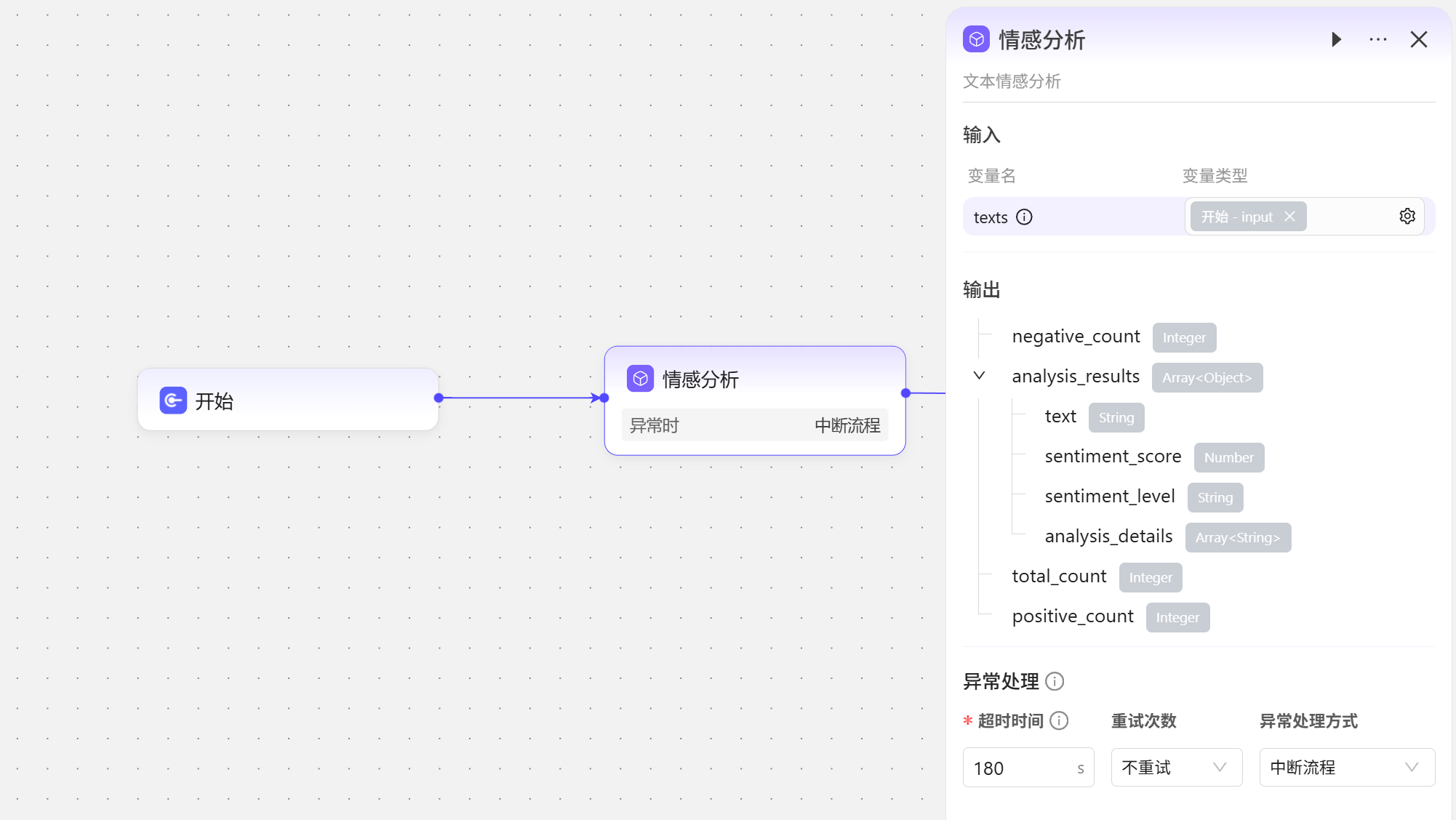 测试结果如下:
测试结果如下: 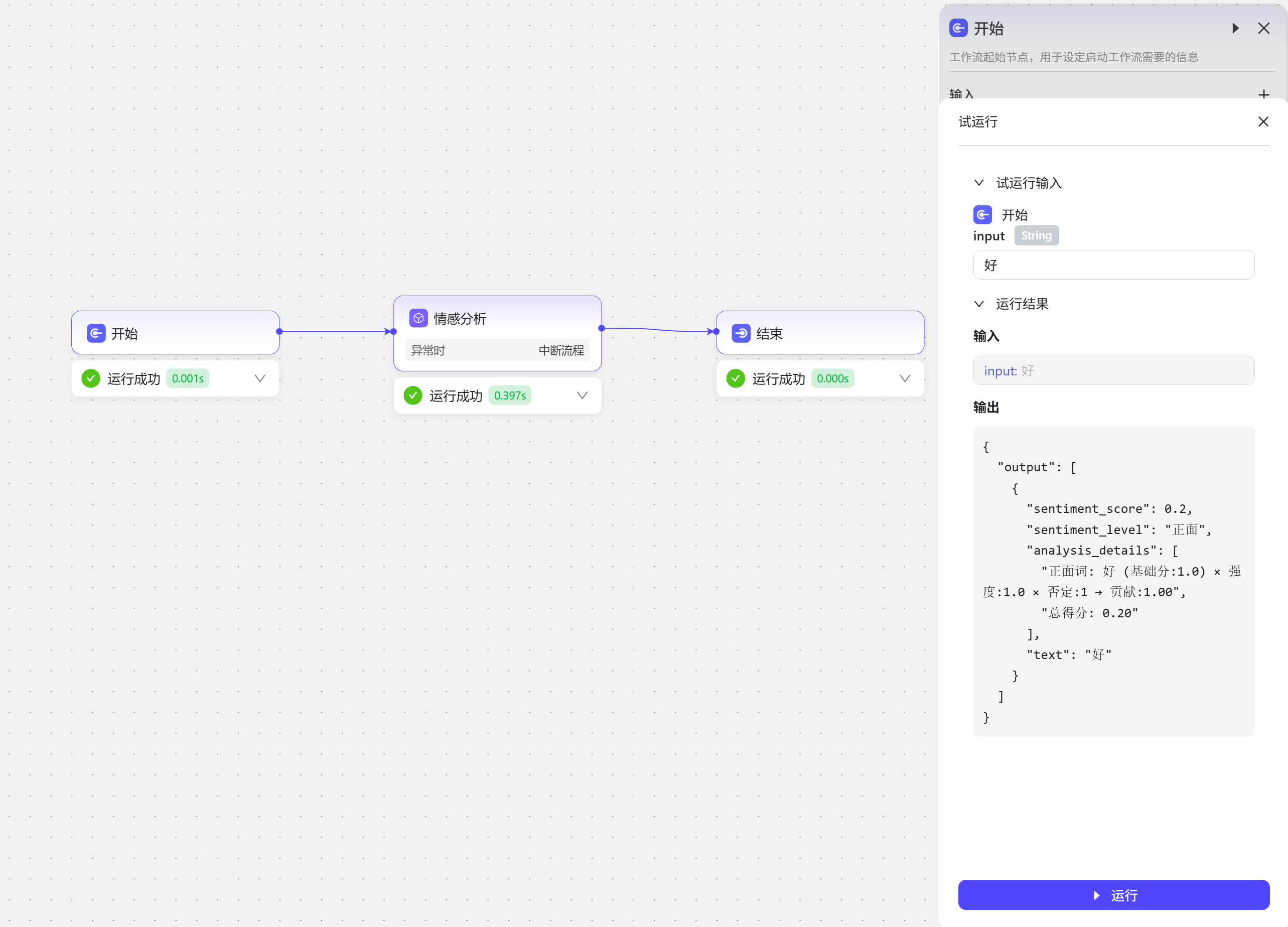
工作流
工作流也可以引用已经发布的工作流,但需要注意如果引用的工作流修改之后可能会影响到当前工作流的任务执行。 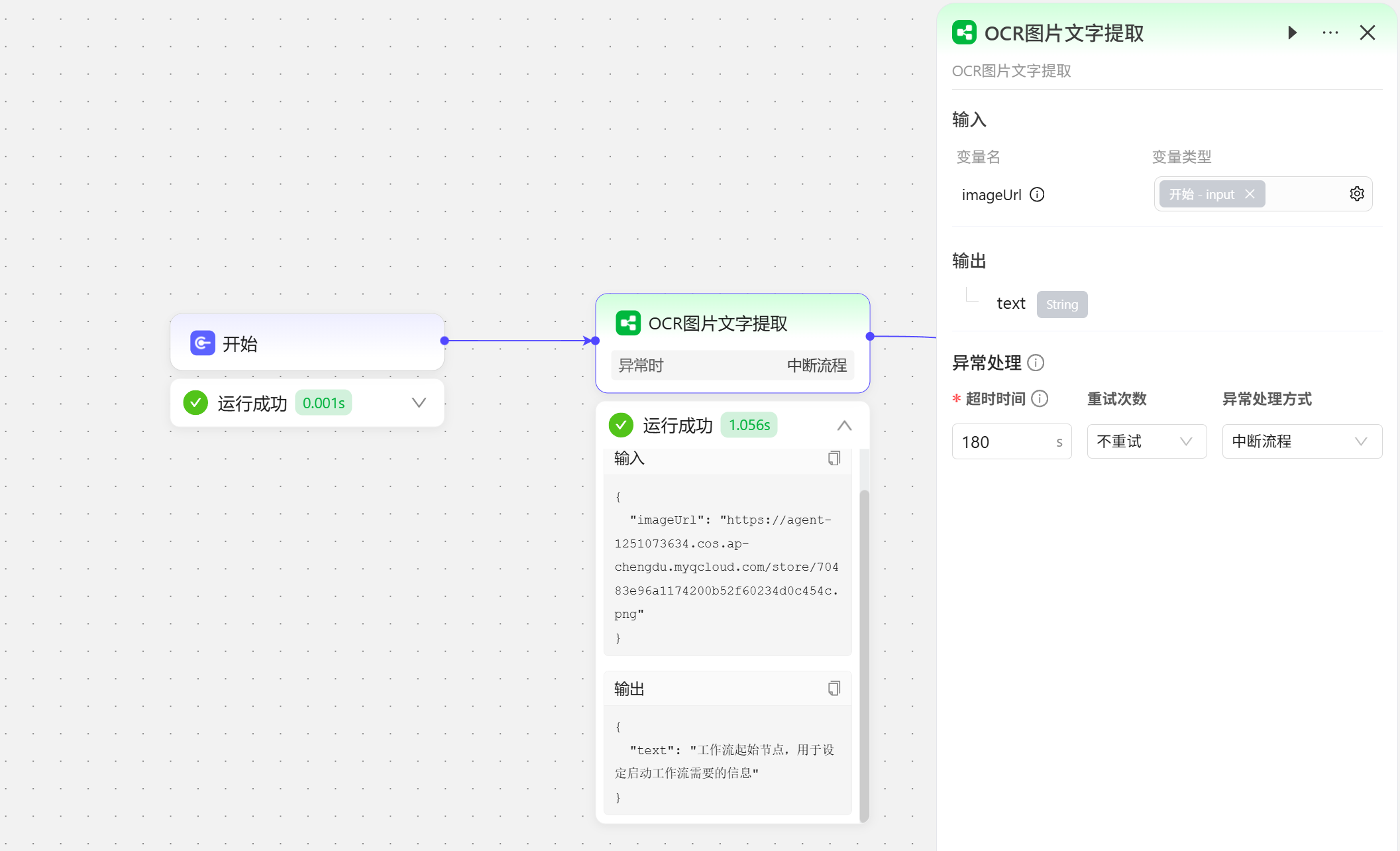
MCP
工作流可以引用创建好的MCP。 
业务逻辑
代码
工作流也支持使用Python和JavaScript代码描述。 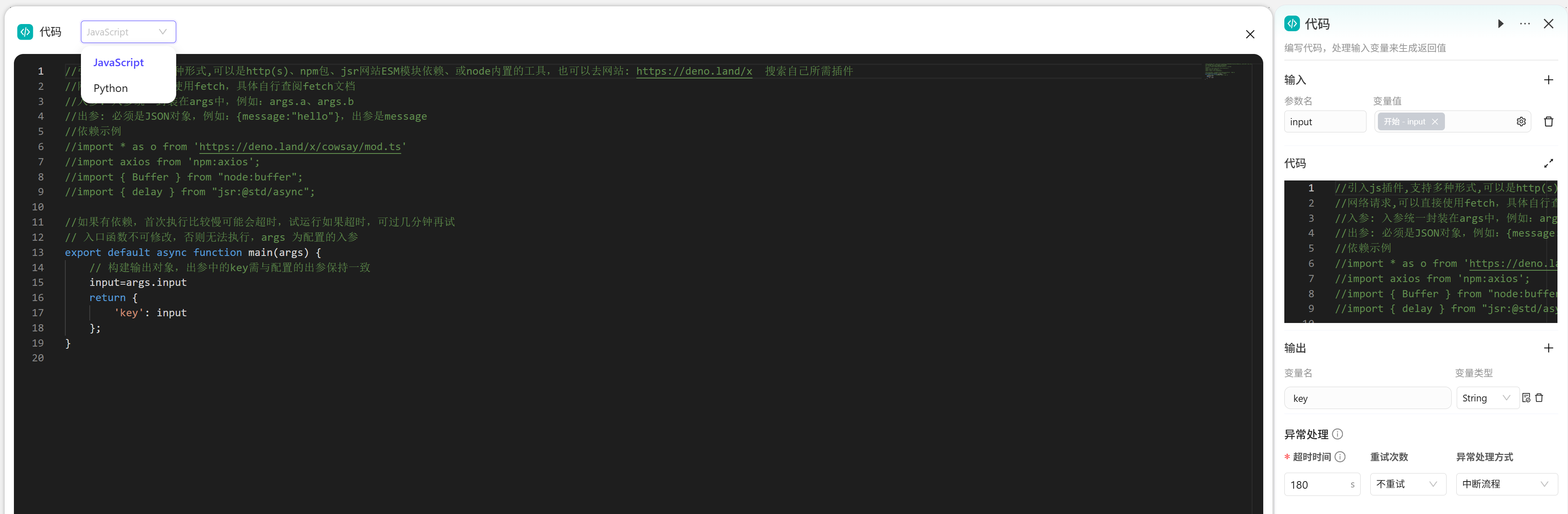
条件分支
条件分支是非常常用的一个节点,我们可以使用条件分支对数据做各种判断,根据数据的情况做不同的处理。
- 单条件比较
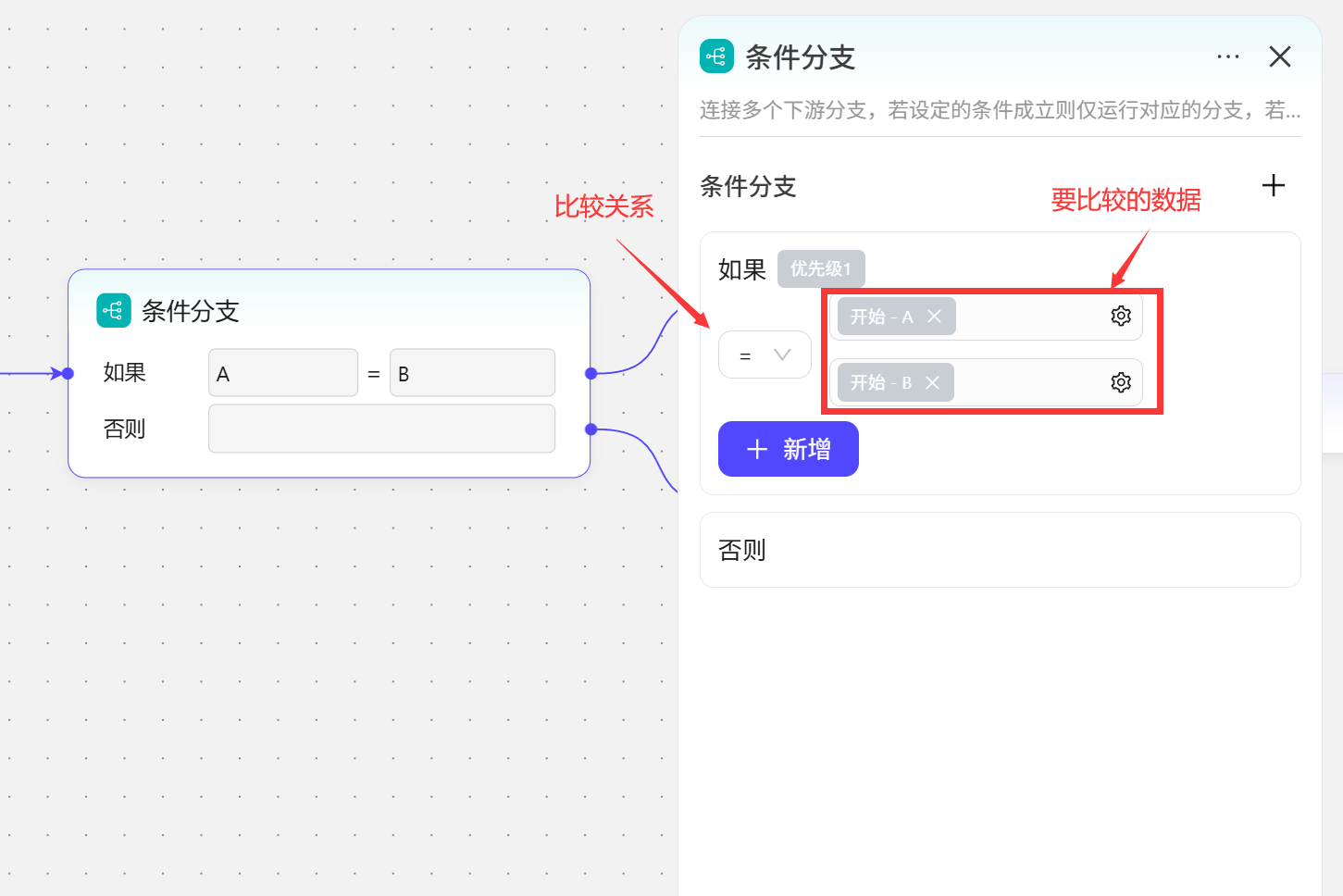 这里在开始节点创建了两个变量,A和B。在条件分支这里比较“A和B的值是否相等”,也就相当于比较表达式
这里在开始节点创建了两个变量,A和B。在条件分支这里比较“A和B的值是否相等”,也就相当于比较表达式A=B,如果A和B相等,就会走上方分支线;如果A和B的值不相等,就会走下方的否则分支线。 A=5,B=5,走结果一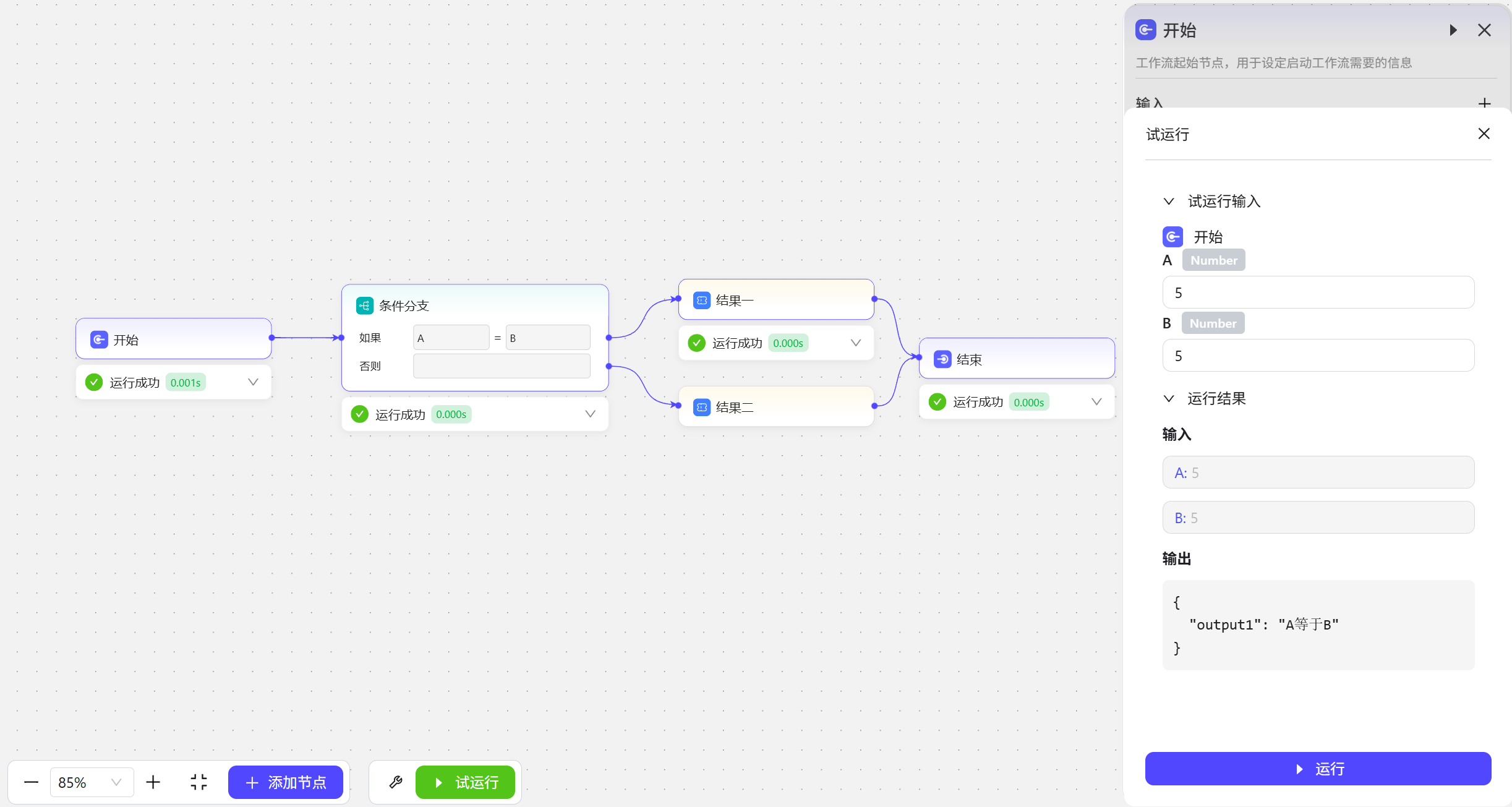 A=5,B=1,走结果二
A=5,B=1,走结果二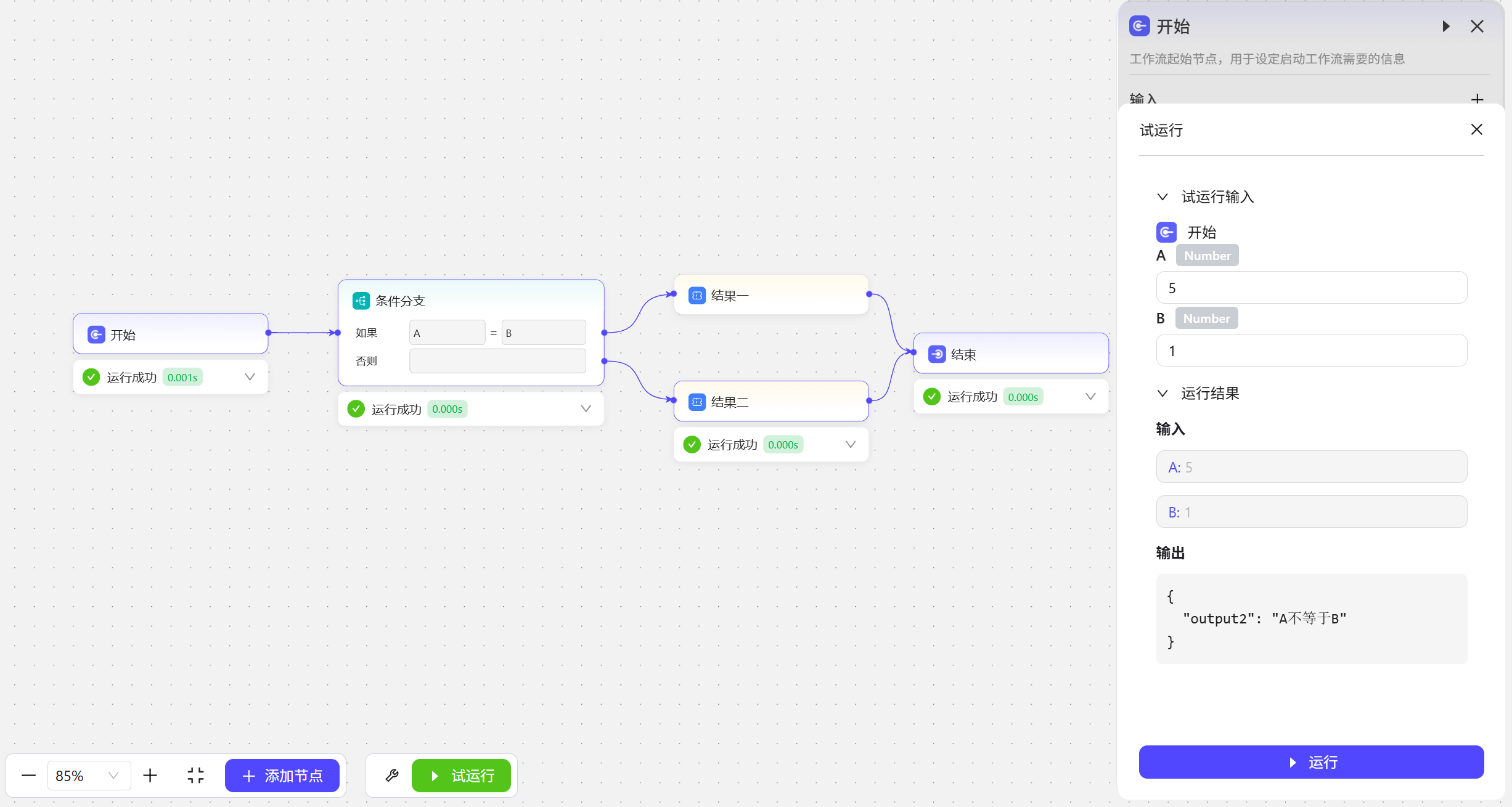
比较关系包括:等于、不等于、大于、大于等于、小于、小于等于、长度大于、长度大于等于、长度小于、长度小于等于、包含、不包含、匹配正则表达式、为空、不为空。
- 多条件比较:且运算:3个比较都成立才会走上方分支线。
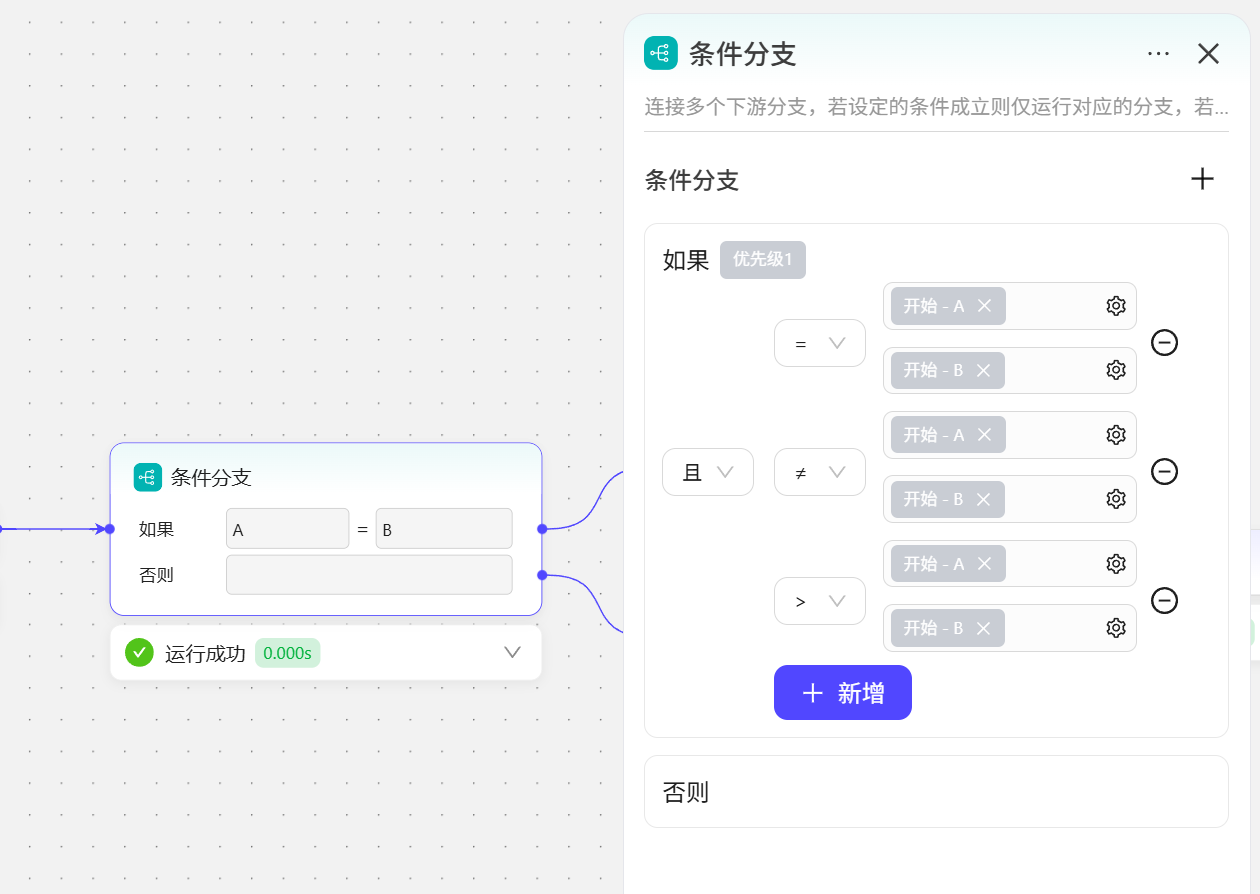 或运算:3个比较中只要有一个比较表达式成立就会走上方分支线。
或运算:3个比较中只要有一个比较表达式成立就会走上方分支线。 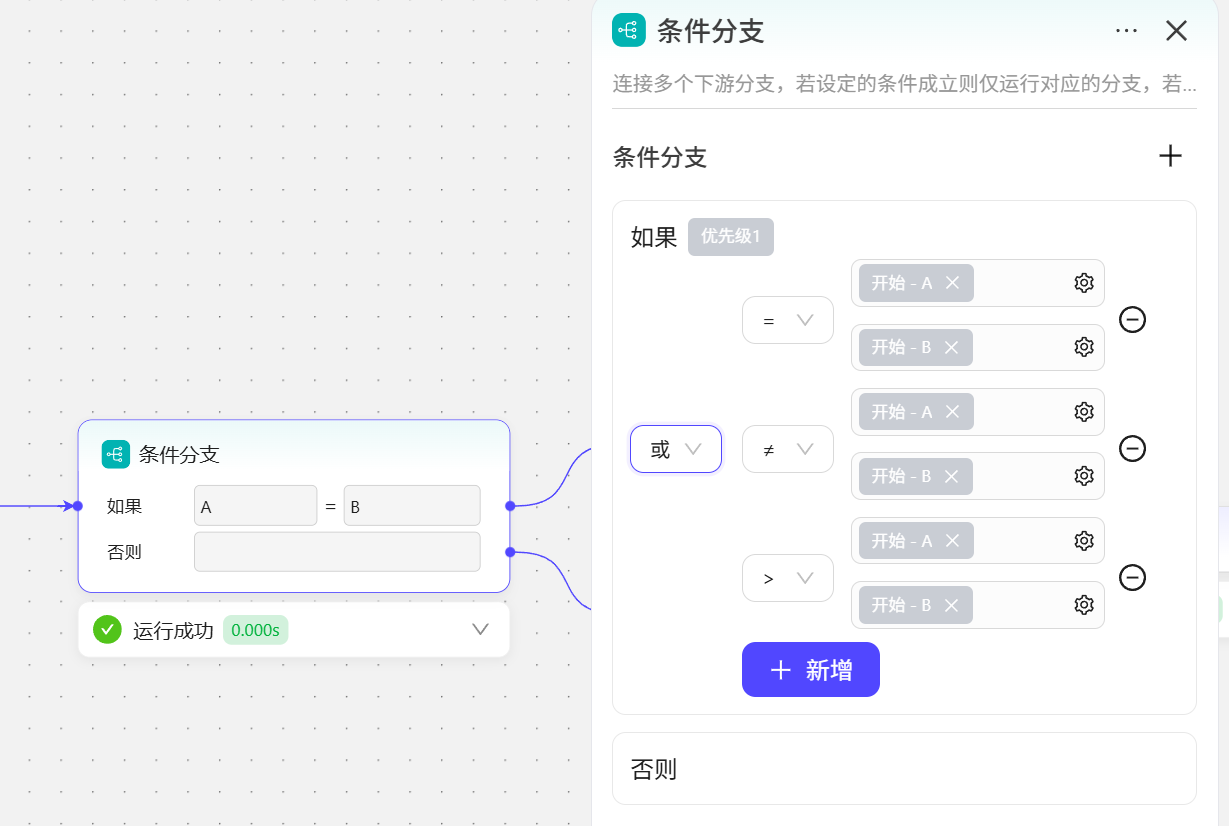
意图识别
根据对话判断用户意图,然后针对用户的意图做专门的流程处理。 模型保持默认即可;在输入处添加输入变量input,这里添加两个意图匹配,A想恋爱、B想去旅游和C其他意图;补充提示词有两个作用,一就是针对意图识别这个节点进行功能设置,二是调用输入的变量 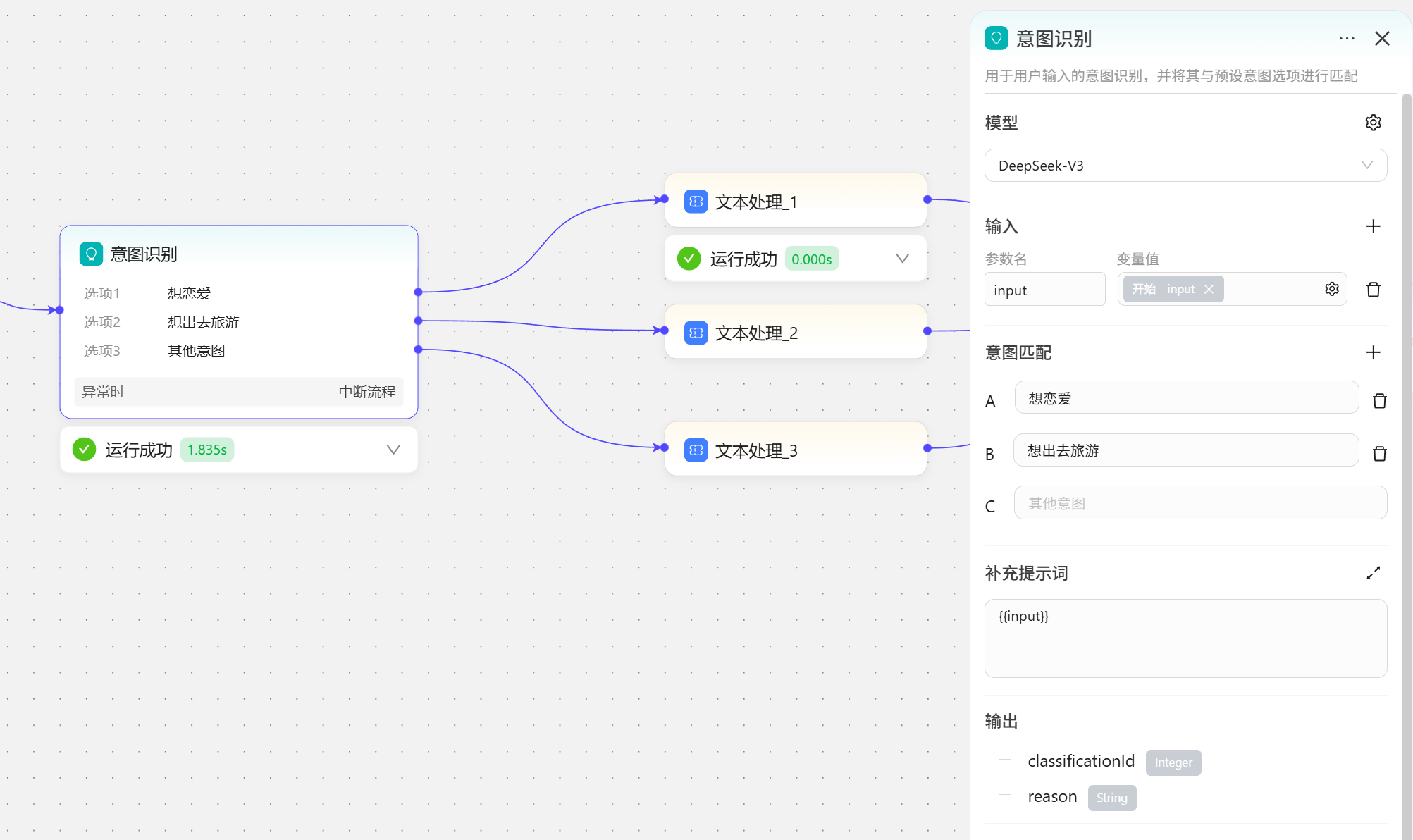 试运行,在开始处输入“想亲嘴”,意图识别节点分析得出结论和A意图匹配,就会走上方分支,这里针对不同的意图对应的返回了一些文本描述。
试运行,在开始处输入“想亲嘴”,意图识别节点分析得出结论和A意图匹配,就会走上方分支,这里针对不同的意图对应的返回了一些文本描述。 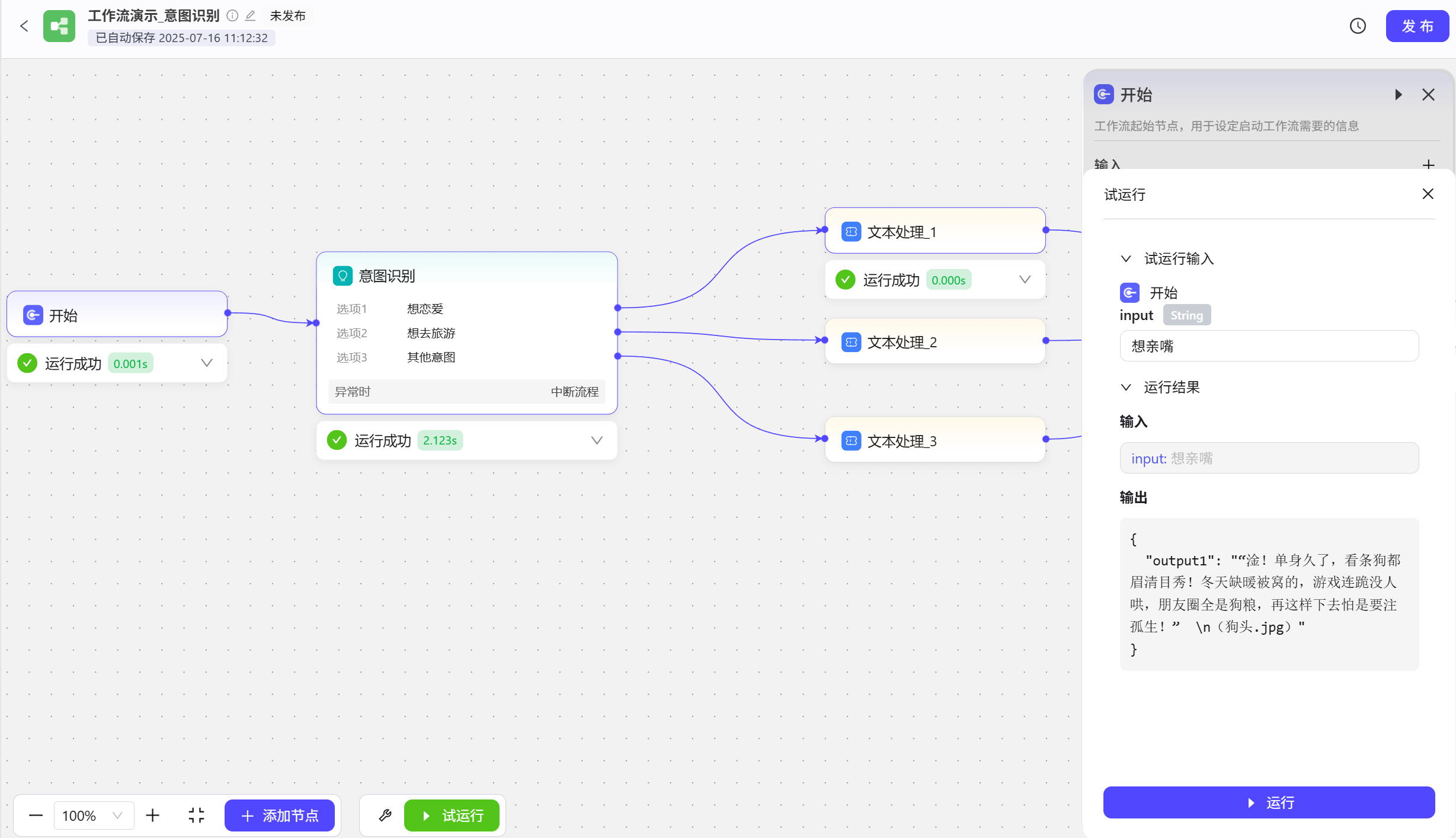
循环
循环共有三种循环设置: 如果引用数组(Array),循环次数为数组的长度; 如果指定次数,循环次数为指定的次数; 如果选择无限循环,需配合“终止循环”节点完成循环流程。 如,模拟数据5个人名,我们来让大模型给这些人物配上一个小故事
- 在开始节点创建变量
names,设置变量类型为Array<String>表示这里使用的是数组,数组中存储的都是文本型数据String。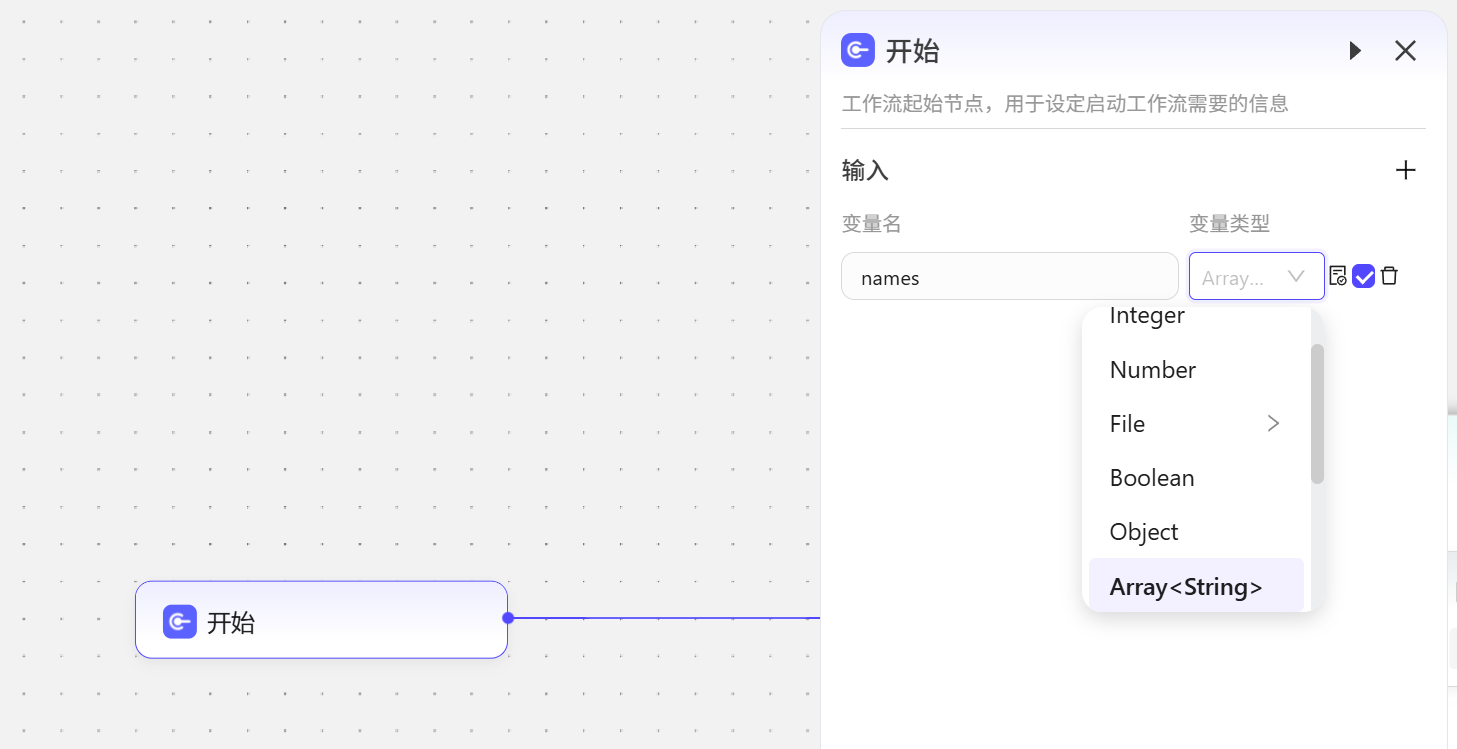
- 添加循环节点,在循环
单次开始和单次结束的中间添加大模型,选中循环,循环设置为使用数组循环,添加循环数组,选择开始节点的names变量,添加输出变量,输出变量引用大模型的结果。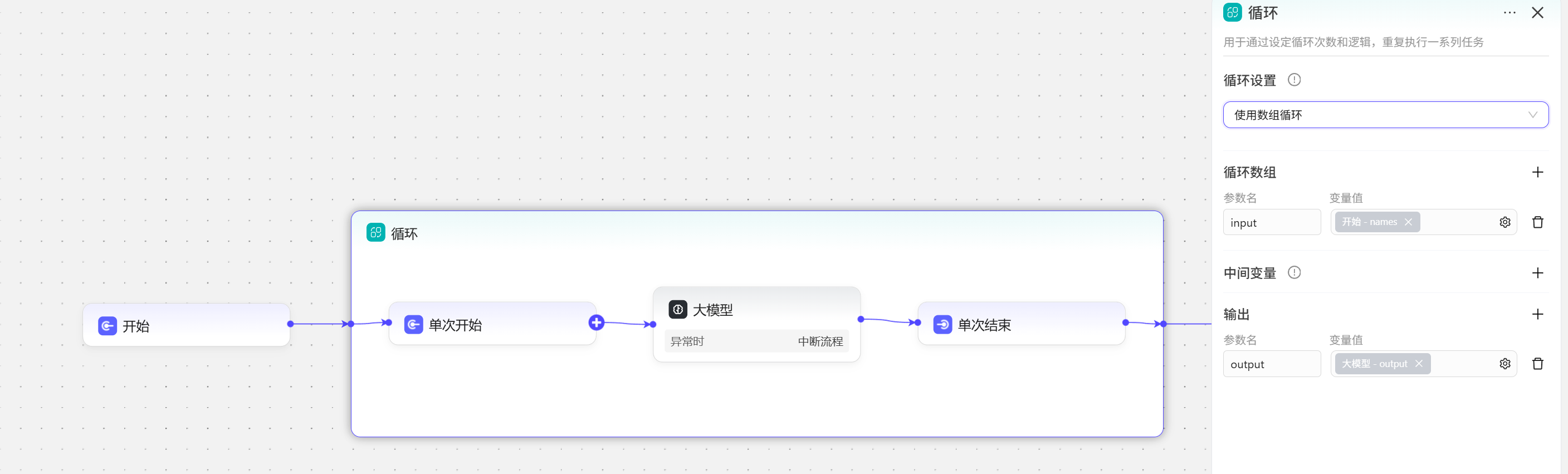
- 大模型的设置界面中首先添加输入变量
input_item,这里使用的是循环中的input_item,也就是取数组中的多个人名中的一个出来给大模型进行处理。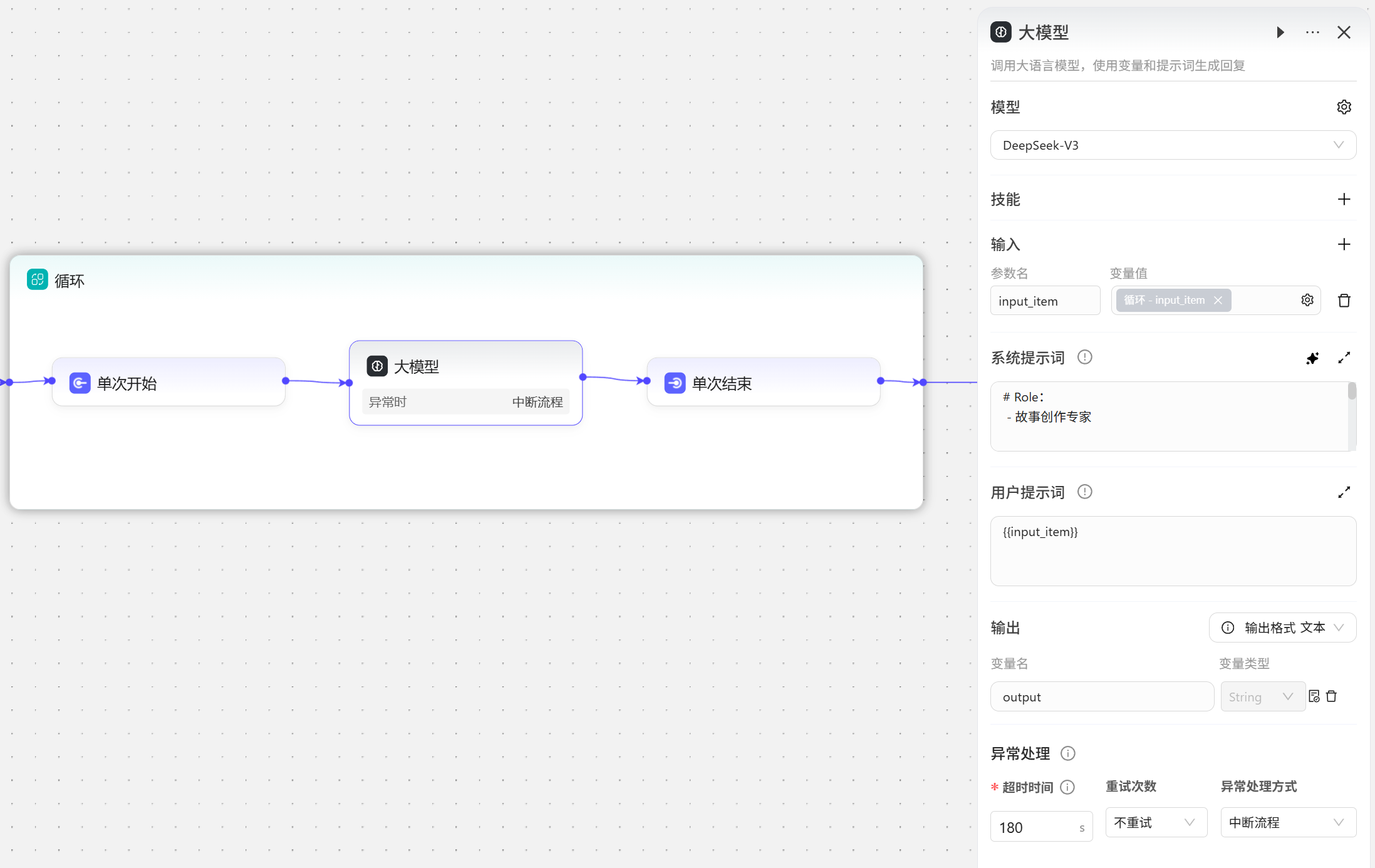
- 结束节点就把循环节点的输出做一个展示即可。
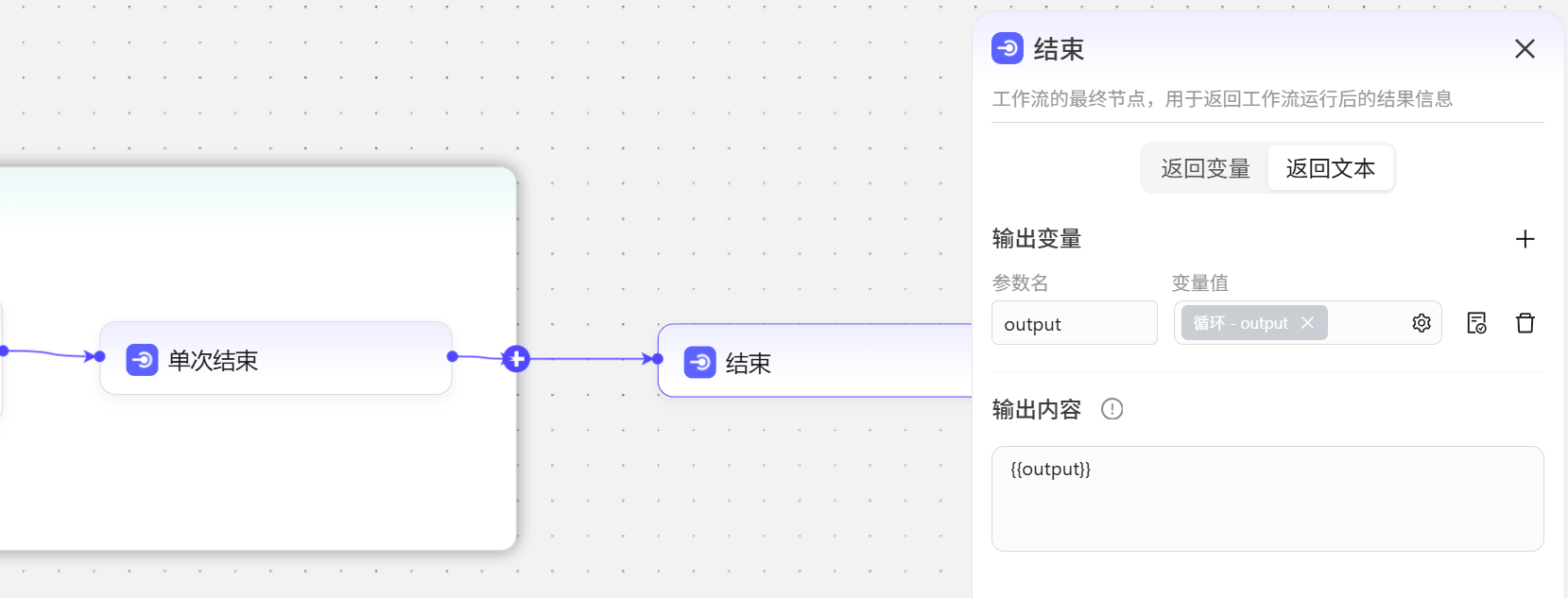
- 试运行后的结果。
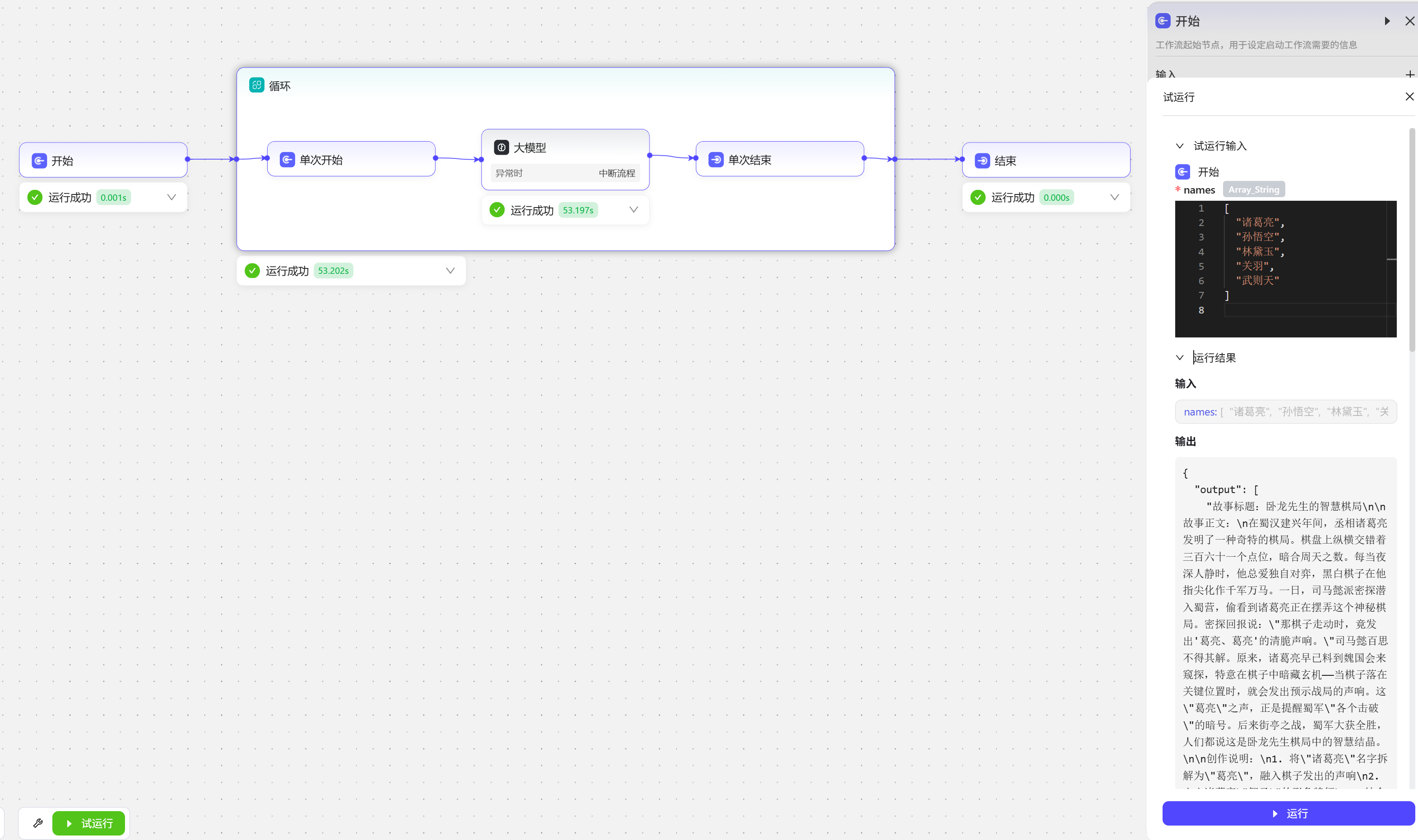
- 为了方便展示我在智能体中添加了两个节点,可以将内容转化成网页形式,方便大家查看。
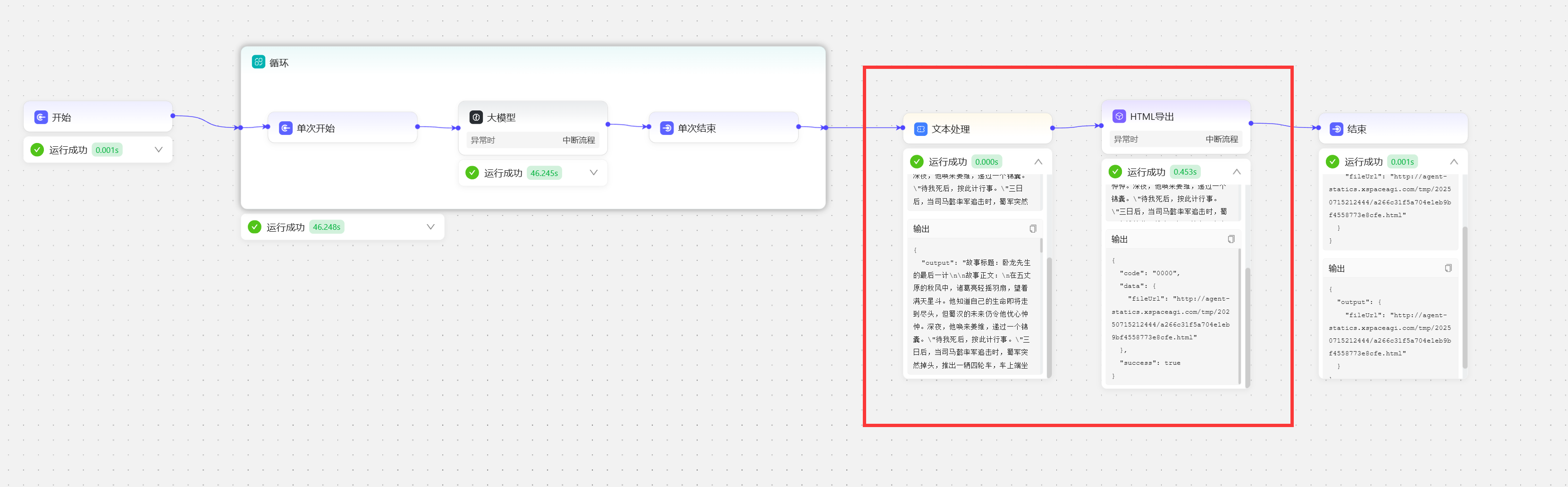 结果:生成内容的网页形式。
结果:生成内容的网页形式。 循环遍历数组是智能体开发中最常用用法之一。
知识&数据
知识库
这里仅讲解在工作流中如何使用知识库,知识库的创建等内容请查看链接。
- 输入 输入变量引用
开始节点的input作为检索知识库的关键词。 - 知识库 知识库设置为之前创建好的“手机产品信息”知识库。
- 搜索策略:从知识库中获取知识的检索方式,不同的检索策略可以更有效地找到正确的信息,提高其生成的答案的准确性和可用性
- 混合:结合全文检索与语义检索的优势,并对结果进行综合排序。
- 语义:基于向量的文本相关性查询,推荐在需要理解语义关联度和跨语言查询的场景使用。
- 全文:依赖于关键词的全文搜索,推荐在搜索具有特定名称、缩写词、短语或ID的场景使用。
- 最大召回数量:从知识库中返回给大模型的最大段落数,数值越大返回的内容越多
- 最小匹配度:根据设置的匹配度选取段落返回给大模型,低于设定匹配度的内容不会被召回
- 输出:输出固定为对象数组
Array<Object>,Object对象中主要包含两个String类型的变量,一个是查询关键词后返回的原始数据rawText;一个是对查询关键词返回的原始数据进行整理后的结果output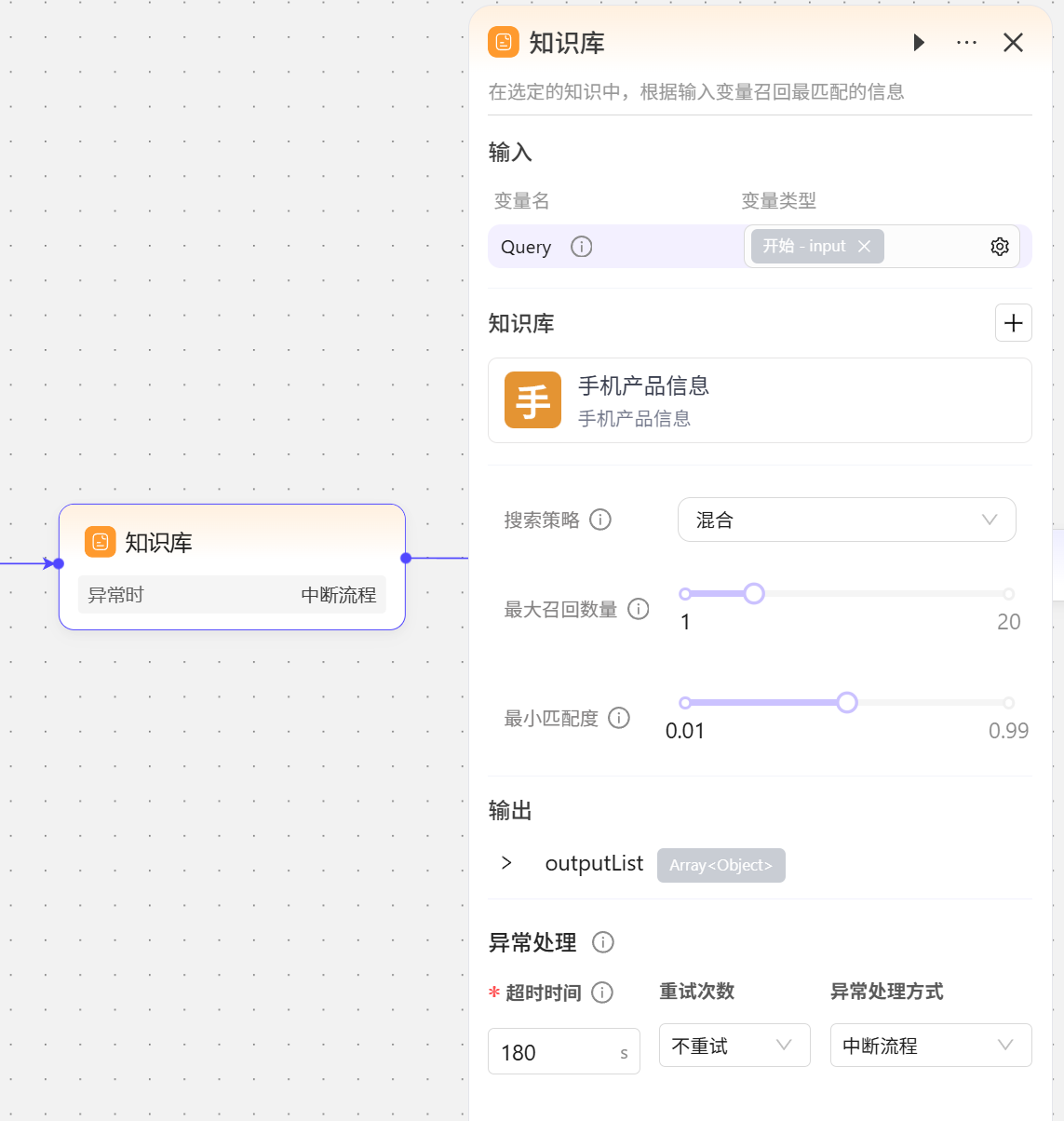
- 试运行
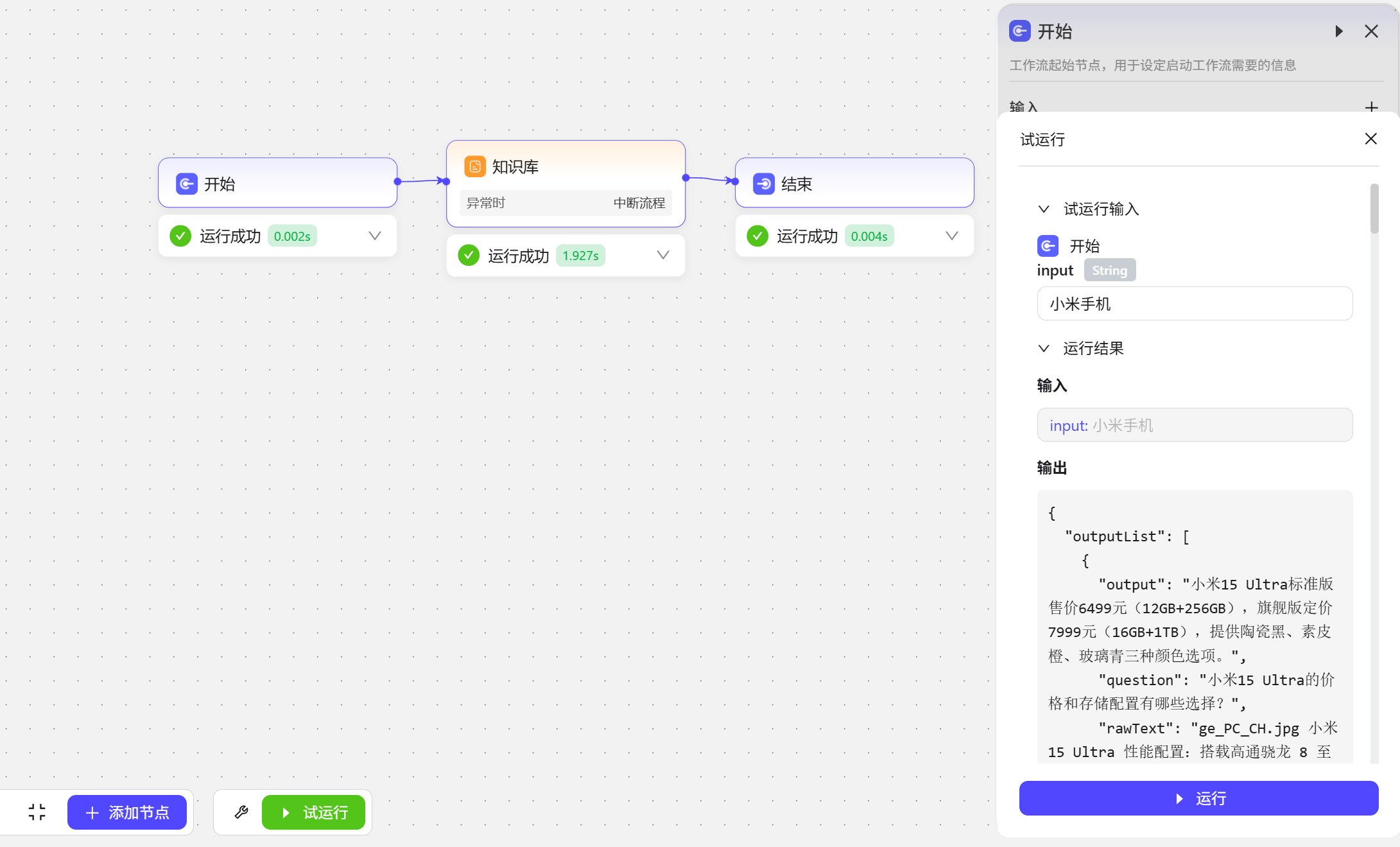
变量
变量节点主要有两个功能设置变量值和获取变量值,需要注意的是通过变量节点获取或者设置的变量是一个全局变量,也就是可以在创建变量之后的任意节点直接使用变量名来调用变量。
- 获取变量值:最常用的使用方法,就是获取外部智能体中设置的变量
- 在智能体中创建变量
name用来存储会话中用户输入的姓名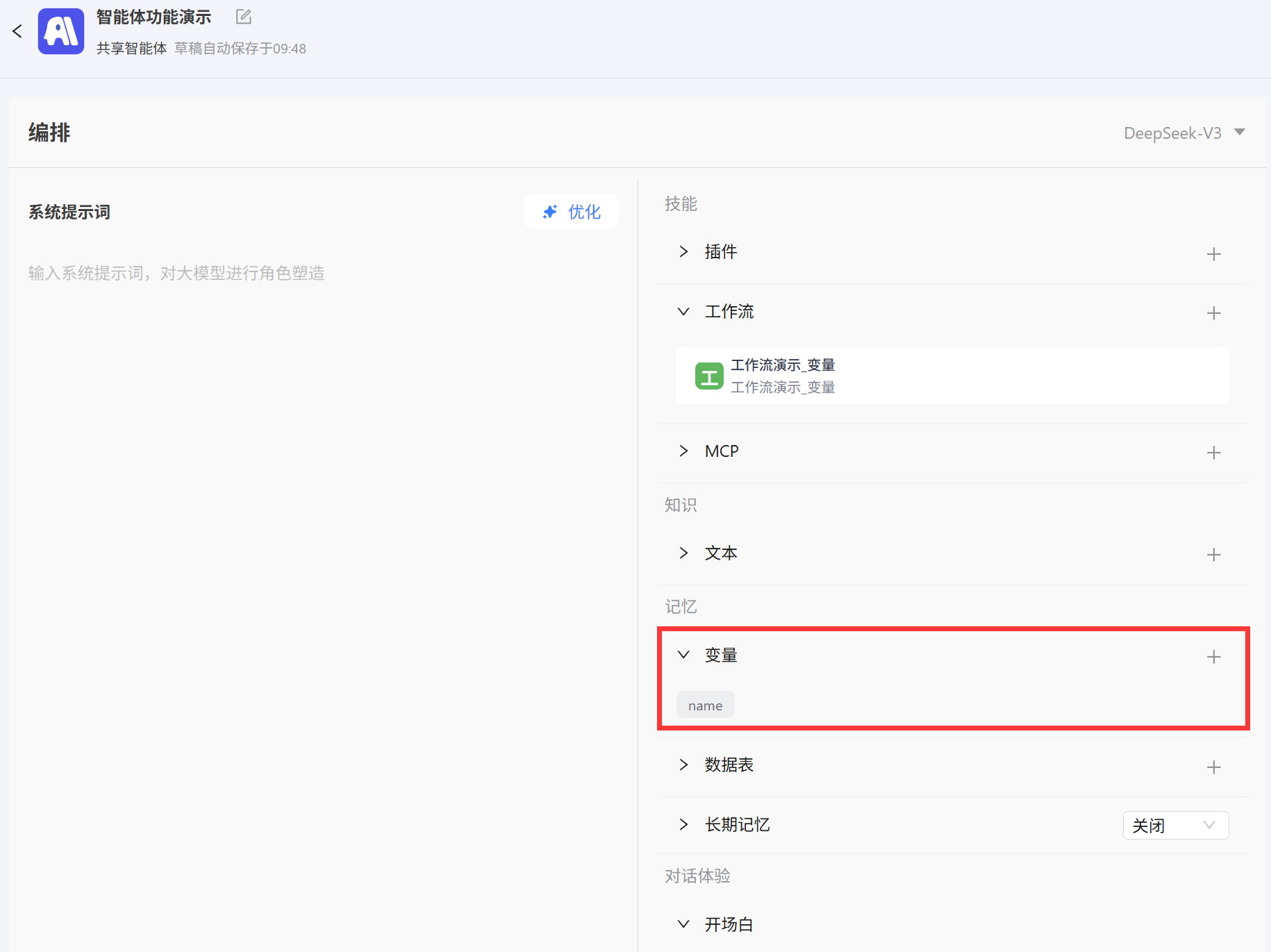
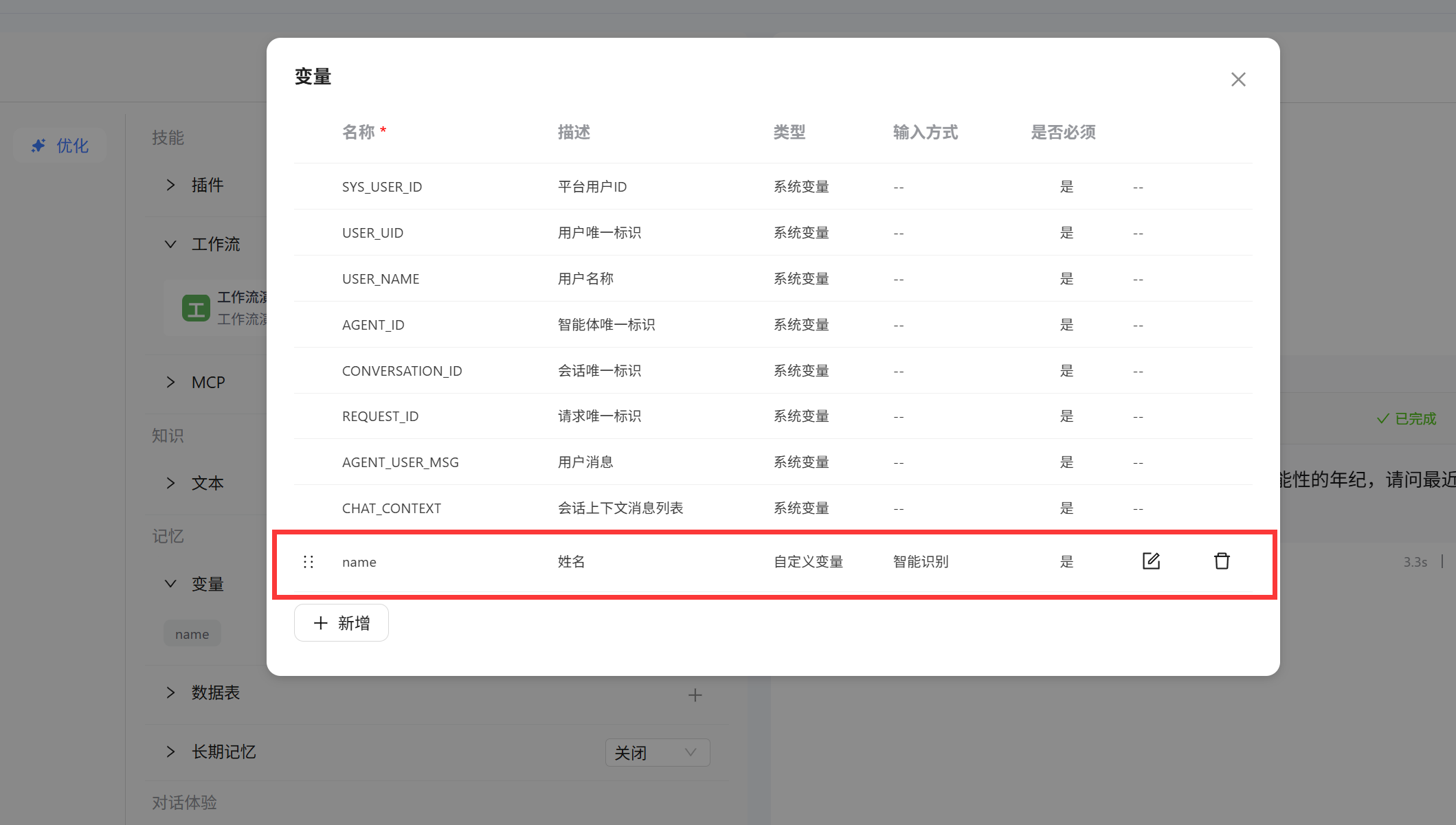
- 在工作流中设置一个
变量节点,选择获取变量值,变量值中填写要引用的外部智能体变量名称name,这里的参数名就是我们要在工作流中使用的变量名称,这里就会把name变量的值传递给getname变量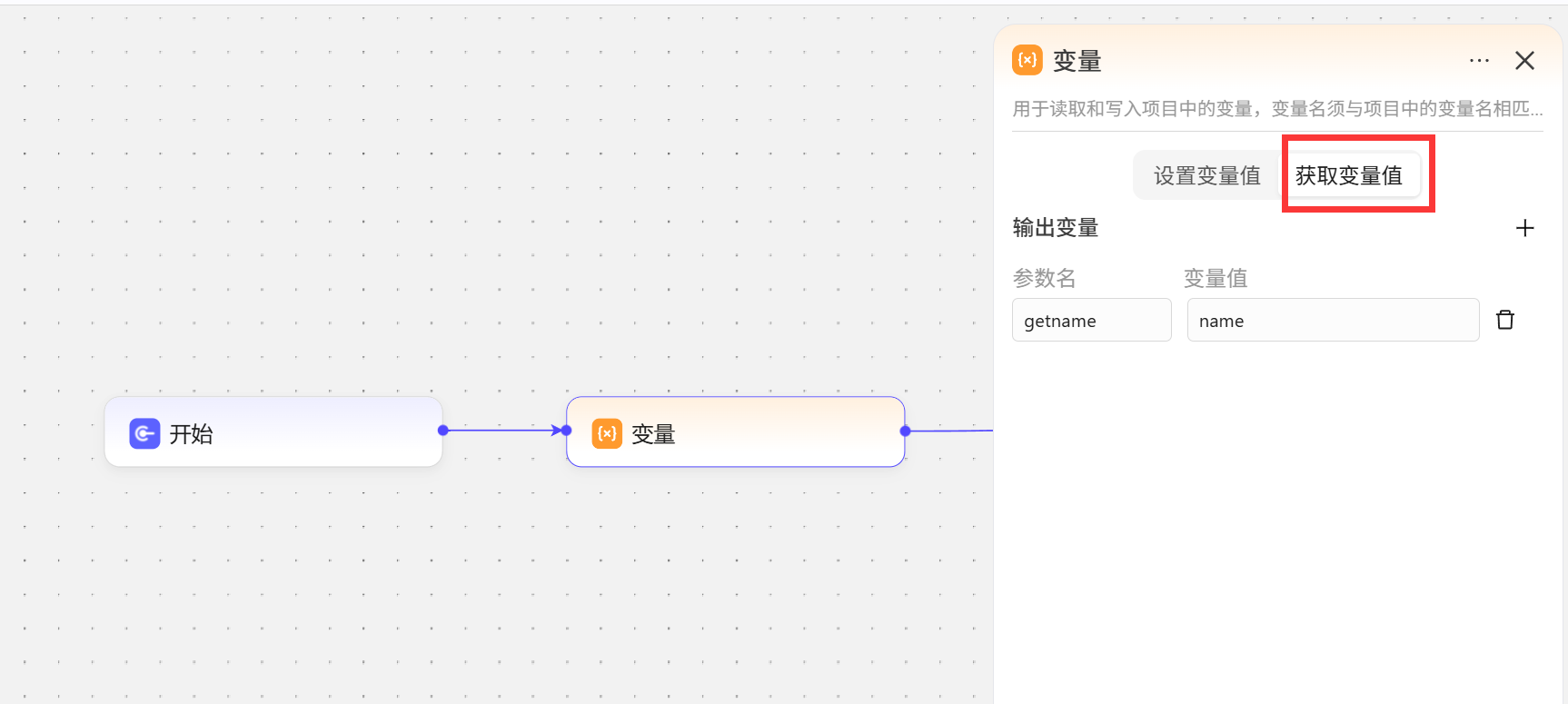 在结束节点中,直接将获取到的姓名输出
在结束节点中,直接将获取到的姓名输出 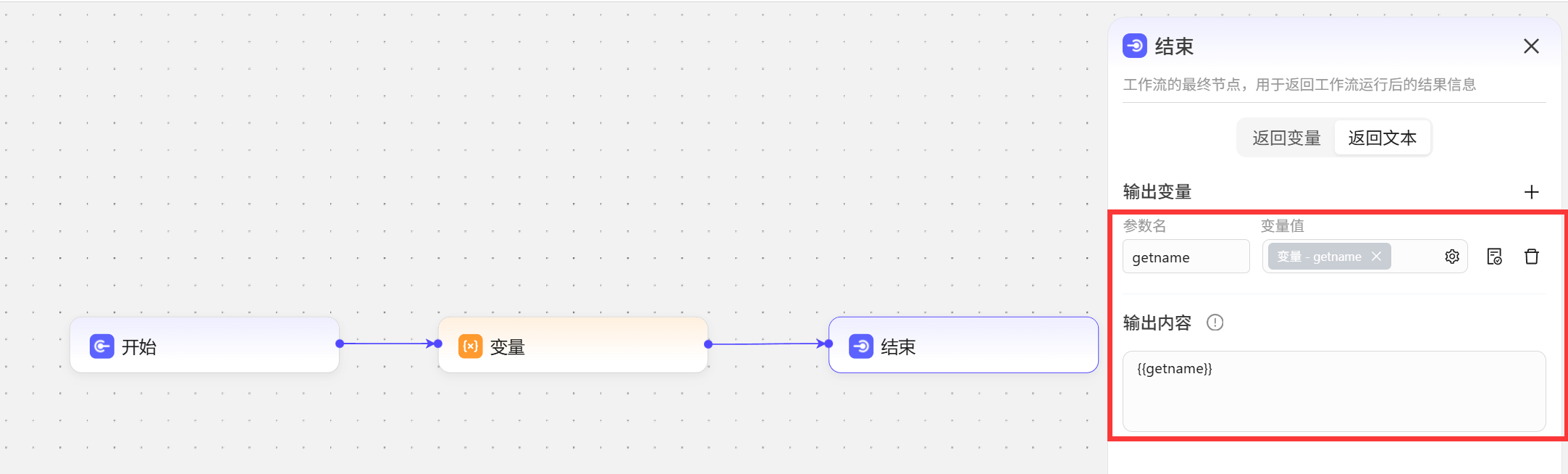
- 在智能体中测试下,看下结果,在输入对话之后,智能体首先识别到用户姓名,调用变量设置功能将姓名李四存入到了
name变量中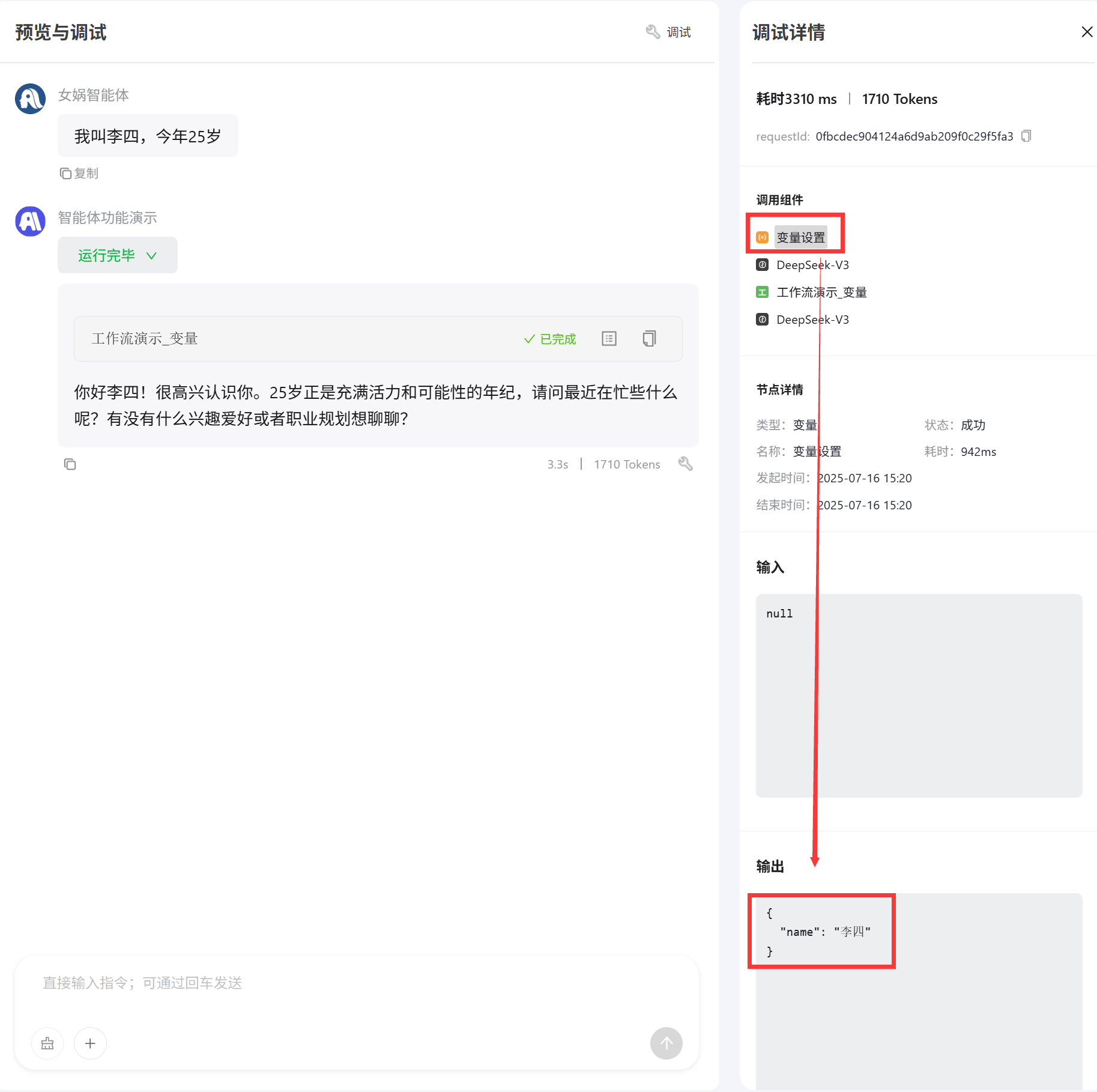 然后智能体会调用工作流,将智能体创建的
然后智能体会调用工作流,将智能体创建的name变量的值传递给了工作流中的变量节点,最后输出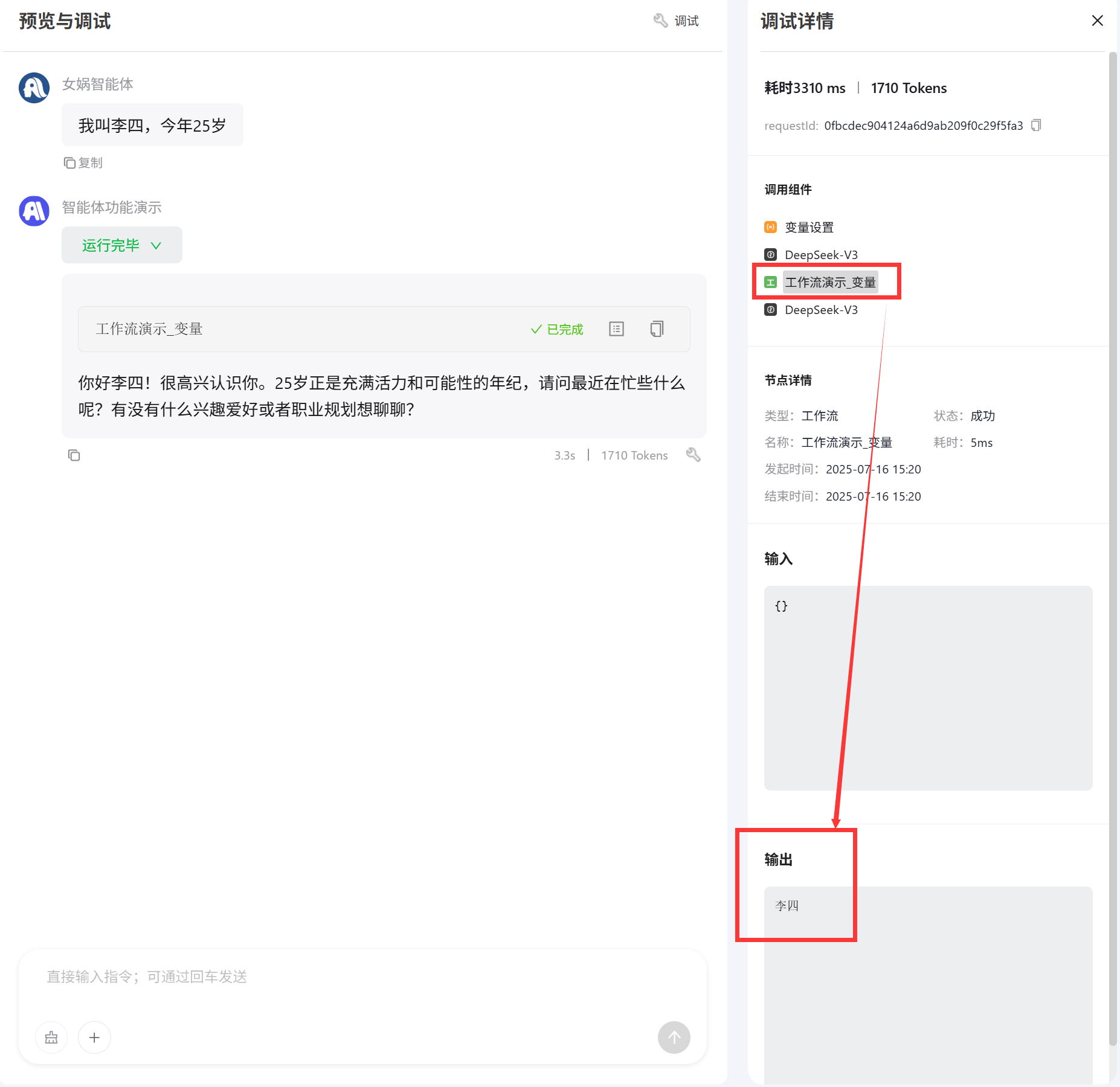
- 在智能体中创建变量
- 设置变量值:可以理解成给变量赋值,这里我们用一个成语接龙工作流来展示这个功能
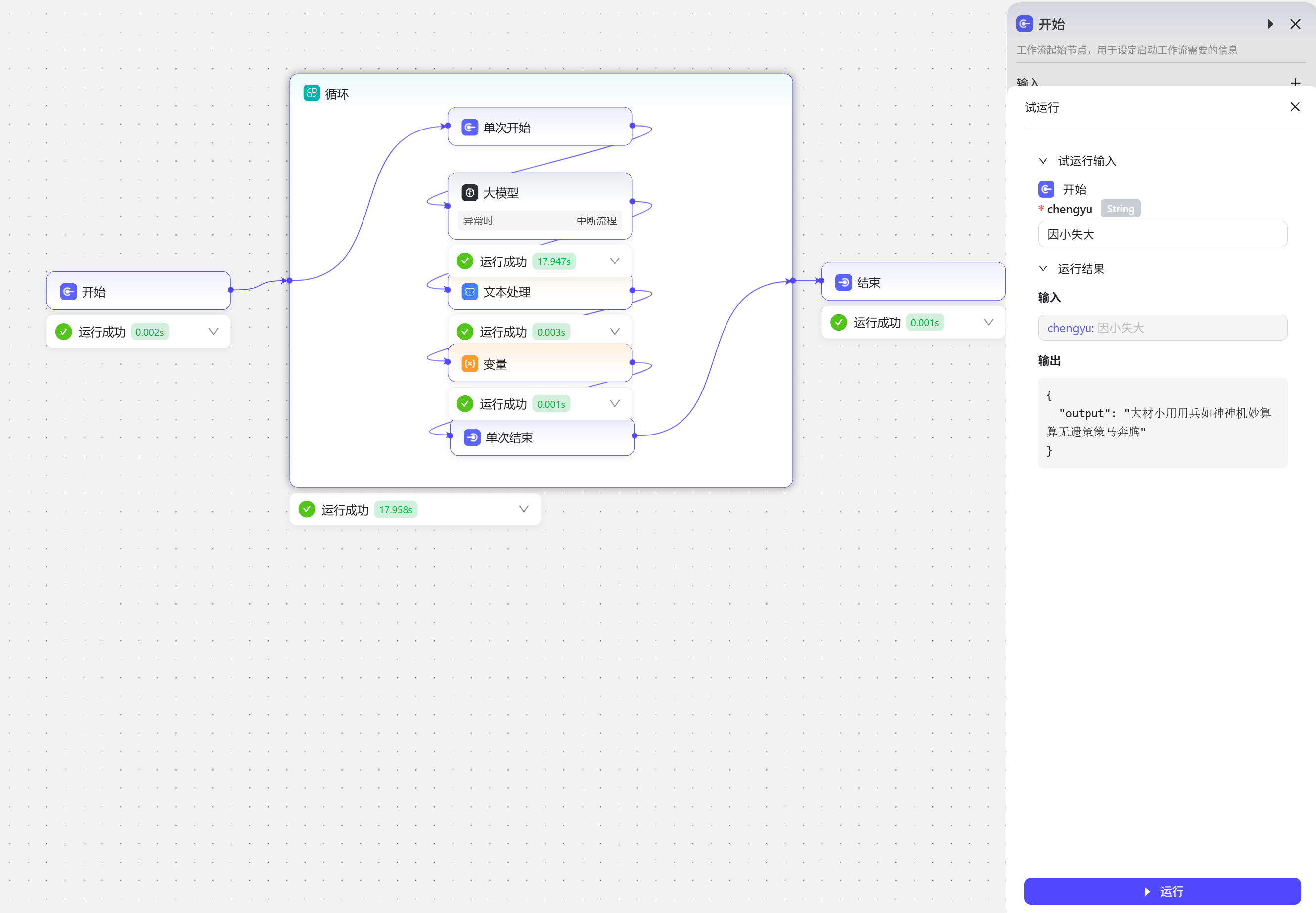
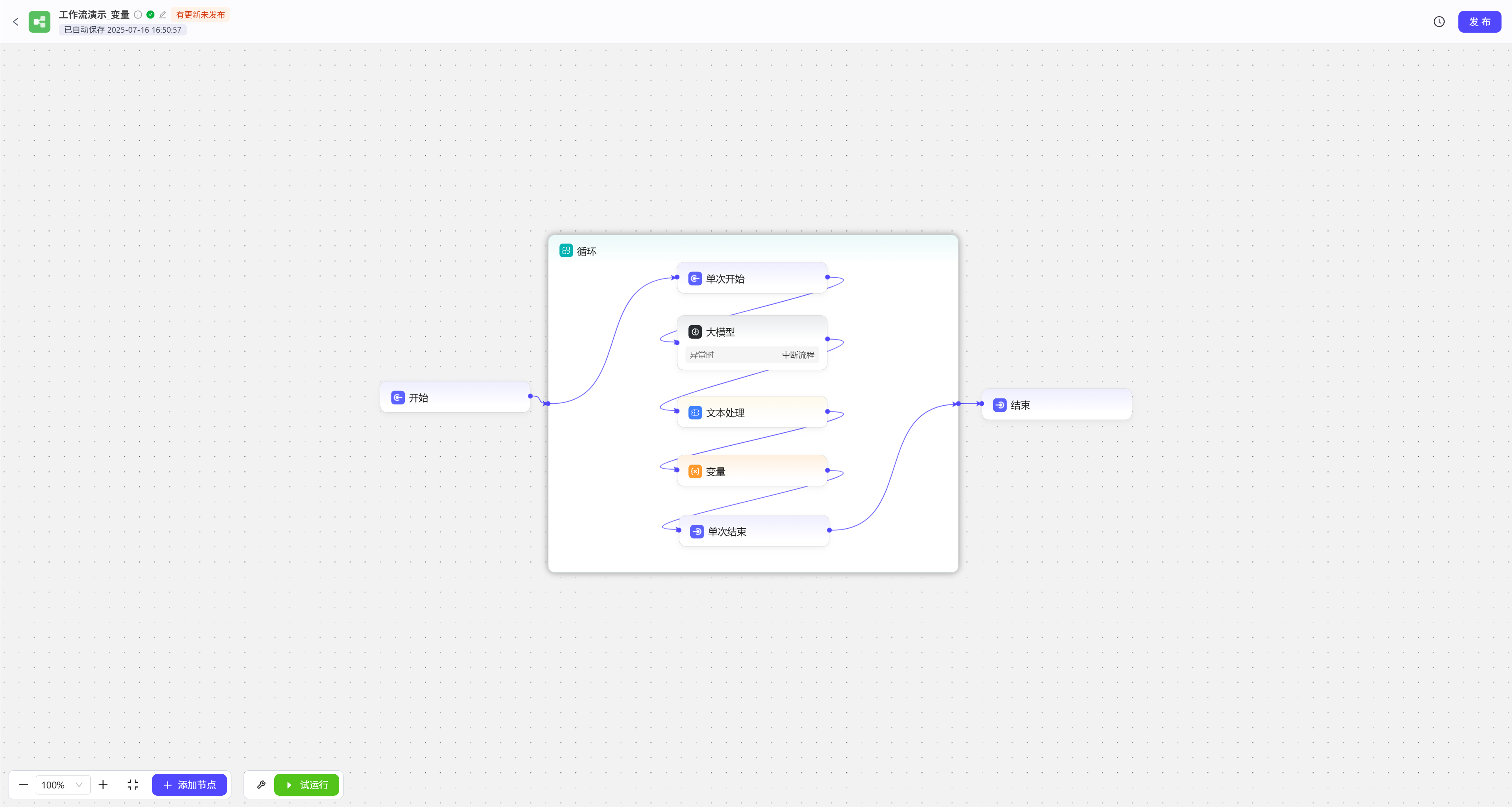 我们在开始节点中输入一个成语,循环会自己跟自己接龙五次后会把所有接龙的成语串成一个句子输出。
我们在开始节点中输入一个成语,循环会自己跟自己接龙五次后会把所有接龙的成语串成一个句子输出。 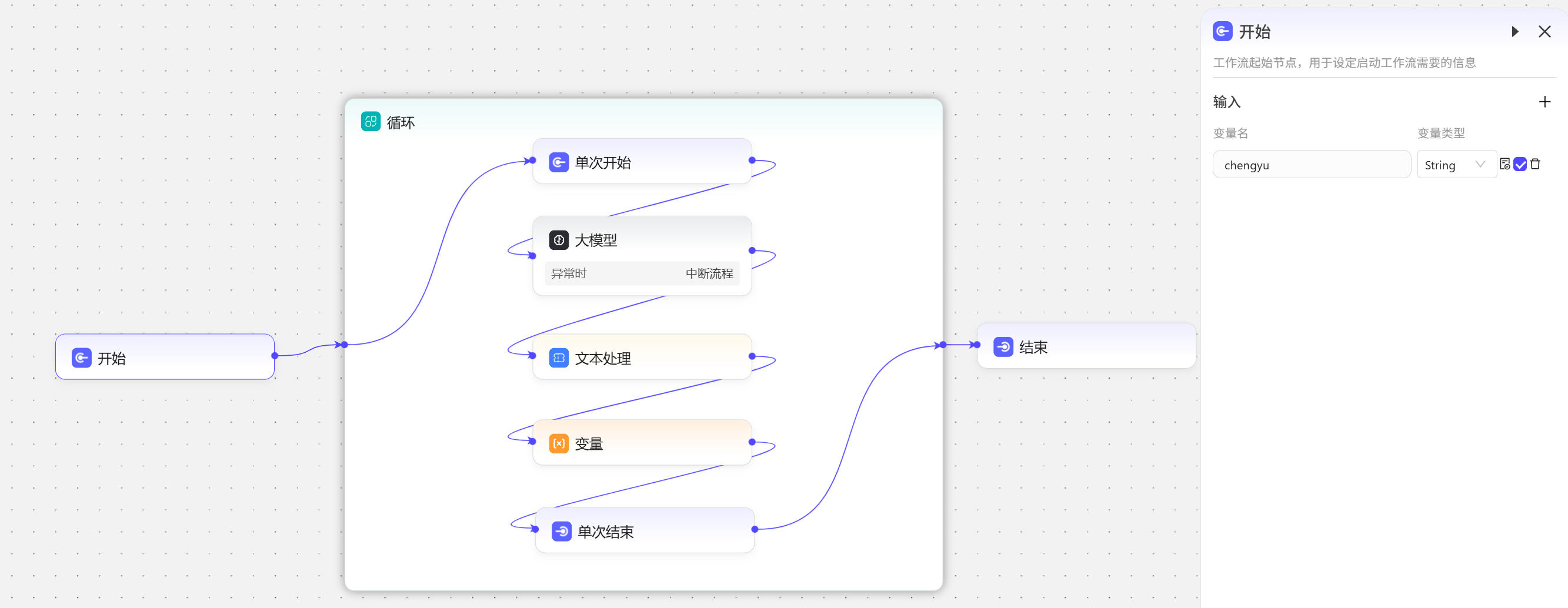
- 开始节点 创建变量
chengyu; - 循环节点
- 循环设置选择指定次数循环;
- 循环次数设置为5;
- 中间变量添加
word和sentence两个变量,word变量值引用自开始节点的chengyu变量;大模型每次接龙的词语拼接到一起后就会存入到sentence变量中,sentence最初是没有值的,所以这里不需要填写内容; - 输出,当循环结束时,需要
sentence变量中存储的成语句子输出,中间变量无法被后续节点引用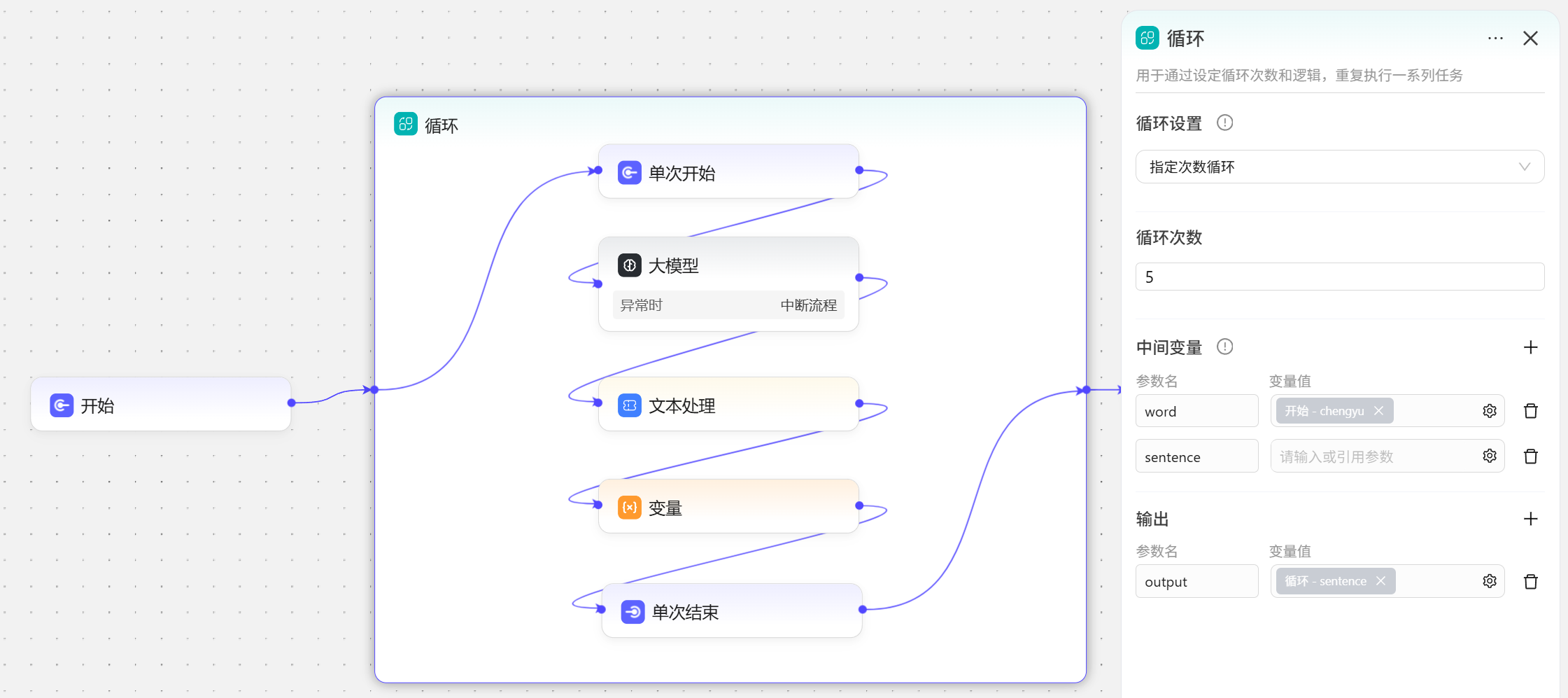
- 大模型节点
- 模型选择
DeepSeek-V3 - 输入引用循环中间变量
word - 系统提示词由AI自动生成成语接龙专家提示词
- 用户提示词引用输入变量
word - 输出采用文本格式,变量名保持默认使用
output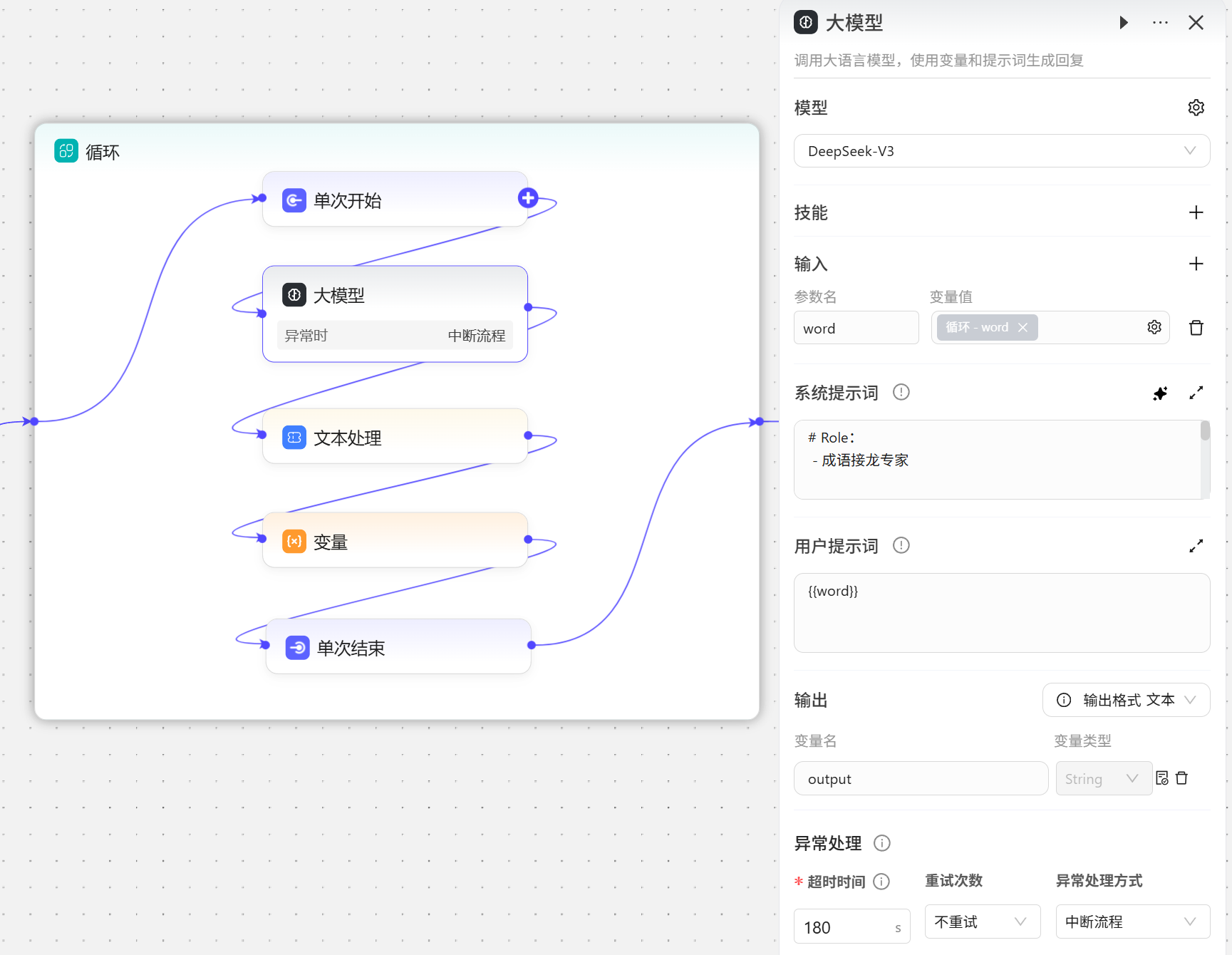
- 文本处理节点 此节点作用为将大模型每次输出的成语进行拼接
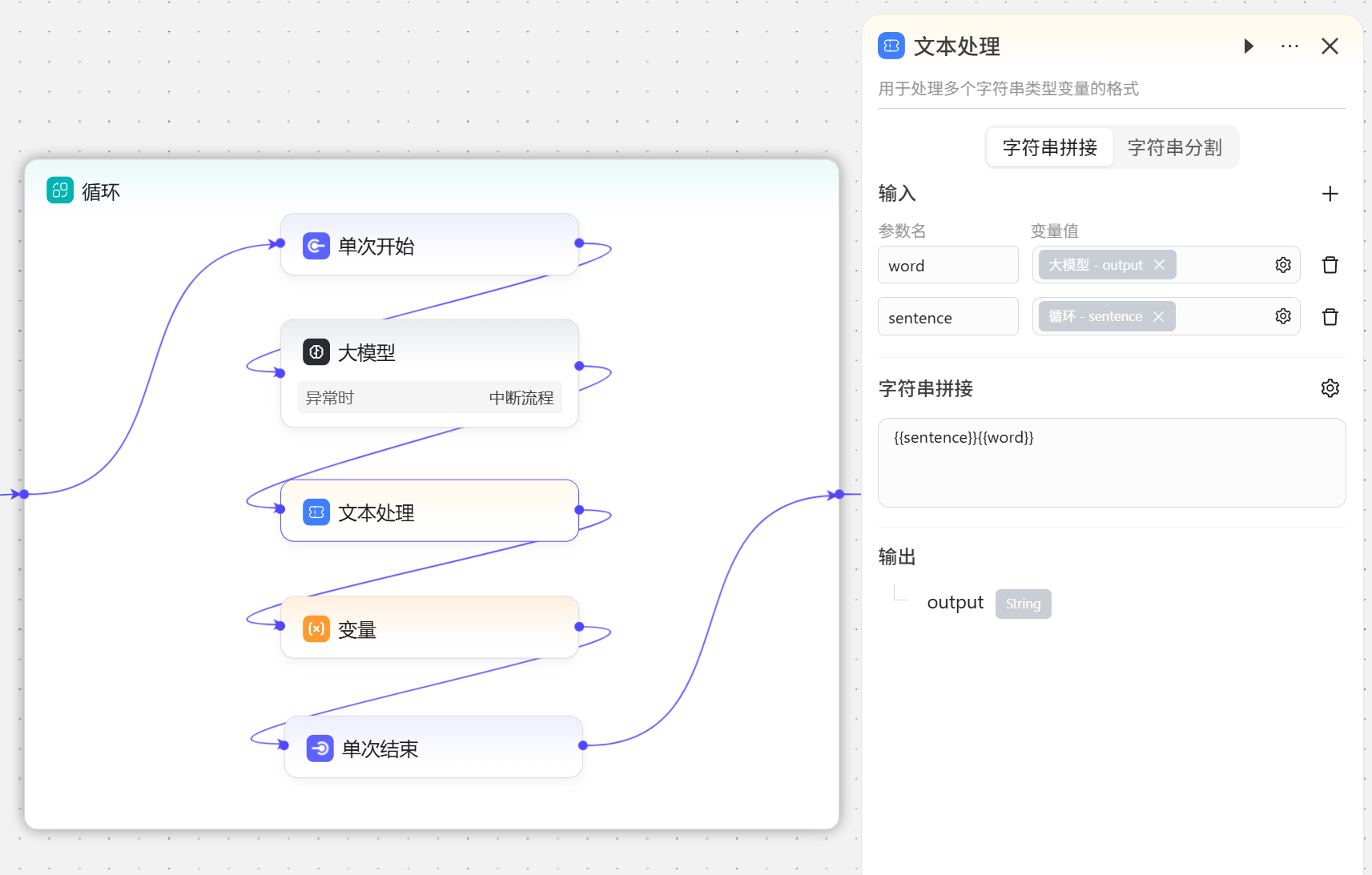
- 变量节点 此节点有两个作用,一是将文本处理拼接后的结果保存到
sentence变量中;二是将大模型接龙的成语保存到word变量中,下一次循环时大模型处理的成语才会变成另一个成语 - 结束节点 输出循环的最终结果
- 试运行来看看效果
长期记忆
用于调用长期记忆,获取用户的个性化信息,用户在使用某个智能体时,可能会产生大量的会话,这些会话数据在用户不主动删除的情况下会永久保存,在创建工作流时可以使用长期记忆节点查询用户跟此智能体以往的会话记录,根据用户对于此智能体的使用习惯来执行工作流的相关流程。
数据表
这里节点的作用主要是对数据表进行增删改查操作,如果想直接使用SQL语句来操作数据表,可以使用SQL自定义节点 这次我们以之前创建的销售信息数据表为例,表中有三个字段province、sales_rep_name、phone_number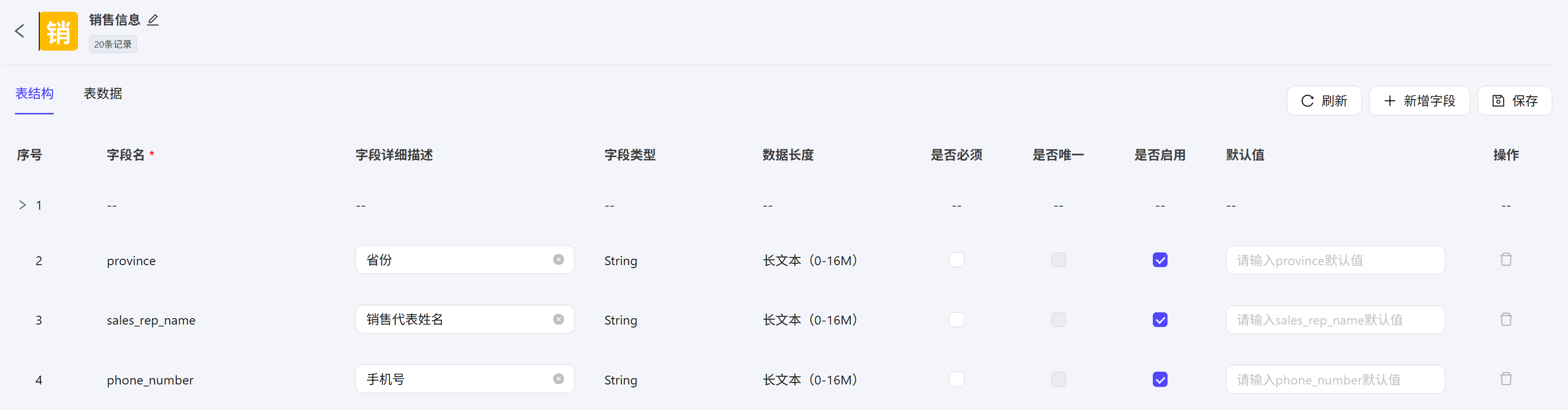 表中导入了20条模拟数据
表中导入了20条模拟数据 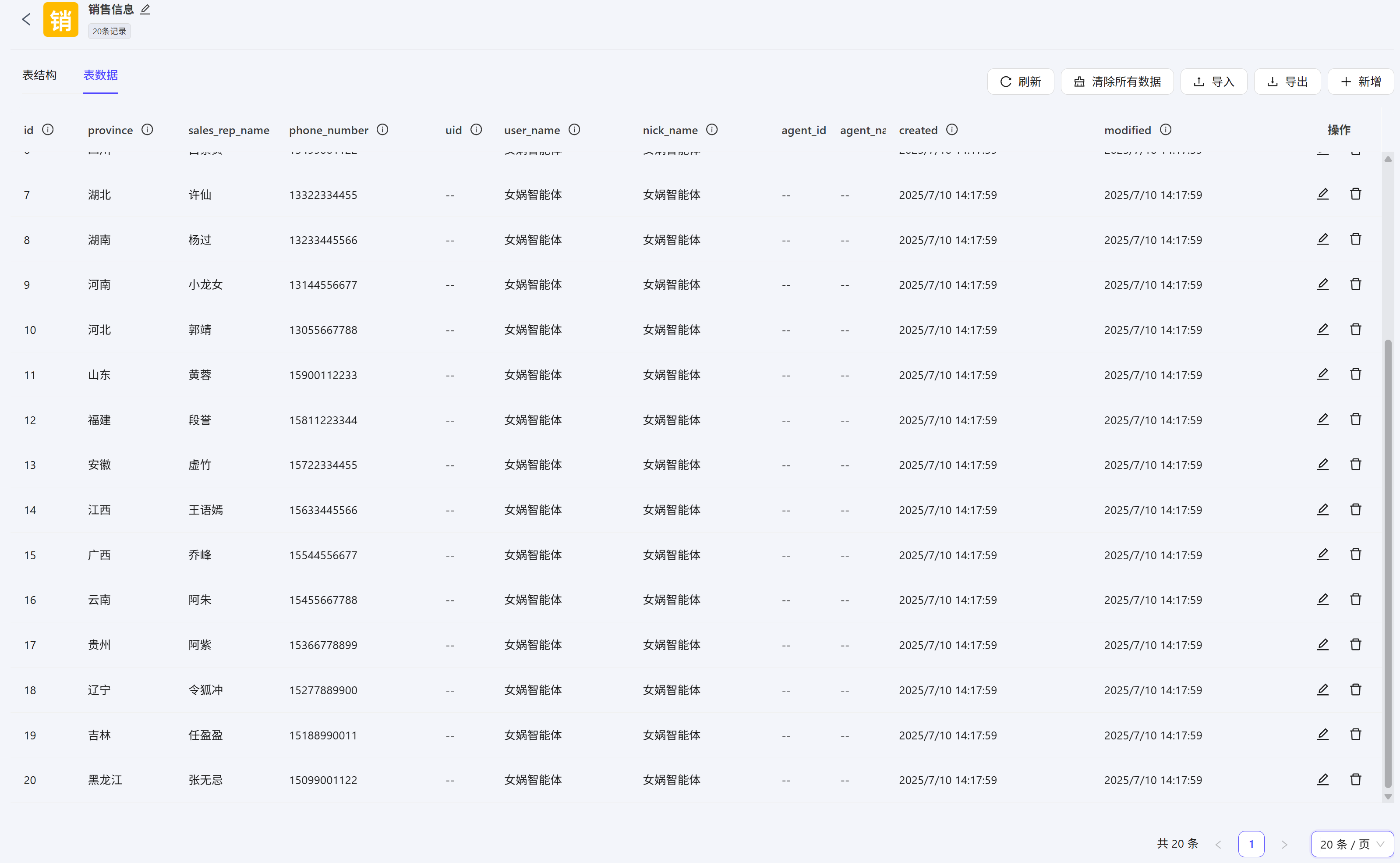 这里准备了一个工作流来演示数据表相关节点的所有功能,中间添加了一个条件分支用于判断输入指令,根据不同的输入指令就会执行不同的数据表节点
这里准备了一个工作流来演示数据表相关节点的所有功能,中间添加了一个条件分支用于判断输入指令,根据不同的输入指令就会执行不同的数据表节点 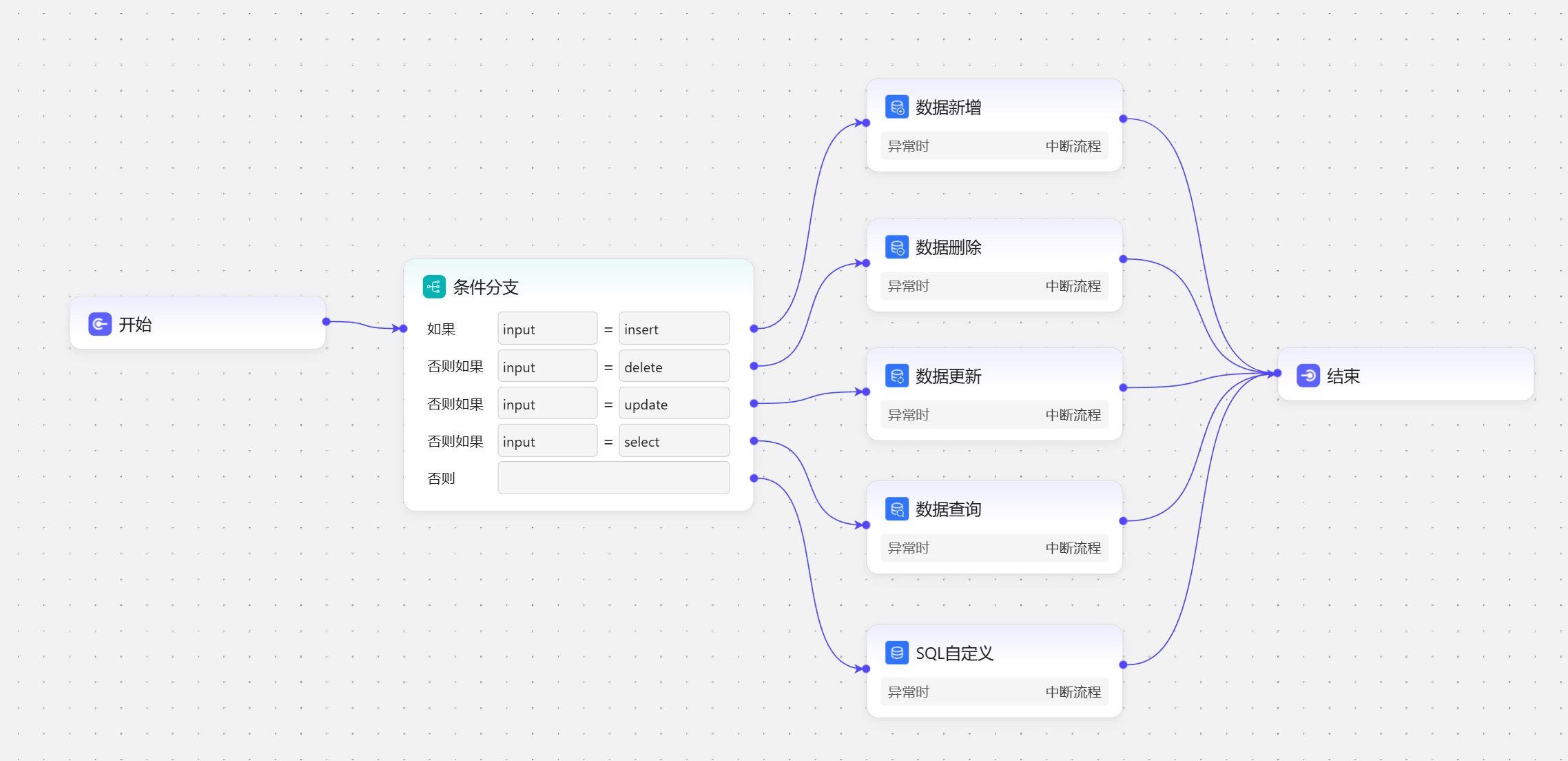
数据新增
在开始节点输入insert,条件分支走第一条分支,执行数据表新增操作 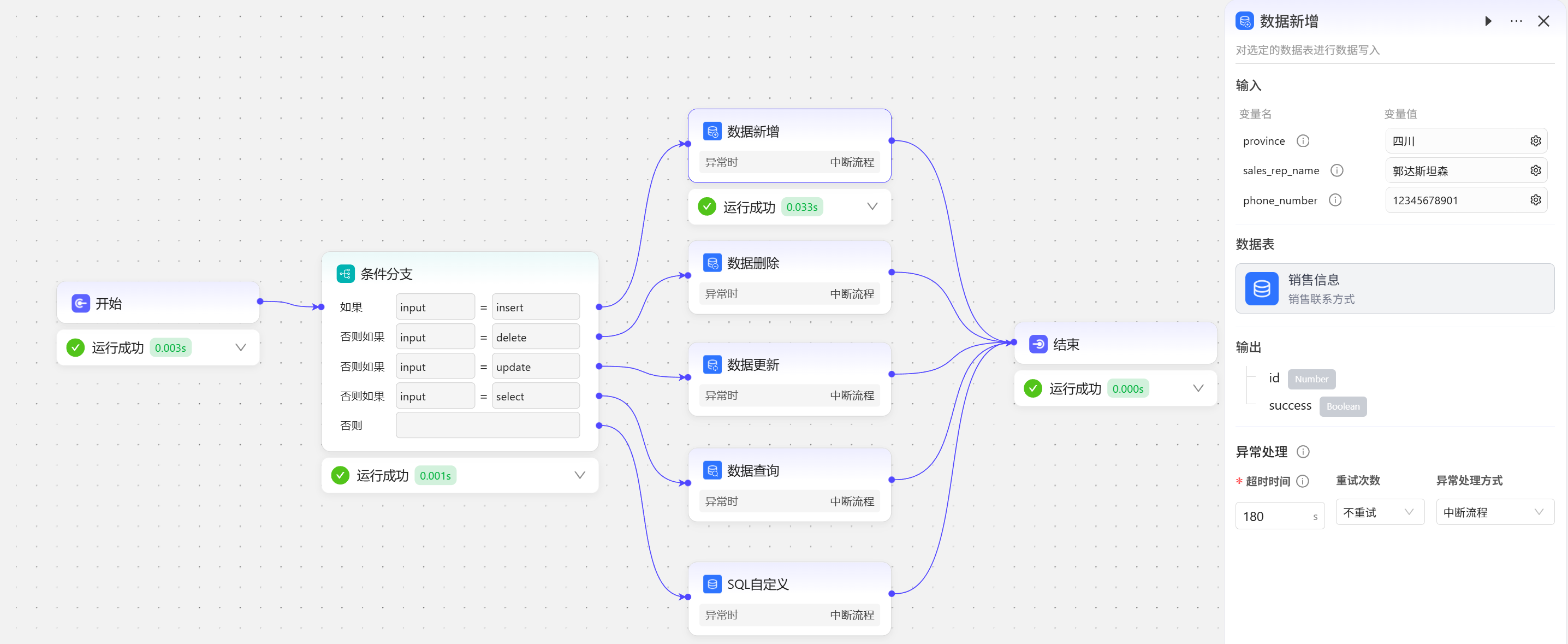 在数据表中刷新数据,可以看到数据已经新增成功
在数据表中刷新数据,可以看到数据已经新增成功 
数据删除
在开始节点输入delete,条件分支走第二条分支,执行数据表删除操作,删除销售代表姓名为张无忌的这条数据 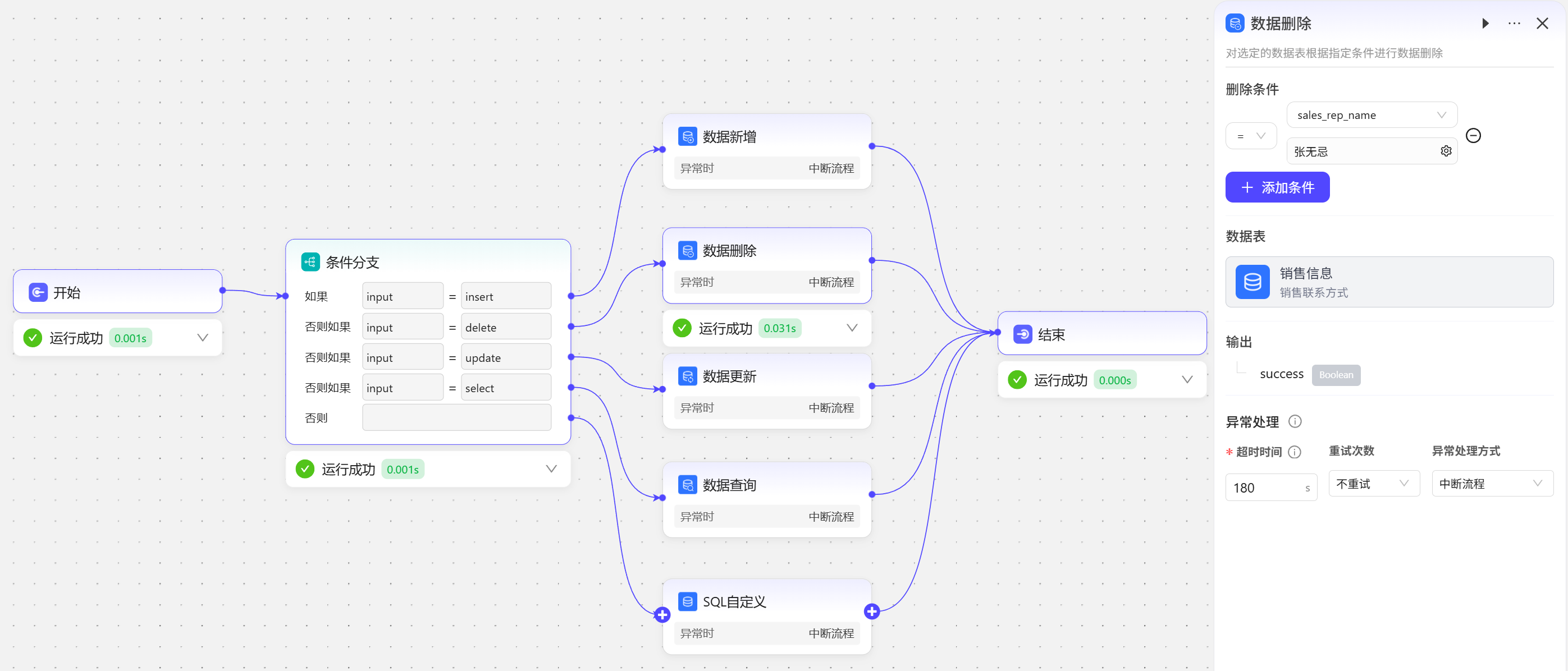 数据表中刷新数据发现第20条数据已经删除成功
数据表中刷新数据发现第20条数据已经删除成功 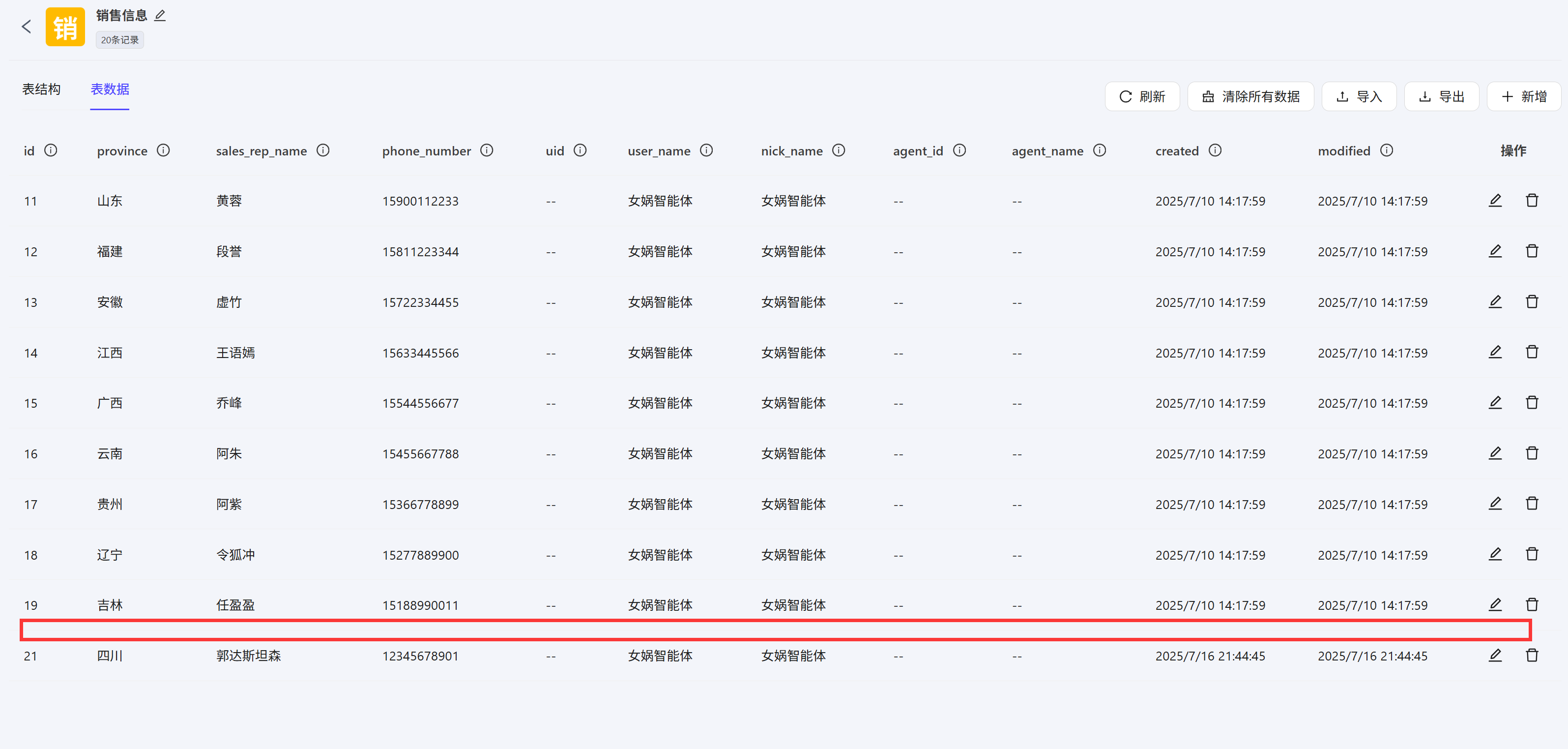
数据更新
更新其实就是修改这条数据中某些字段的值,在开始节点输入update,条件分支走第三条分支,执行数据表更新操作,将销售代表姓名为郭达斯坦森的这条数据的电话修改为10987654321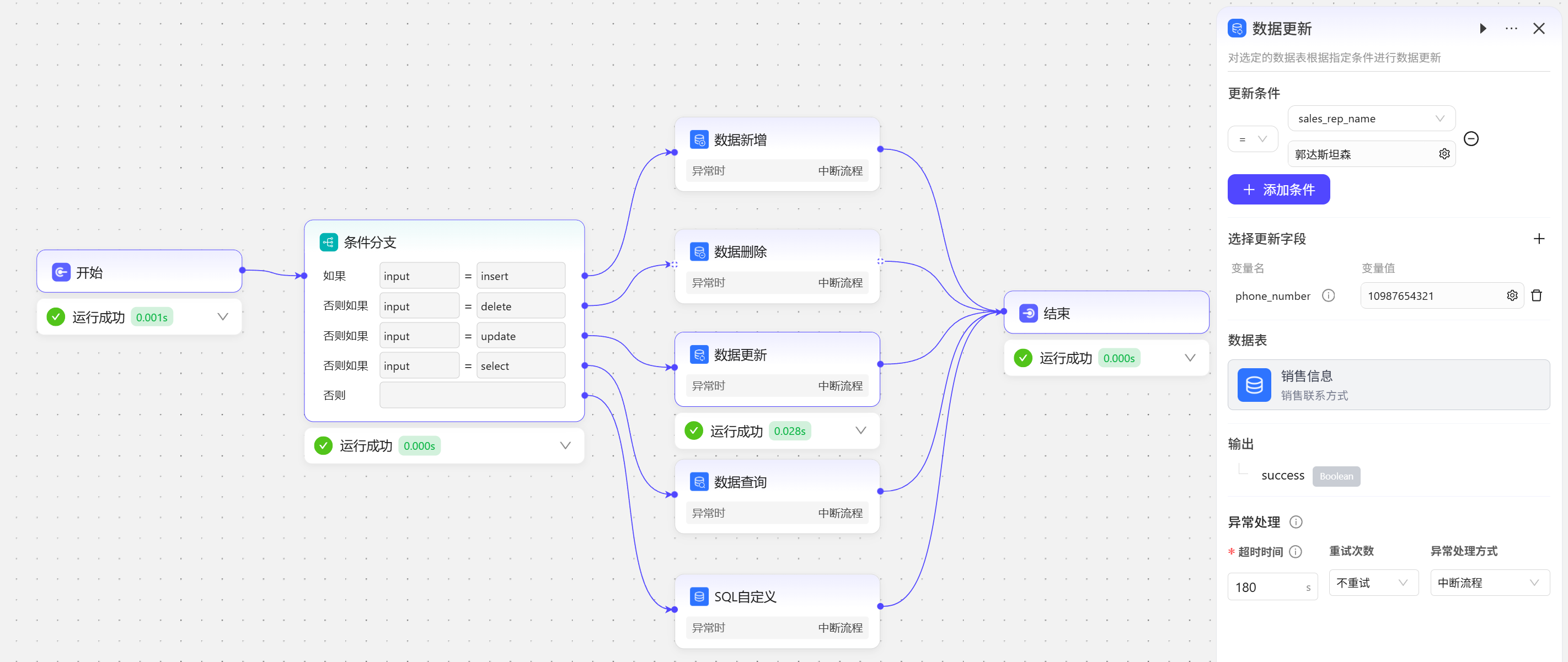 数据表中刷新数据发现郭达斯坦森的电话数据已经修改成功
数据表中刷新数据发现郭达斯坦森的电话数据已经修改成功 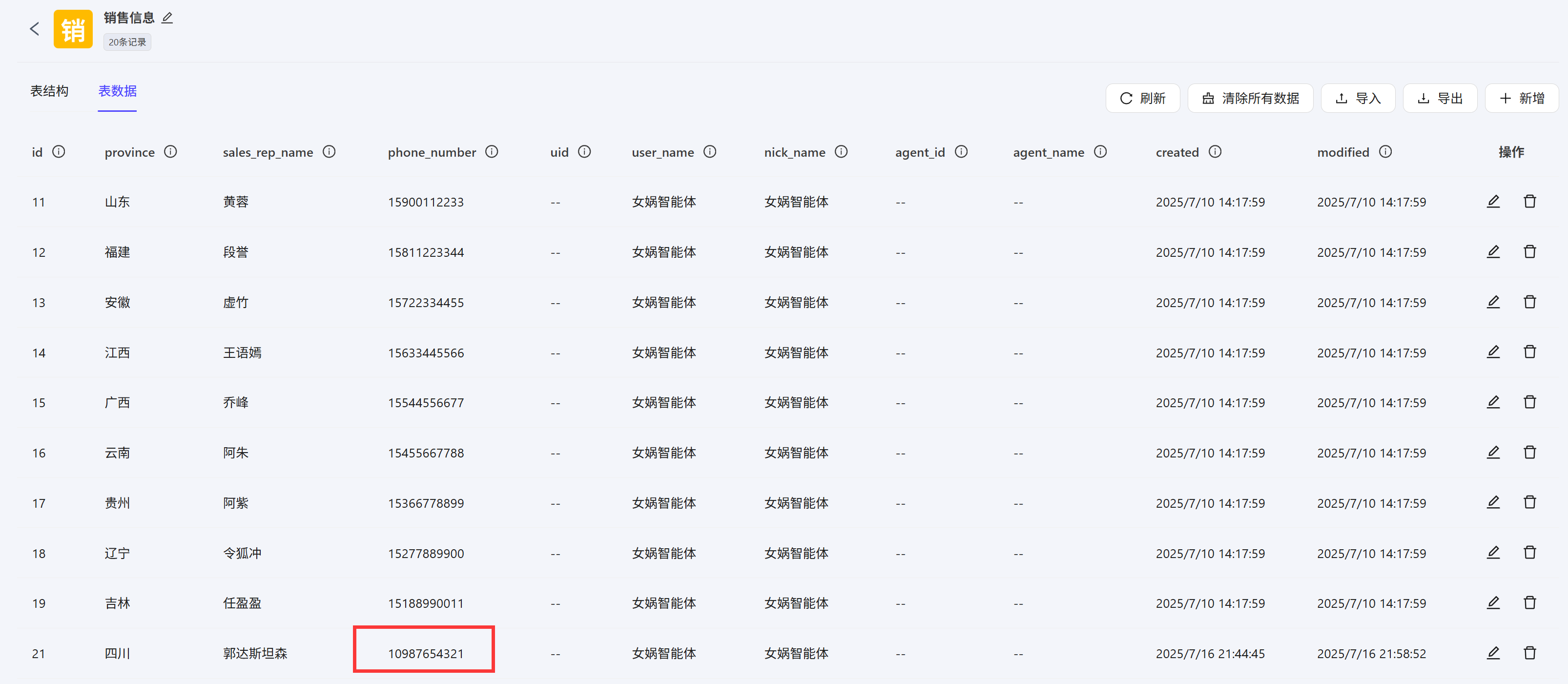
数据查询
在开始节点输入select,条件分支走第四条分支,执行数据表查询操作,查询省份为四川的所有数据 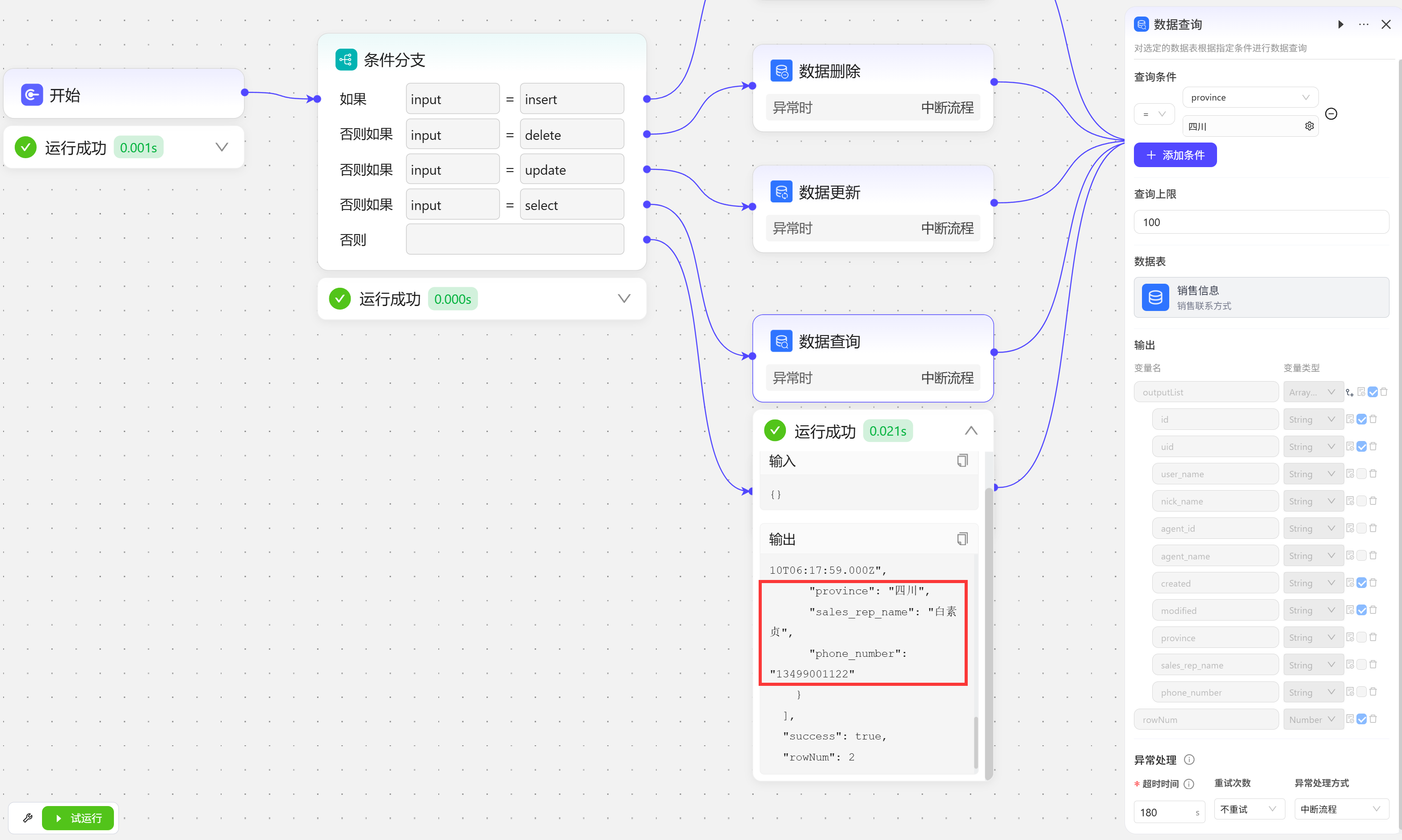
SQL自定义
SQL是最常用的数据库操作语言,对于熟悉SQL语言的用户,工作流中也提供了编写SQL语句的方式,这里编写了一条查询语句,查询表中省份为四川的所有数据 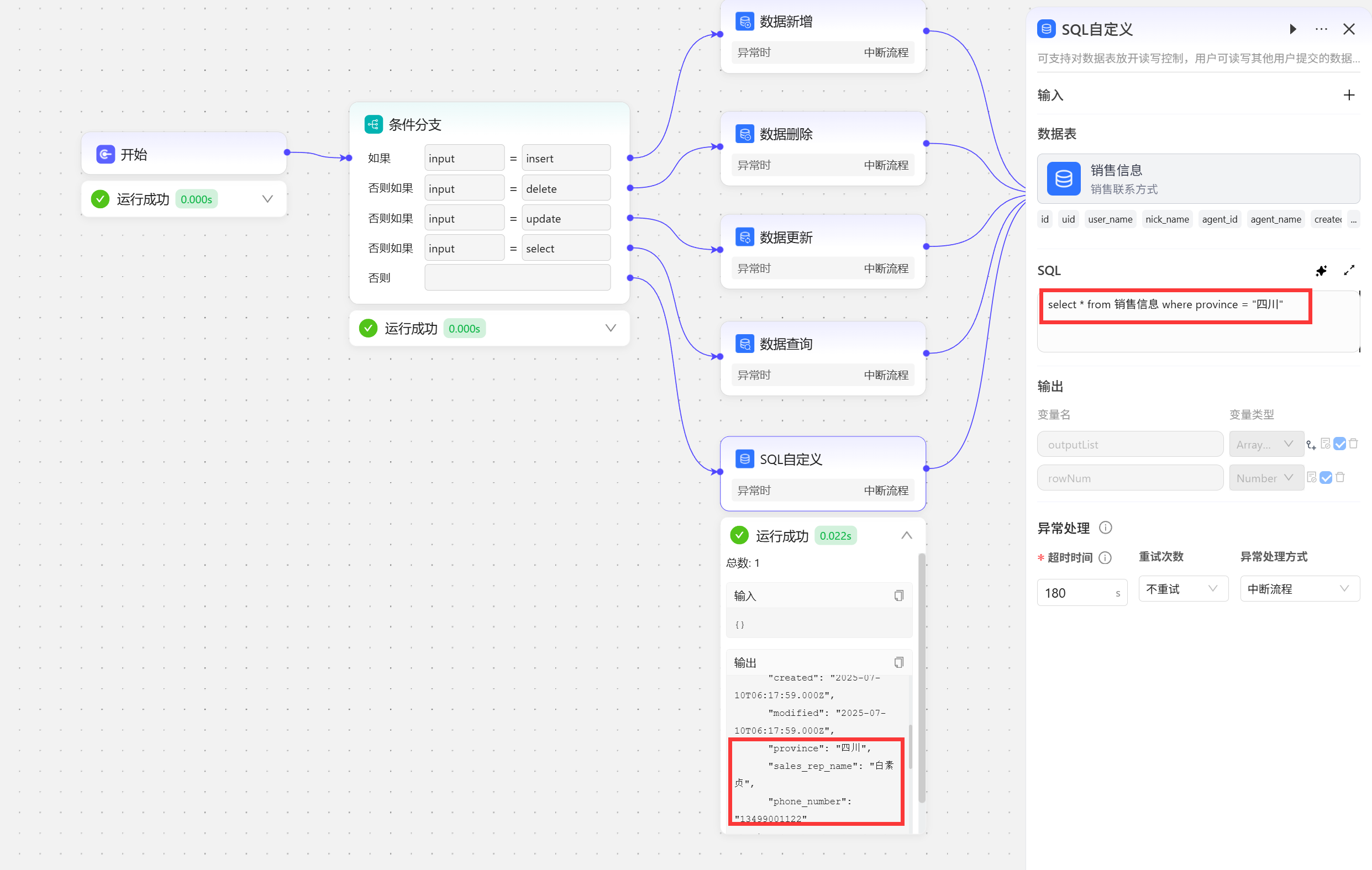 SQL语句的编写也可以使用自然语言来描述,AI会帮你写出SQL语句
SQL语句的编写也可以使用自然语言来描述,AI会帮你写出SQL语句 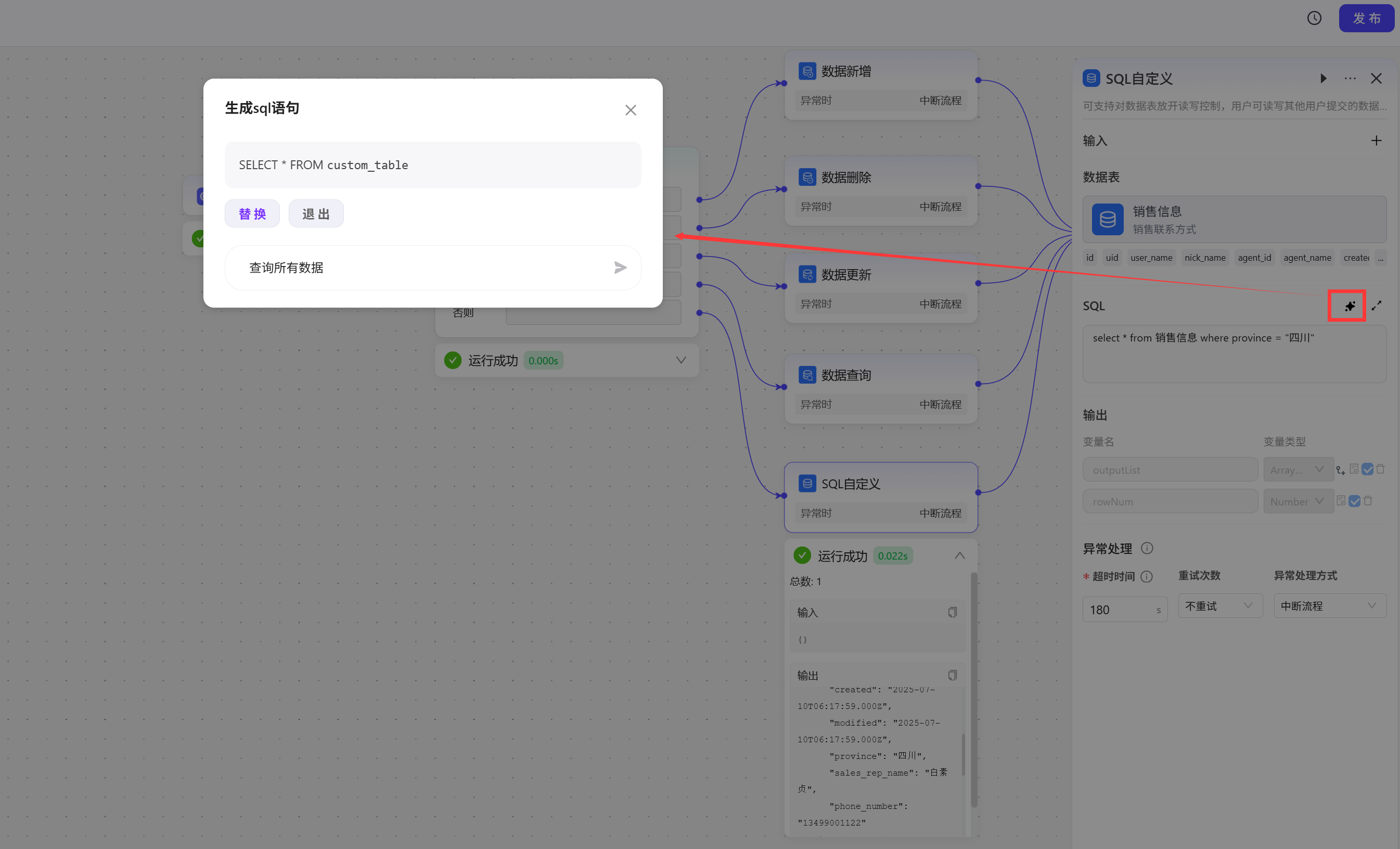
组件&工具
问答
问答节点可以用于制作问卷调查,或者在特定场景下向用户询问信息,如购物下单后,需用户提供送货地址和联系方式,如果用户提供的信息不完整,工作流会反复要求用户提供信息 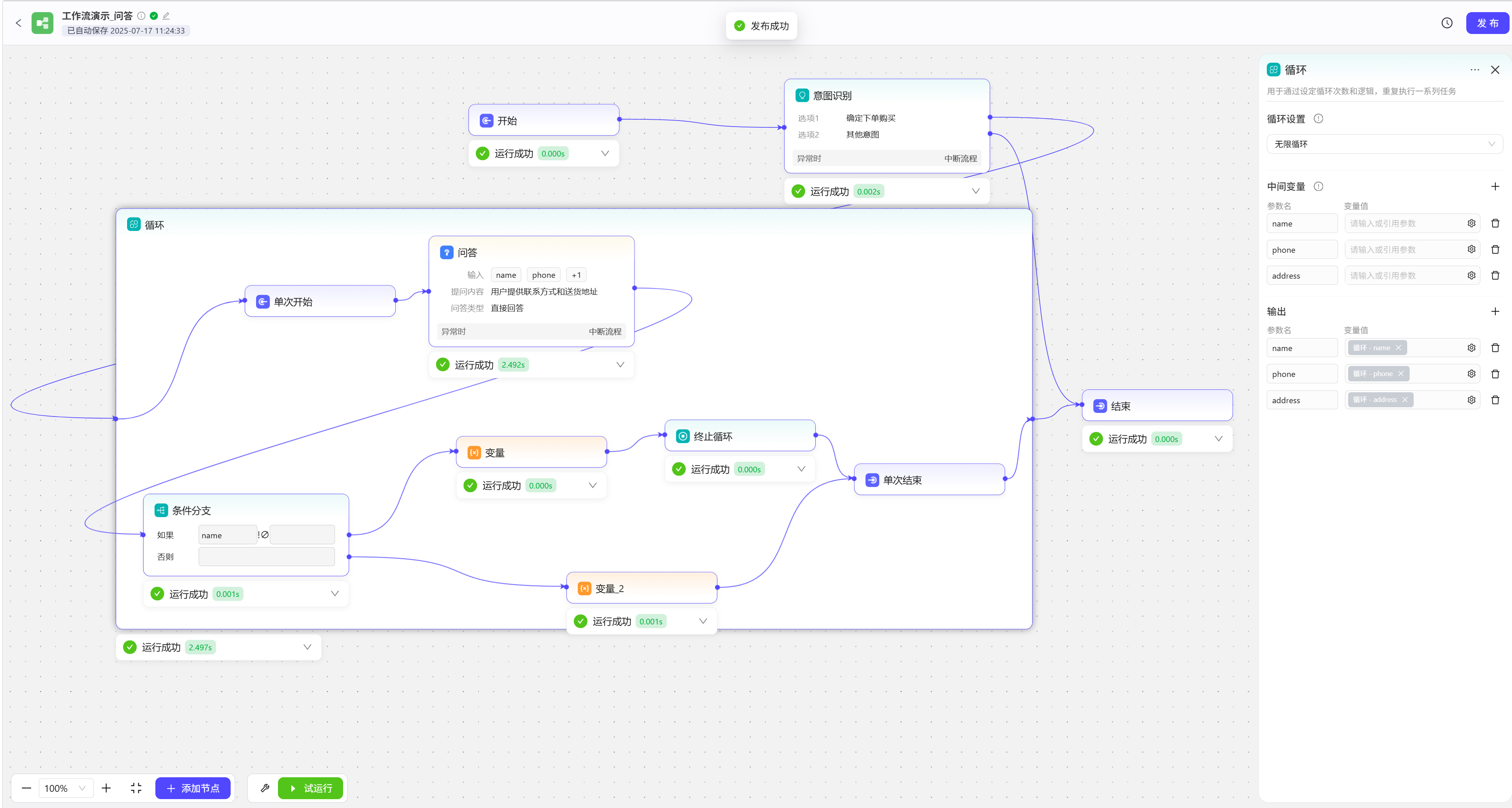 试运行效果展示
试运行效果展示 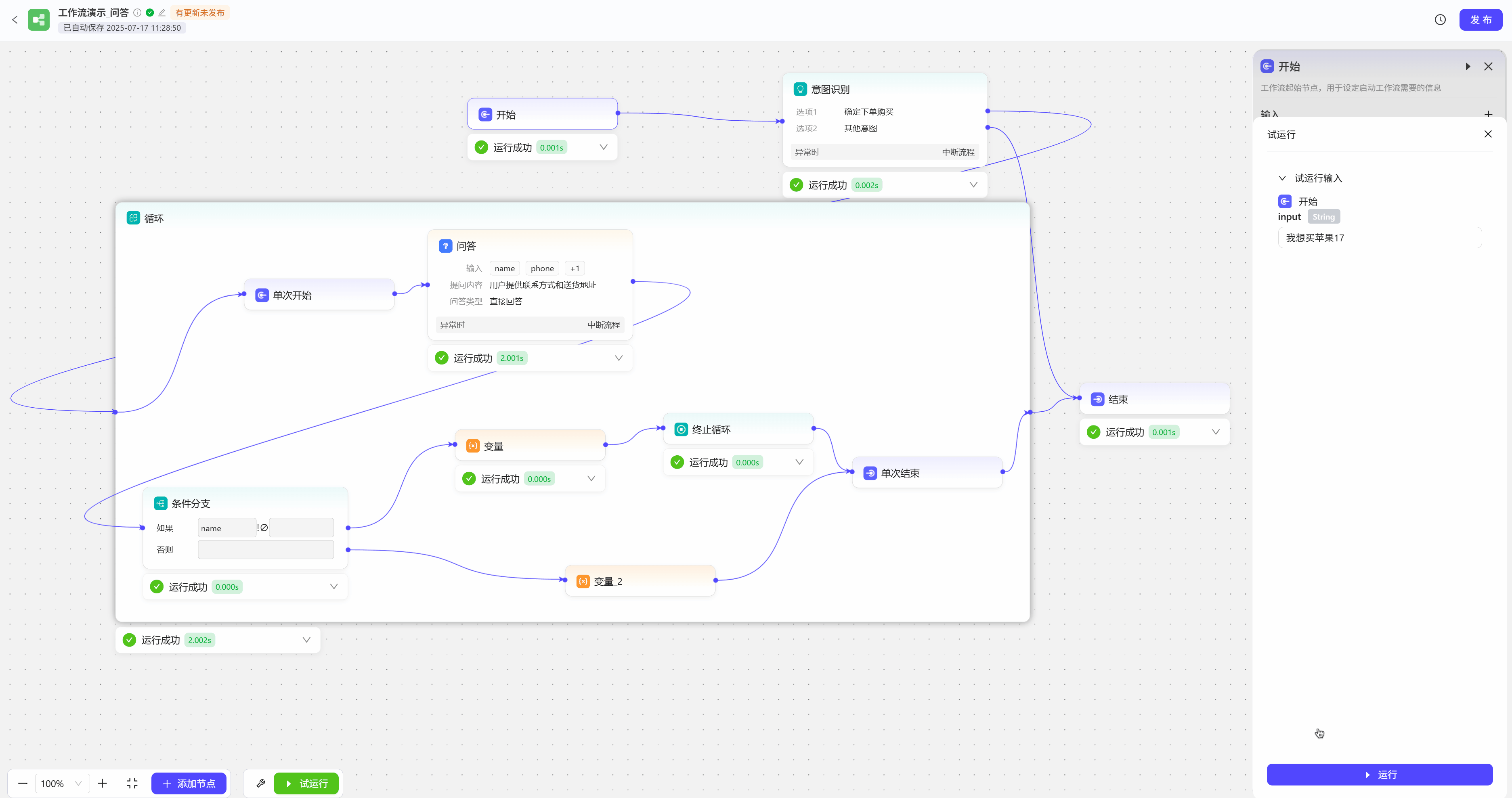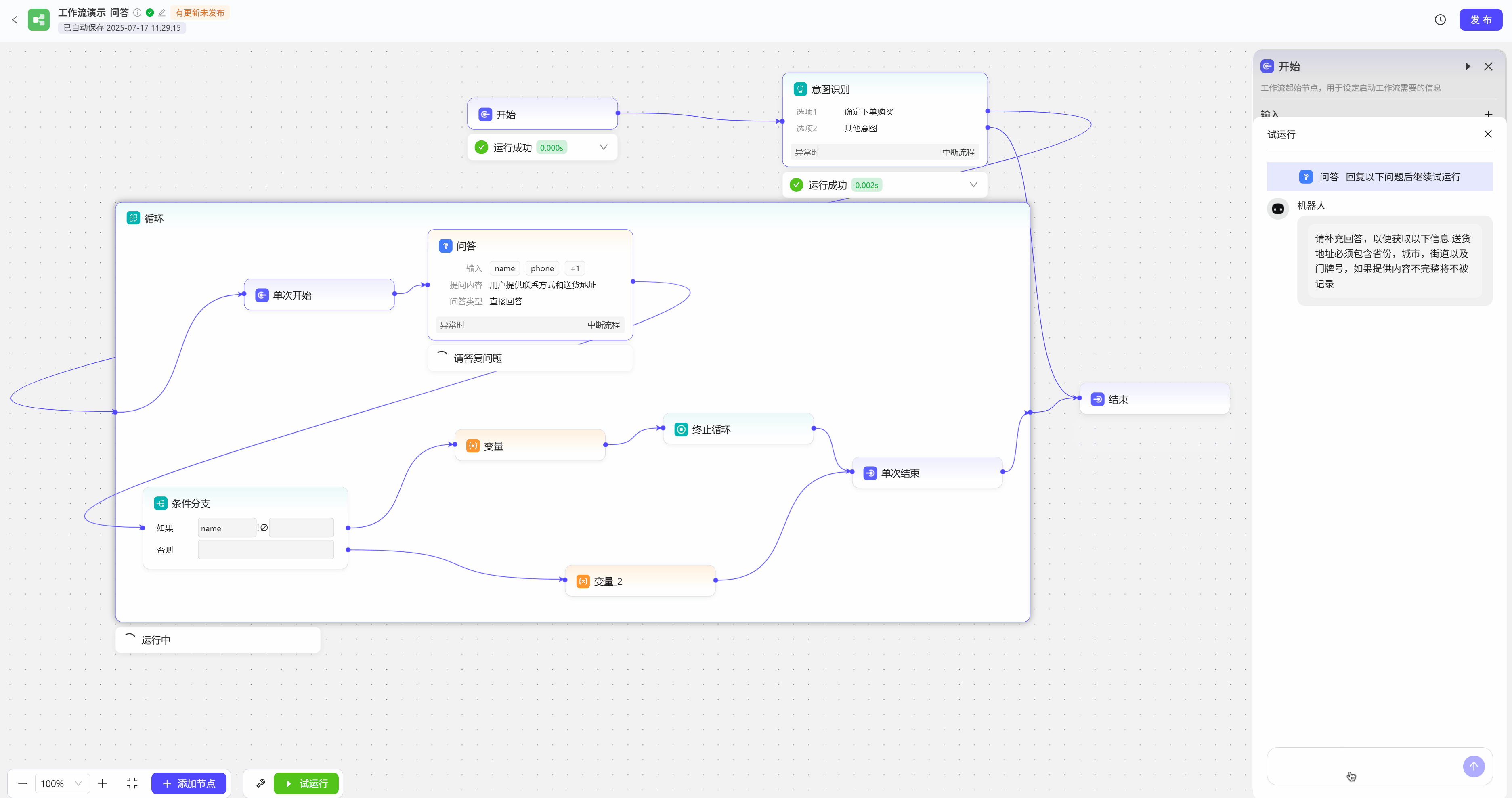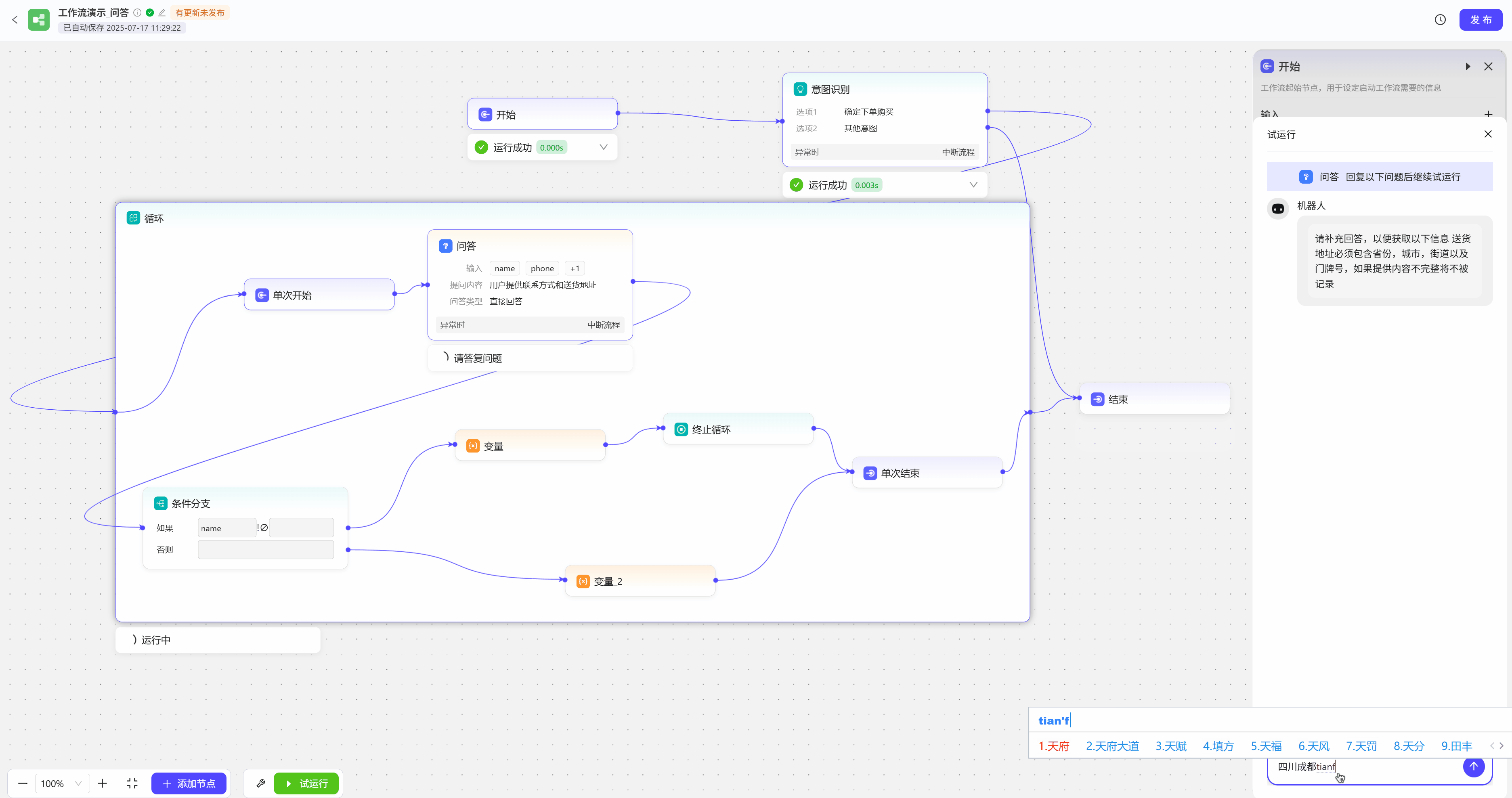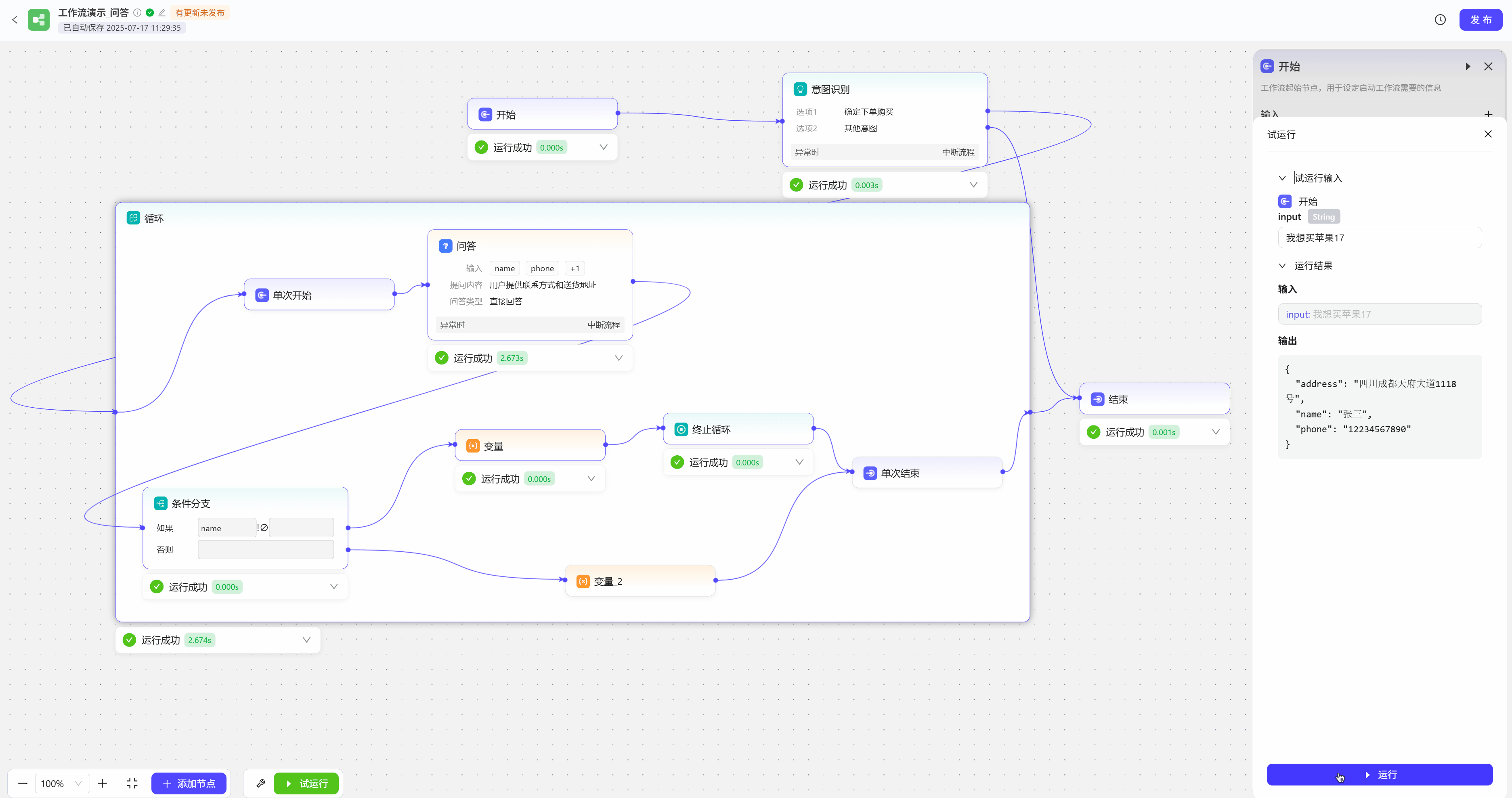
文本处理
文本处理有两种用法,字符串拼接和字符串分割
- 字符串拼接 这里我们通过一个拼句游戏来展示这个功能 我们让大模型来生成三个词语,地方、生态和动作
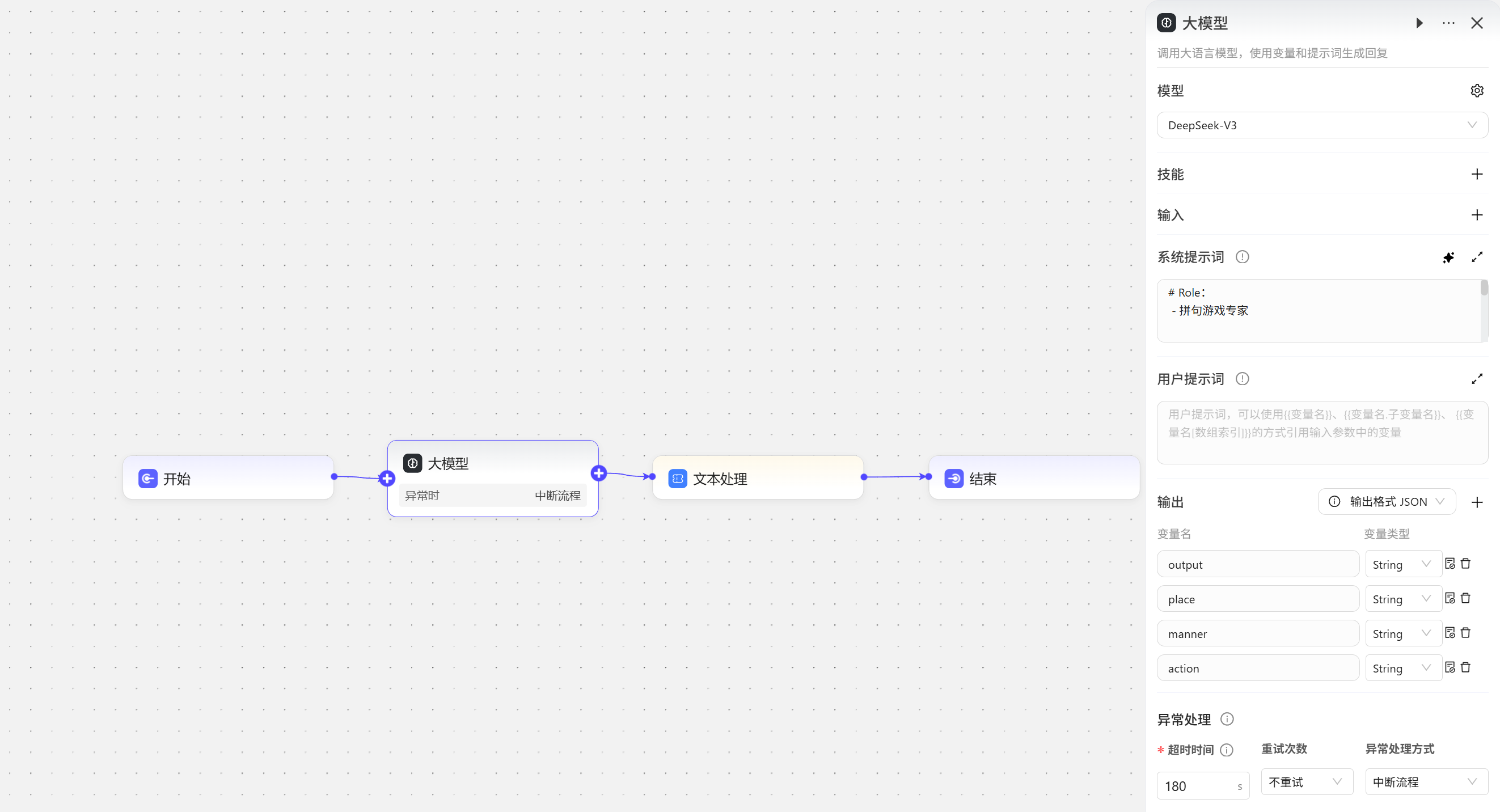 在文本处理节点我们将三个词语与
在文本处理节点我们将三个词语与input节点输入的人名拼接成一句话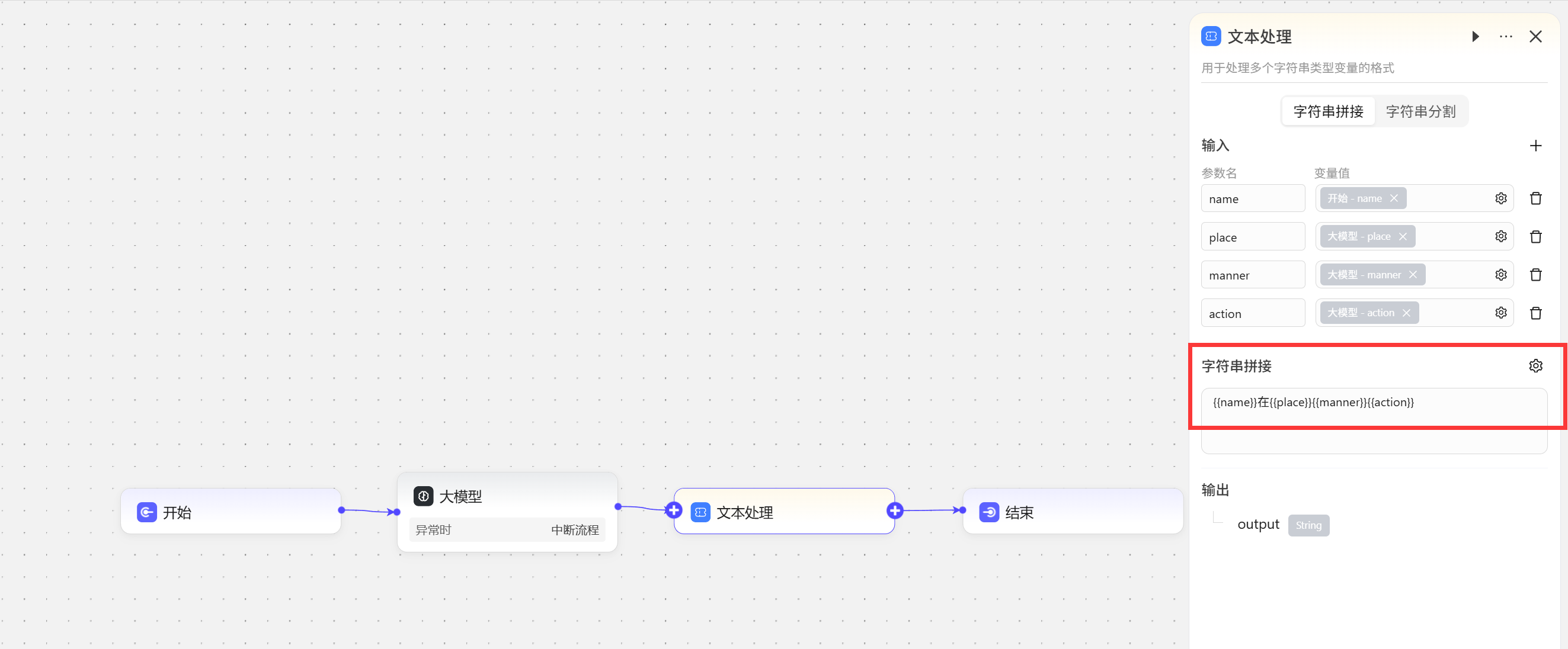 最后试运行展示效果
最后试运行展示效果 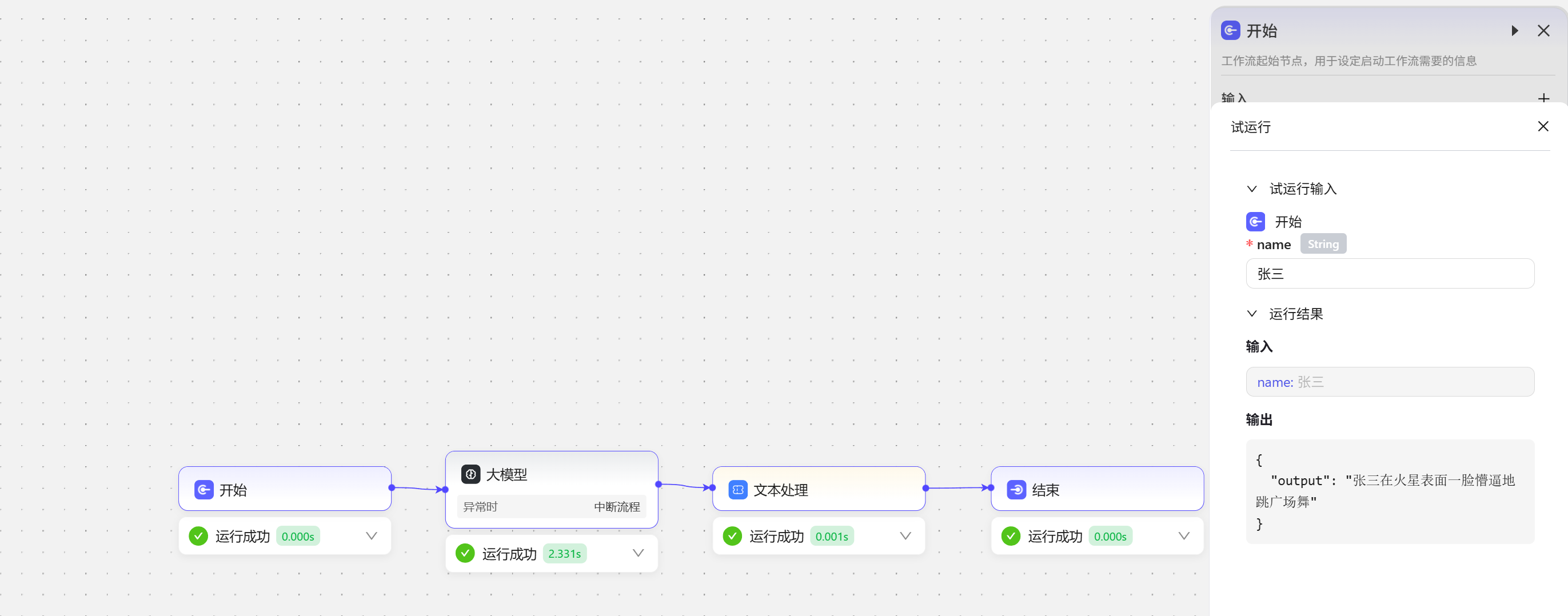
- 字符串分割 这里简单演示下分割句子的功能,下方有一个小故事,我想按照句号把每句话分开添加文本处理节点,选择字符串分割功能,输入为开始节点输入的故事,分隔符选择句号
陈砚秋第一次摸到老樟木时,指尖被树结硌出红痕。那年她七岁,蹲在祖父的木雕坊里,看老人用刻刀在木料上走笔,碎屑像金色的雨簌簌落下。 “木头会说话的。” 祖父总这么说。直到某个冬夜,她在作坊角落发现半块被虫蛀的梨木,裂纹像极了外婆眼角的皱纹。她偷偷拿起刻刀,竟雕出个捧着暖炉的老妇人,头巾褶皱里还藏着颗没雕完的福字。 十八岁那年外婆走了,陈砚秋把梨木雕像塞进棺木。此后她成了木雕坊的新主人,却总在深夜对着木料发呆。有天暴雨冲垮后院篱笆,她捡回段被雷劈过的枣木,焦黑的截面里渗出琥珀色的树脂。 三个月后,那段枣木雕成了株紫藤,虬结的枝干上盘着只雨燕,翅膀尖还沾着片没干透的叶子。来买木雕的老太太摸着燕子的尾羽红了眼:“这是我家屋檐下住了十年的那只。” 陈砚秋忽然懂了祖父的话。木头从不说谎,它记得春风穿过年轮的声响,记得匠人掌心的温度,那些藏在纹理里的秘密,总会在某个清晨,随着第一缕阳光爬出来。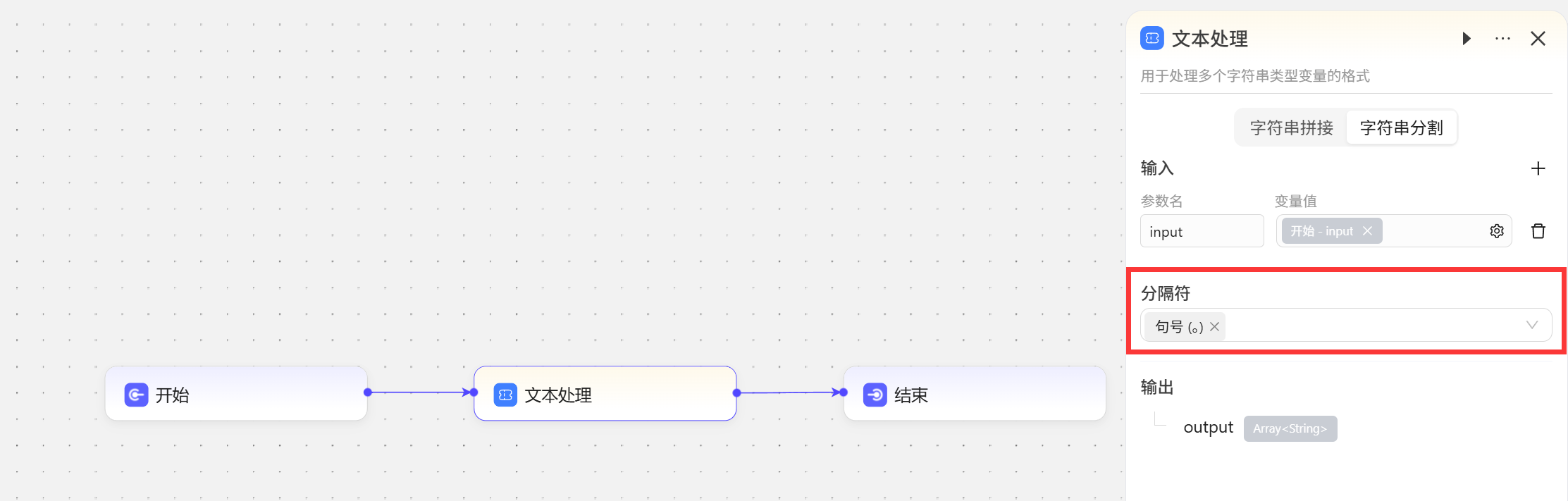 试运行效果展示
试运行效果展示 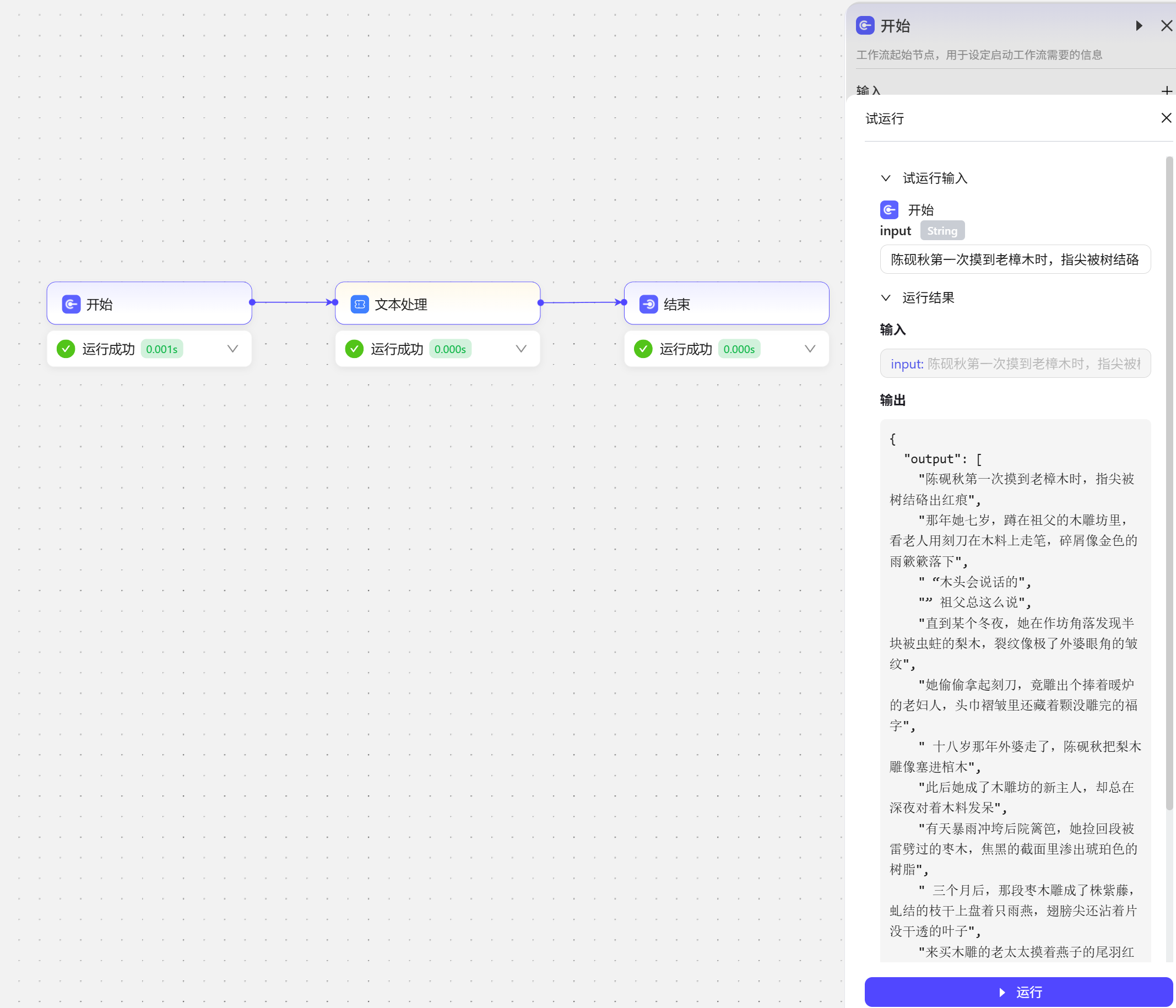 json
json{ "output": [ "陈砚秋第一次摸到老樟木时,指尖被树结硌出红痕", "那年她七岁,蹲在祖父的木雕坊里,看老人用刻刀在木料上走笔,碎屑像金色的雨簌簌落下", " “木头会说话的", "” 祖父总这么说", "直到某个冬夜,她在作坊角落发现半块被虫蛀的梨木,裂纹像极了外婆眼角的皱纹", "她偷偷拿起刻刀,竟雕出个捧着暖炉的老妇人,头巾褶皱里还藏着颗没雕完的福字", " 十八岁那年外婆走了,陈砚秋把梨木雕像塞进棺木", "此后她成了木雕坊的新主人,却总在深夜对着木料发呆", "有天暴雨冲垮后院篱笆,她捡回段被雷劈过的枣木,焦黑的截面里渗出琥珀色的树脂", " 三个月后,那段枣木雕成了株紫藤,虬结的枝干上盘着只雨燕,翅膀尖还沾着片没干透的叶子", "来买木雕的老太太摸着燕子的尾羽红了眼:“这是我家屋檐下住了十年的那只", "” 陈砚秋忽然懂了祖父的话", "木头从不说谎,它记得春风穿过年轮的声响,记得匠人掌心的温度,那些藏在纹理里的秘密,总会在某个清晨,随着第一缕阳光爬出来" ] }
文档提取
用于提取文档内容,支持的文件类型: txt、 markdown、pdf、 html、 xlsx、 xls、 docx、 csv、 md、 htm等 准备一个Word文档内容为一个笑话 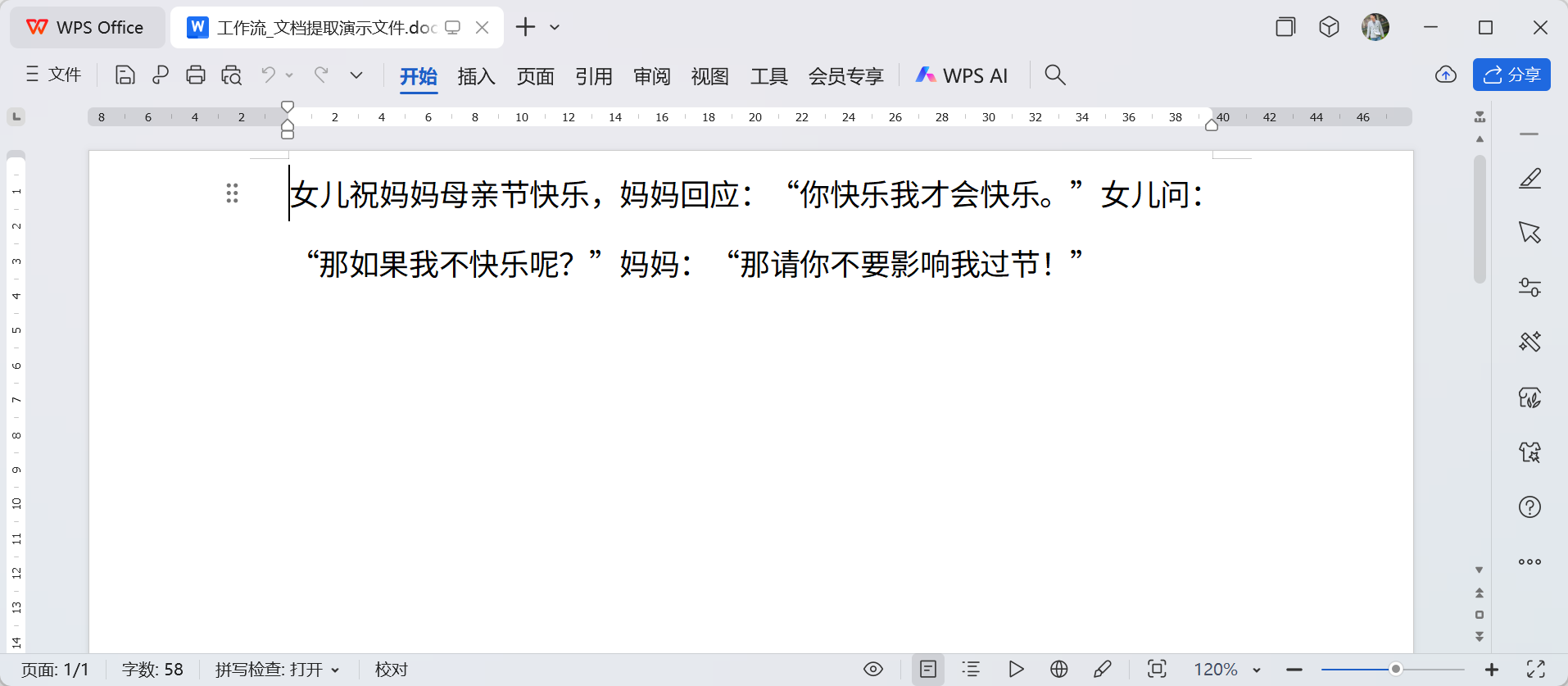 使用工作流来演示节点的功能,在开始节点将
使用工作流来演示节点的功能,在开始节点将input的变量类型设置为文件类型 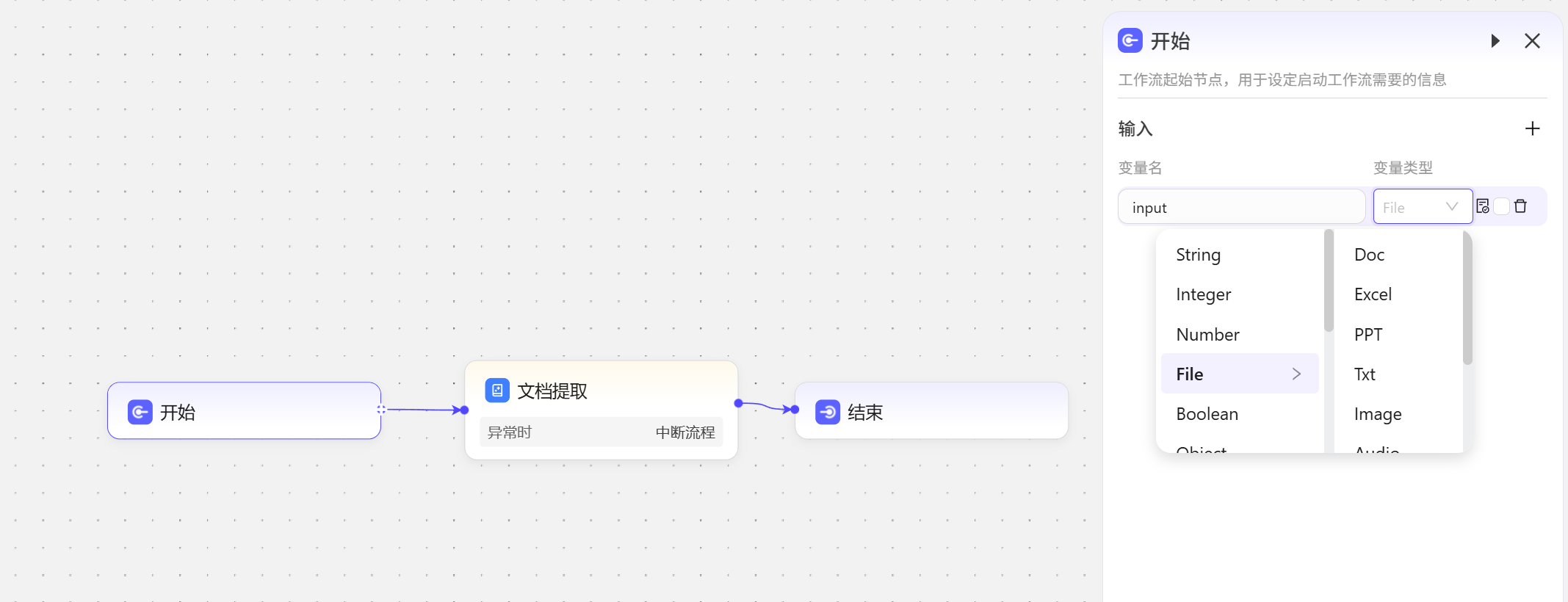 添加文档提取节点,输入设置为开始节点的
添加文档提取节点,输入设置为开始节点的input变量 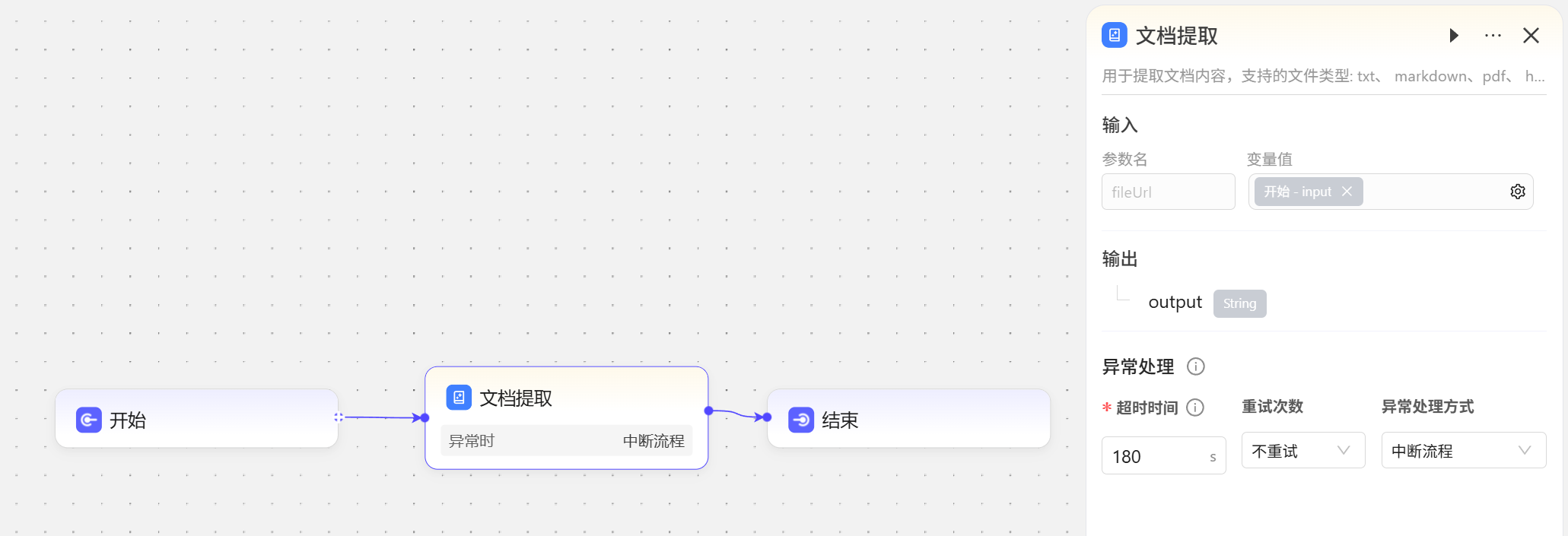 试运行看看效果
试运行看看效果 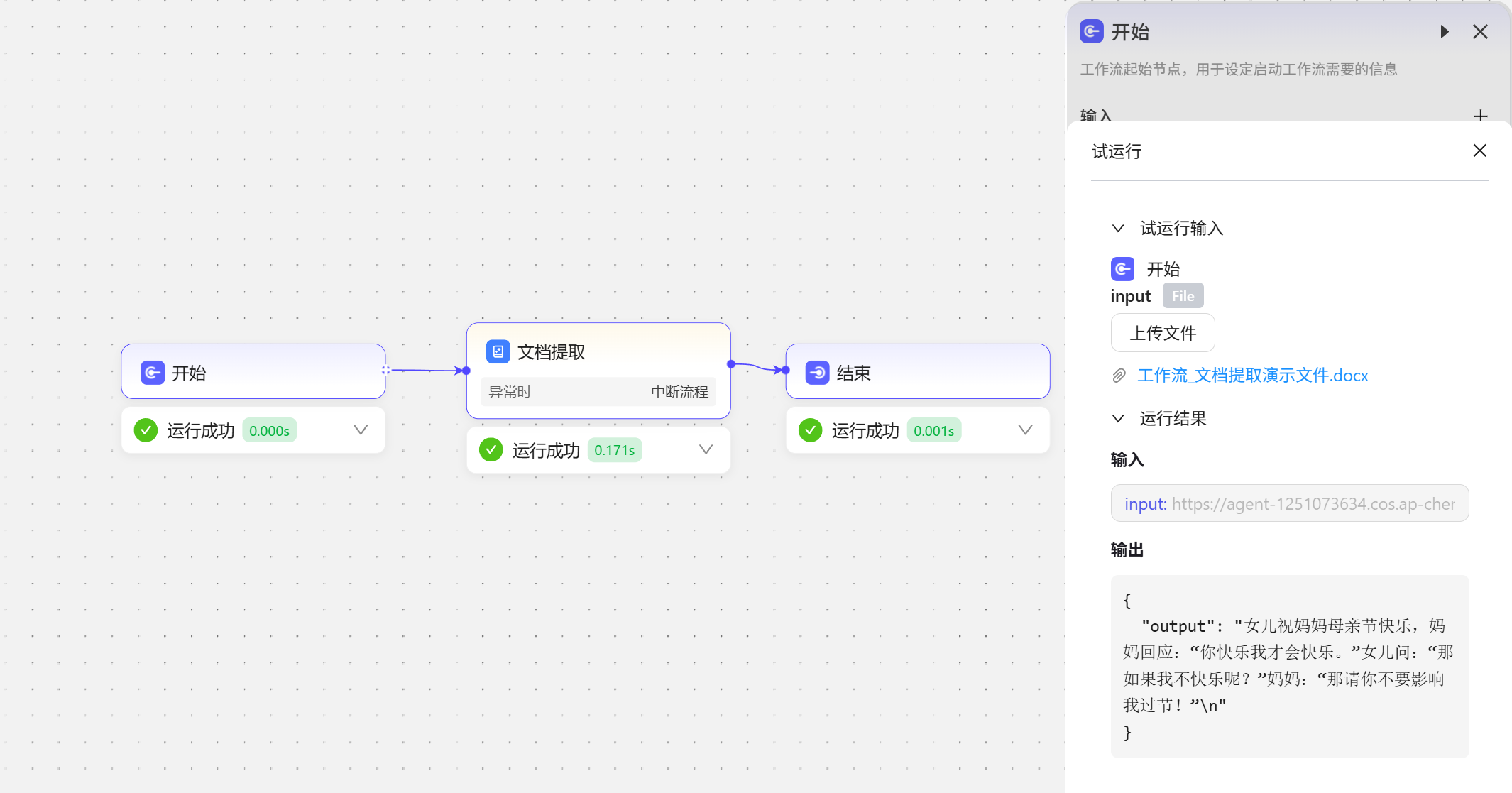
HTTP请求
作用是通过 HTTP 协议与外部系统、服务器或 API 接口进行数据交互。 我们试试请求女娲官网地址 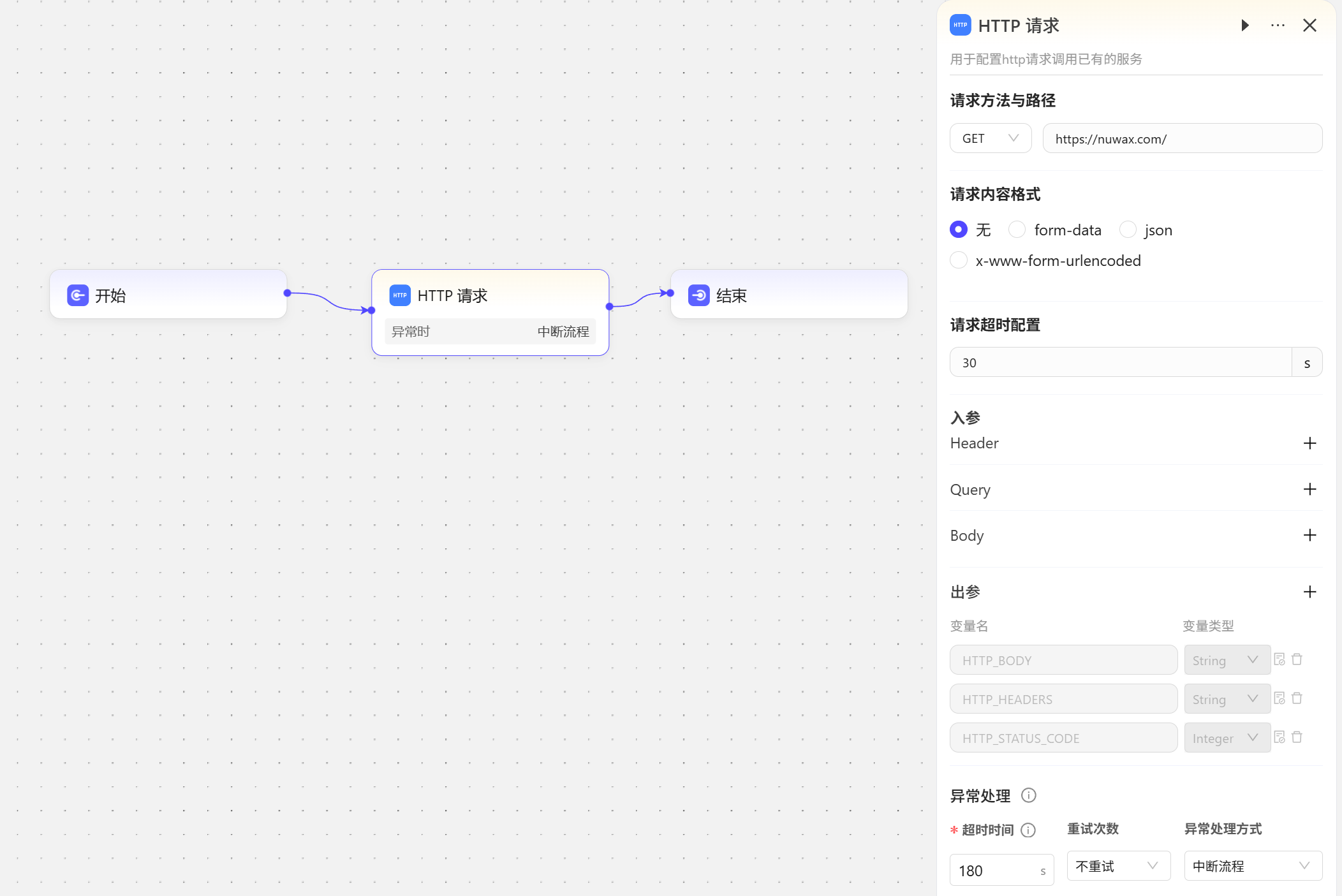 试运行结果展示,返回了官网的页面
试运行结果展示,返回了官网的页面 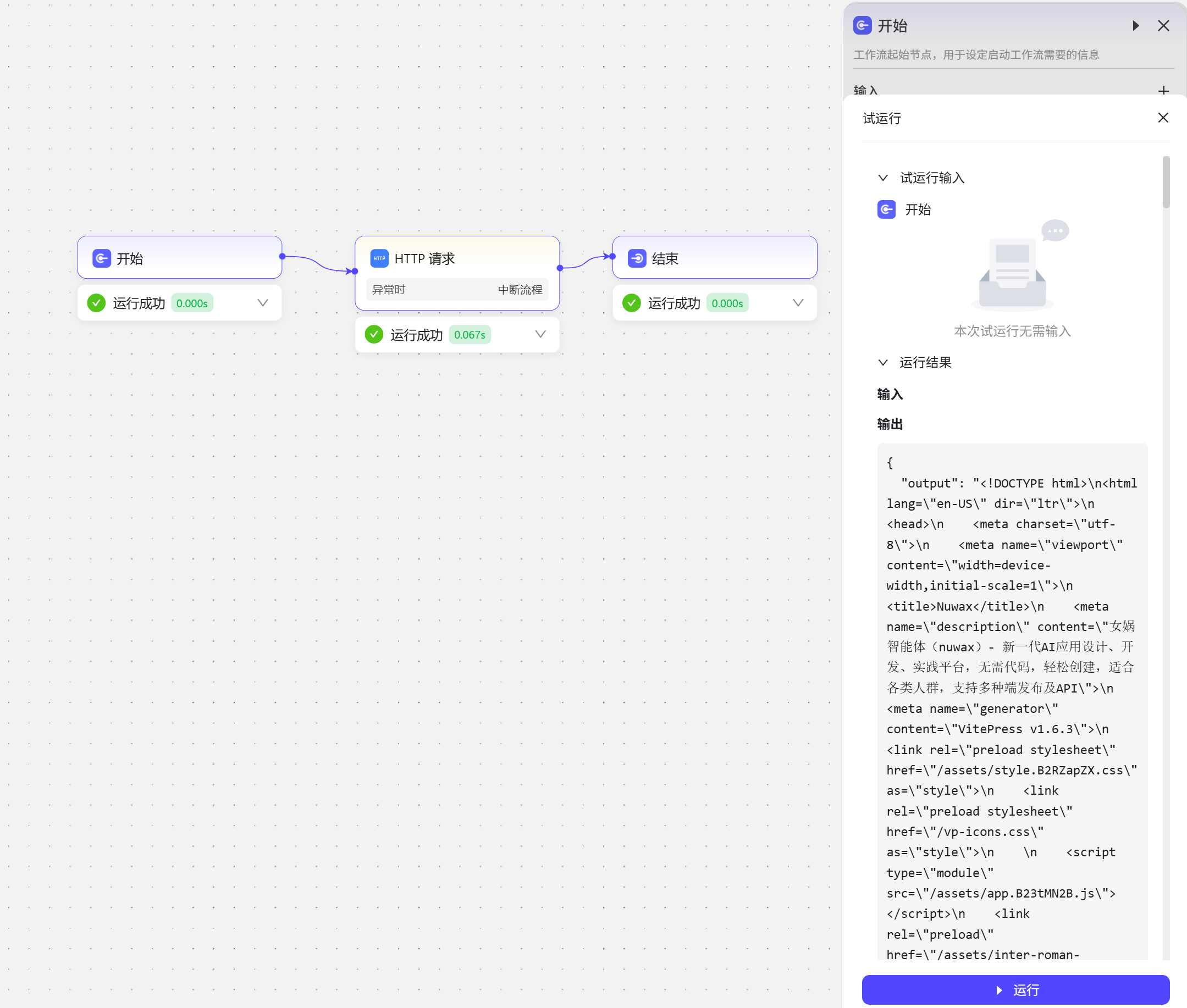
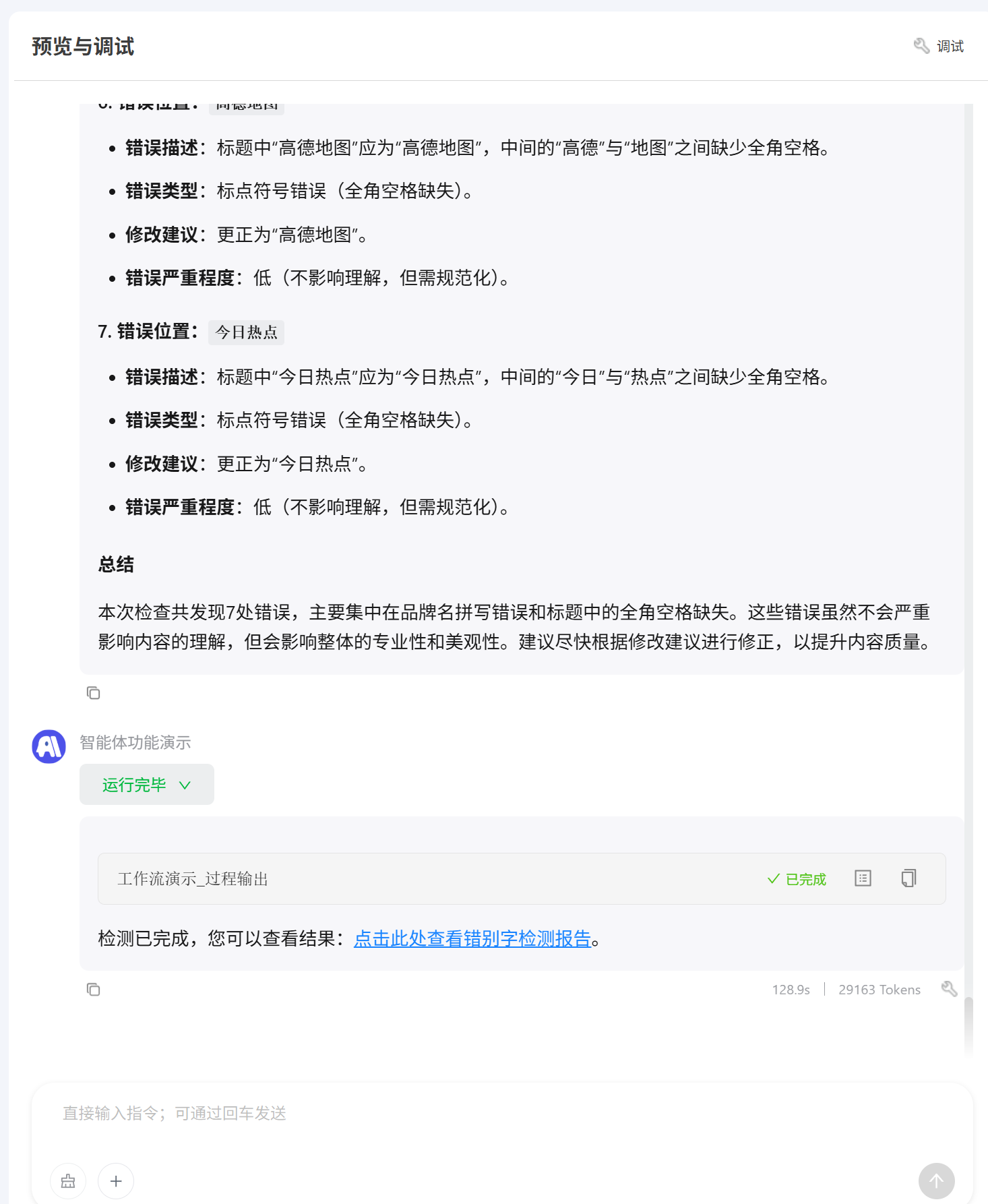
输出
过程输出
这里以制作的一个网页页面检查智能体为例,这里使用了两个过程输出节点 简单介绍下这个工作流的作用,在开始输入网页地址后,工作流会抓取网页上的相关链接,在所有链接都获取完成后第一个过程输出节点会在智能体的会话界面告诉用户“链接获取完成” 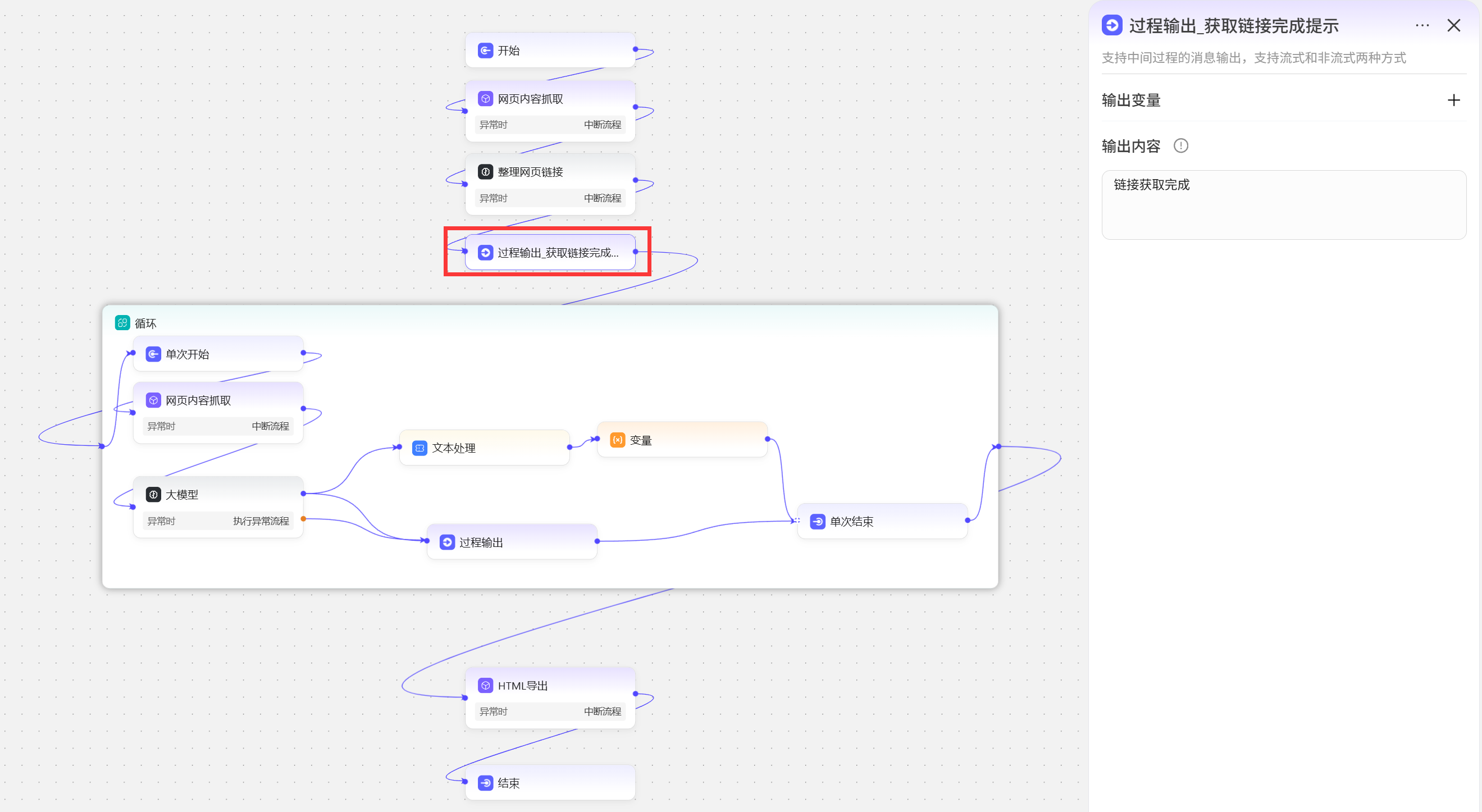 第二个过程输出节点的作用是大模型在循环中每次会分析一个页面,分析完成后直接将该页面分析结果反馈给用户
第二个过程输出节点的作用是大模型在循环中每次会分析一个页面,分析完成后直接将该页面分析结果反馈给用户 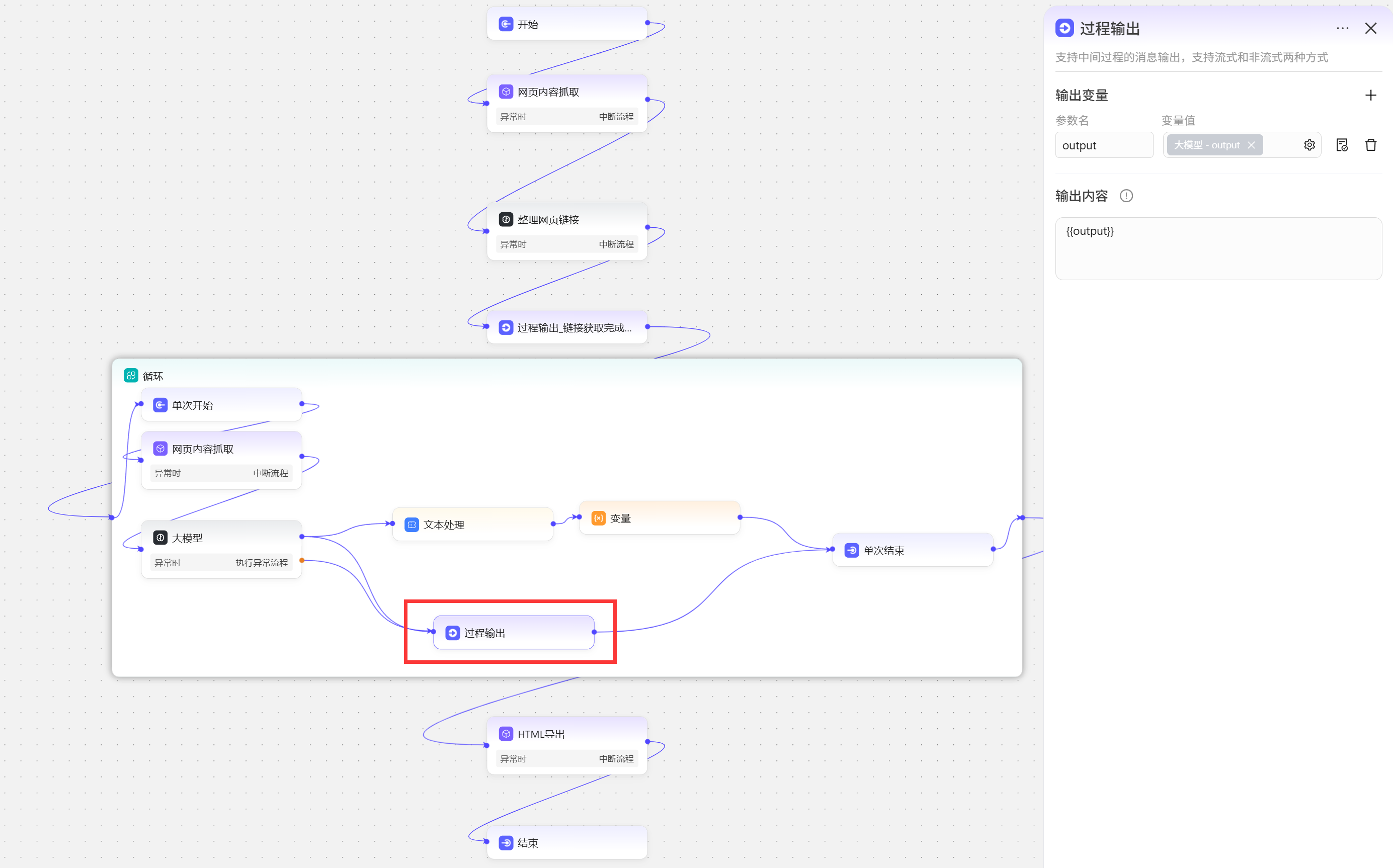 智能体添加工作流后使用效果展示: 第一次过程输出
智能体添加工作流后使用效果展示: 第一次过程输出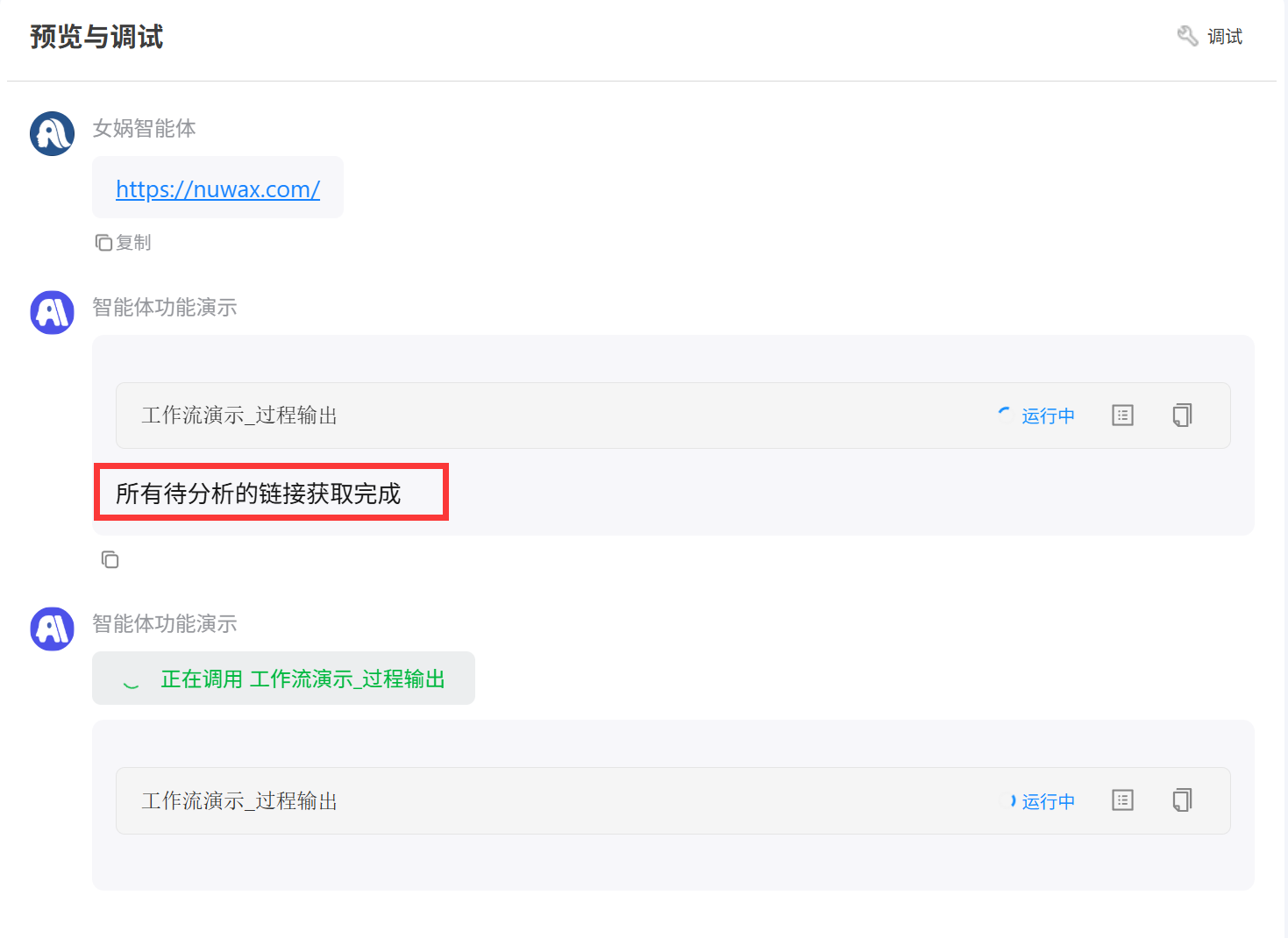 第二次过程输出会将大模型分析的结果进行多次输出展示
第二次过程输出会将大模型分析的结果进行多次输出展示 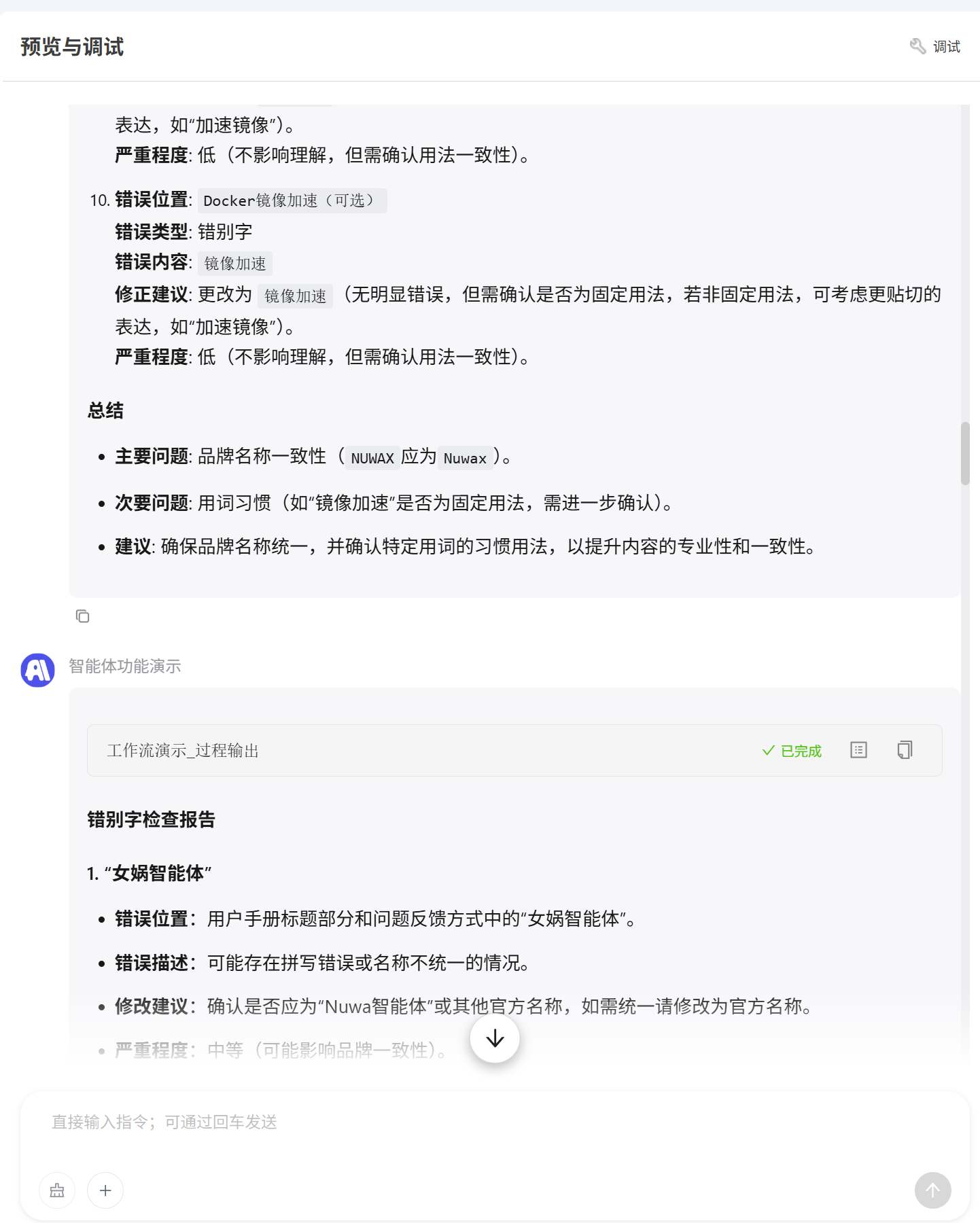 最后是总结所有页面的分析汇总形成一个网页报告
最后是总结所有页面的分析汇总形成一个网页报告